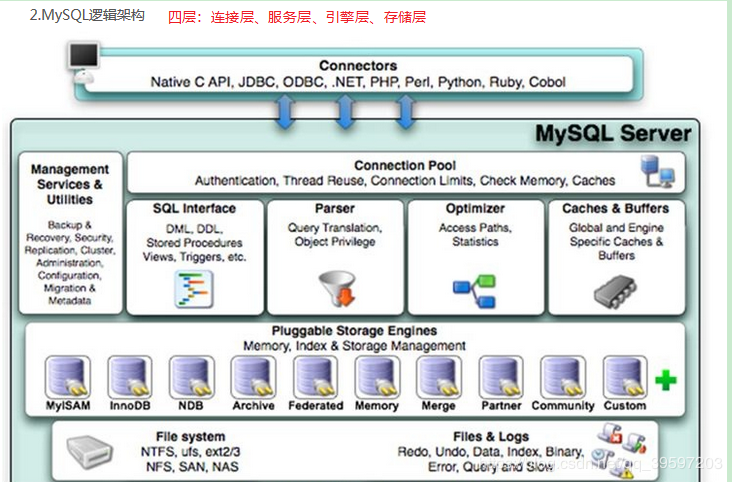
整体架构
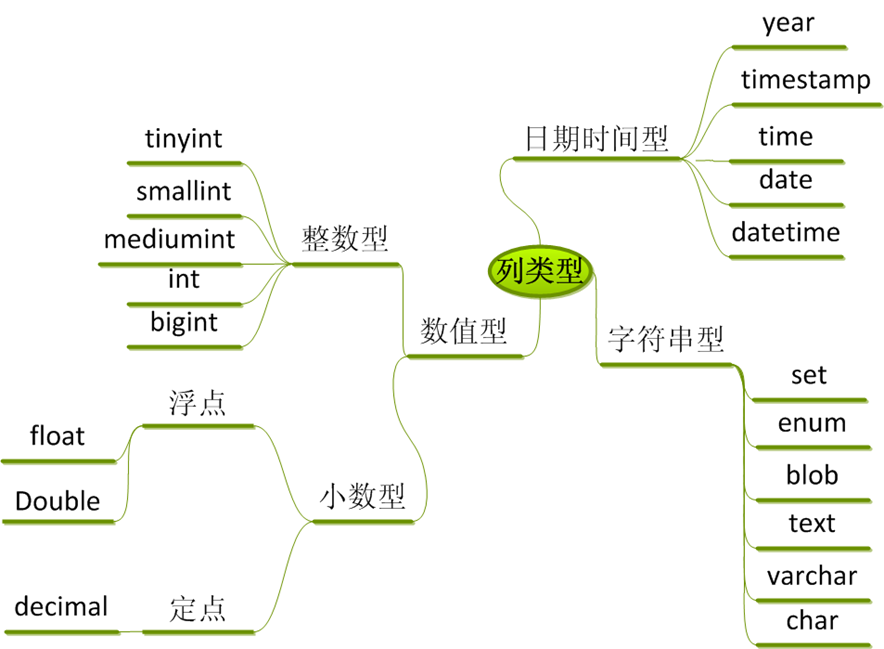
数据类型
- 文本类:CHAR、VARCHAR(可变长度字符,多使用)、TEXT、LONGTEXT(文本较大时使用)
- 数字类:TINYINT、INT、BIGINT、FLOAT、DOUBLE
- 日期类:DATE、DATETIME(常用)、TIME、YEAR
保留字
- SELECT:选择列
- WHERE:过滤行
- AS:起别名
- HAVING:过滤分组
- GROUP BY:分组说明
- ORDER BY:排序顺序
常用操作
- 查看当前有哪些DB:show databases;
- 添加DB:create database gc;
- 删除DB:drop database gc;
- 进入DB:use gc;
- 创建数据表:create table gc(...);
- 增加列:alter talbe account add c1 int
- 查看表:show tables;
- 显示表内容:select * from table;


案例
- 供应商表:Vendors
- 商品表:Products
- 顾客表:Customers
- 订单表:Orders
- 订单物品表:OrderItems






检索数据
- 检索一列
- SELECT col1,col2 FROM table;
- 检索所有列
- SELECT * FROM table;
- 检索一列(显示不同值)
- SELECT DISTINCT col FROM table;
- 检索一列(显示前3行)
- SELECT col FROM table LIMIