揭秘 Deep & Cross : 如何自动构造高阶交叉特征
本文介绍斯坦福与Google联合发表在AdKDD 2017上的论文《Deep & Cross Network for Ad Click Predictions》。这篇论文是Google 对 Wide & Deep工作的一个后续研究,文中提出 Deep & Cross Network,将Wide部分替换为由特殊网络结构实现的Cross,自动构造有限高阶的交叉特征,并学习对应权重,告别了繁琐的人工叉乘。文章发表后业界就有一些公司效仿此结构并应用于自身业务,成为其模型更新迭代中的一环。感兴趣的读者也可以观看 作者对Deep & Cross的Oral视频。
这里也简单介绍一下AdKDD
AdKDD是SIGKDD在Computational Advertising领域的一个workshop,从2007年举办至今,发表了很多Ad领域的经典工作,例如2013年Facebook的GBDT+LR。总体来说,这个workshop能够较好地反映这个行业的巨头们在Ad方向上的关注和研发重点,发表的工作实用性很强。
一、Motivation
针对大规模稀疏特征的点击率预估问题,Google在2016年提出 Wide & Deep 的结构来同时实现Memorization与Generalization(前面介绍过该文,感兴趣的读者可参见 详解 Wide & Deep 结构背后的动机)。但是在Wide部分,仍然需要人工地设计特征叉乘。面对高维稀疏的特征空间、大量的可组合方式,基于人工先验知识虽然可以缓解一部分压力,但仍需要不小的人力和尝试成本,并且很有可能遗漏一些重要的交叉特征。FM可以自动组合特征,但也仅限于二阶叉乘。能否告别人工组合特征,并且自动学习高阶的特征组合呢?Deep & Cross 即是对此的一个尝试。
二、Model
类似Wide & Deep,Deep & Cross的网络结构如图1所示,可以仔细观察下:
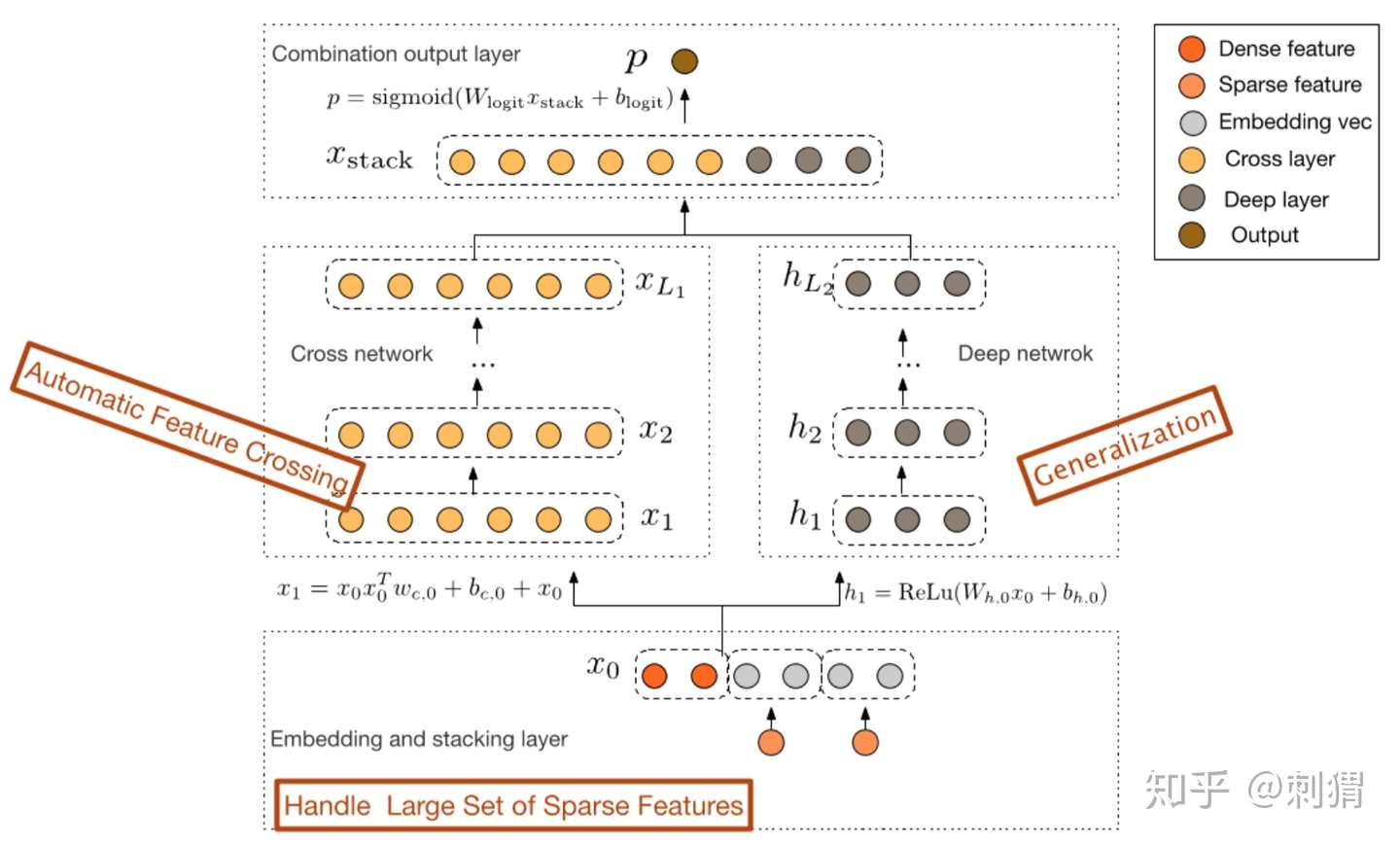 图1. Deep & Cross 的网络结构
图1. Deep & Cross 的网络结构
文中对原始特征做如下处理:1) 对sparse特征进行embedding,对于multi-hot的sparse特征,embedding之后再做一个简单的average pooling;2) 对dense特征归一化,然后和embedding特征拼接,作为随后Cross层与Deep层的共同输入,即:
Cross Layer
Cross的目的是以一种显示、可控且高效的方式,自动构造有限高阶交叉特征,我们会对这些特点进行解读。Cross结构如上图1左侧所示,其中第 层输出为:
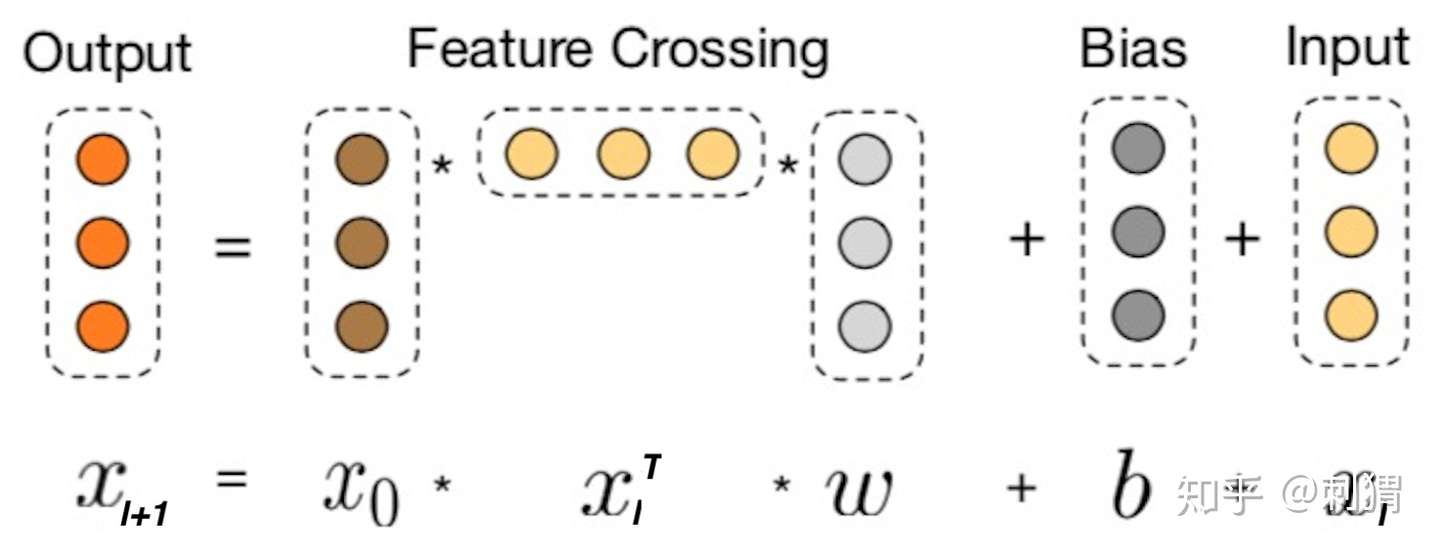
其中
Cross Layer 设计的巧妙之处全部体现在上面的计算公式中,我们先看一些明显的细节:1) 每层的神经元个数都相同,都等于输入 的维度
,也即每层的输入输出维度都是相等的;2) 受残差网络(Residual Network)结构启发,每层的函数
拟合的是
的残差,残差网络有很多优点,其中一点是处理梯度消失的问题,使网络可以“更深”.
那么为什么这样设计呢?Cross究竟做了什么?对此论文中给出了定理3.1以及相关证明,但定理与证明过程都比较晦涩,为了直观清晰地讲解清楚,我们直接看一个具体的例子:假设Cross有2层, ,为便于讨论令各层
,则
最后得到 参与到最后的loss计算。可以看到
包含了原始特征
从一阶到二阶的所有可能叉乘组合,而
包含了其从一阶到三阶的所有可能叉乘组合。现在大家应该可以理解cross layer计算公式的用心良苦了,上面这个例子也可以帮助我们更深入地理解Cross的设计:
1) 有限高阶:叉乘阶数由网络深度决定,深度 对应最高
阶的叉乘
2) 自动叉乘:Cross输出包含了原始特征从一阶(即本身)到 阶的所有叉乘组合,而模型参数量仅仅随输入维度成线性增长:
3) 参数共享:不同叉乘项对应的权重不同,但并非每个叉乘组合对应独立的权重(指数数量级), 通过参数共享,Cross有效降低了参数量。此外,参数共享还使得模型有更强的泛化性和鲁棒性。例如,如果独立训练权重,当训练集中 这个叉乘特征没有出现 ,对应权重肯定是零,而参数共享则不会,类似地,数据集中的一些噪声可以由大部分正常样本来纠正权重参数的学习
这里有一点很值得留意,前面介绍过,文中将dense特征和embedding特征拼接后作为Cross层和Deep层的共同输入。这对于Deep层是合理的,但我们知道人工交叉特征基本是对原始sparse特征进行叉乘,那为何不直接用原始sparse特征作为Cross的输入呢?联系这里介绍的Cross设计,每层layer的节点数都与Cross的输入维度一致的,直接使用大规模高维的sparse特征作为输入,会导致极大地增加Cross的参数量。当然,可以畅想一下,其实直接拿原始sparse特征喂给Cross层,才是论文真正宣称的“省去人工叉乘”的更完美实现,但是现实条件不太允许。所以将高维sparse特征转化为低维的embedding,再喂给Cross,实则是一种trade-off的可行选择。
- 联合训练
模型的Deep 部分如图1右侧部分所示,DCN拼接Cross 和Deep的输出,采用logistic loss作为损失函数,进行联合训练,这些细节与Wide & Deep几乎是一致的,在这里不再展开论述。另外,文中也在目标函数中加入L2正则防止过拟合。
- 模型分析
设初始输入 维度为
,Deep和Cross层数分别为
和
,为便于分析,设Deep每层神经元个数为
,则两部分的参数量为:
Cross:
Deep:
可以看到Cross的参数量随 增大仅呈“线性增长”!相比于Deep部分,对整体模型的复杂度影响不大,这得益于Cross的特殊网络设计,对于模型在业界落地并实际上线来说,这是一个相当诱人的特点。
三、Experiment
数据集
文中在公开的CTR预估数据集 Criteo Display Ads上进行实验,Criteo有13个integer特征,26个categorical特征且每个category都有大量的类别值。Criteo含有7天的用户日志,共11GB,取前6天作训练集(约41 milion样本),第7天随机划分为验证集和测试集。对这个数据集来说,0.001的logloss改进也被认为是非常显著的提升。
实验设置
- 每个categorical特征嵌入维度为:
;
- 使用mini-batch随机优化且batch大小设为512,选择Adam优化器,使用Batch Normalization且对应的gradient clip norm设为100。作者实验中发现L2正则和Dropout的效果都不好,所以使用early stop防止过拟合,early stop的training step为150,000;
- 使用网格搜索寻找最优参数,Deep深度:2~5,神经元个数:32~1024,Cross深度:1~6,学习率:
~
,这些参数范围也是作者对Criteo的实验中得到的经验,例如作者发现学习率超过
对比方法 文中选择DNN,LR,FM与Deep Cross(DC)作为对比方法,其中DNN可看作将DCN去除Cross部分,LR使用所有稀疏特征(dense特征会被离散化)与部分精选交叉特征。
实验结果 实验结果如下表,DCN不但效果明显最优,而且相比之下仅用了DNN的40%内存。

作者进一步对比了DCN与DNN在memory占用和效果上的差异,实验结果如下两表所示。为达到同样性能,DCN所需的参数量显著更少;此外,随着参数量的上升,DNN与DCN的差距在减小,但DCN仍稳定占优。相比DNN,Cross可以辅助Deep,减小了Deep的“工作量”,通过特殊的cross layer设计,用更少的参数量有效捕获有意义的、DNN难以捕捉的特征相关性。


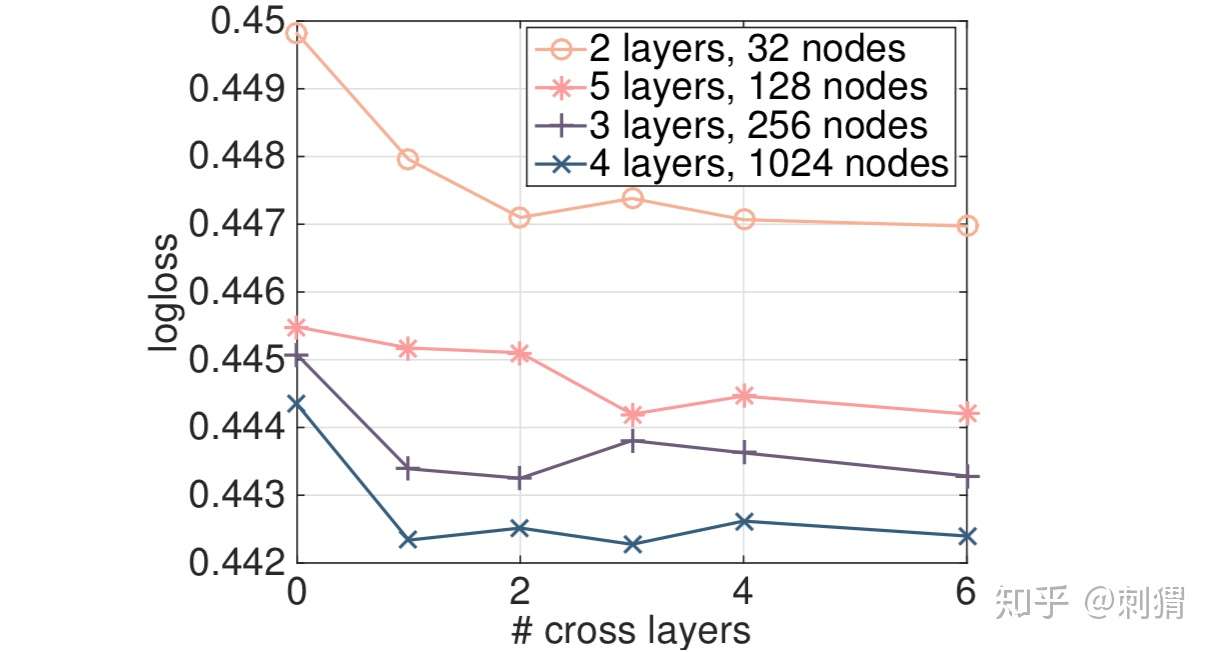
文中也在两个Non-CTR数据集——Forest Covertype和Higgs上进行了实验,这是UCI上的公开数据集,结果类似,DCN最优。此外,文中也对cross层数进行了实验,实验显示cross层并非越多越好,具体结果如下图:
实验部分不足的地方是只进行了离线测试,与其他落地性很强的业界paper相比,没有一个online test,没有给出更具说服力的实验指标AUC或GAUC,也没有对比Wide & Deep。
四、Conclusion
1. 论文提出一种新型的交叉网络结构 DCN,其中 Cross 可以显示、自动地构造有限高阶的特征叉乘,从而在一定程度上告别人工特征叉乘,说一定程度是因为文中出于模型复杂度的考虑,仍是仅对sparse特征对应的embedding作自动叉乘,但这仍是一个有益的创新
2. Cross部分的复杂度与输入维度呈线性关系,相比DNN非常节约内存。实验结果显示了DCN的有效性,DCN用更少的参数取得比DNN更好的效果
文章被以下专栏收录
推荐阅读
xDeepFM:名副其实的 ”Deep” Factorization Machine
今天介绍 中科大、北大 与 微软 合作发表在 KDD’18 的文章《xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems》。Paper写得很流畅,还清晰梳理了F…
详解 Wide & Deep 结构背后的动机
本文介绍 Google 发表在 DLRS 2016 上的文章《Wide & Deep Learning for Recommender System》。Wide & Deep 模型的核心思想是结合线性模型的记忆能力和 DNN 模型的泛化能力,从而…
速览 DeepFM: 使用 FM 取代 Wide & Deep 中的 LR
本文介绍 华为诺亚方舟Lab 与 哈工大 发表在 IJCAI 2017 的论文《DeepFM: A Factorization-Machine based Neural Network for CTR Prediction》。DeepFM结构非常简单,在Wide & Deep结…
![[深度模型] xDeepFM: DeepFM和Deep Cross Network大升级](https://pic3.zhimg.com/v2-8b47e49c856834e7c9413e61d7abb7b4_250x0.jpg?source=172ae18b)
21 条评论
赞哈!原来后面还有这样的故事,这么一说,倒是解答了之前感觉论文里的定理部分有点晦涩并且总感觉实验部分有点儿不太严谨的困惑
不知道现在在arxiv的论文里面结构图还有没有问题
请问一下效果如何?
组里尝试后没有提升,不知道其他公司有没有实际应用的
与哪个base对比没有提升,是离线对比就没有提升吗
我们当时对比标准的wide&deep
这里是输入层的参数量,w和bias
是包含了很多组合特征,各列在做加权求和的时候权重是一样的,最后特征都加在了一起,输出的向量中这还能体现出各种组合特征吗。
输出向量的元素本身已经是各阶特征叉乘的加权组合值
xdeepfm文章里不是说它这个学出来只能是x的倍数
公式里的b是不是少了一个下标l
谢谢指正
deep这边已经有高阶特征组合,为什么wide还要做?
原文中看见:we combine the explicit high-order interaction module with implicit interac- tion module and traditional FM module, Deep 部分的组合是黑盒,不知道怎么做的。但是Wide 是我们设计的,是显示的,还有就是文中作者一直提到的 bit-wise (deep部分)和 vector-wise(wide部分) *两种方式*去构建组合特征吧。
cross layer那部分内容,举例解释如何做cross的地方,x2的计算有点问题
已修,谢谢指正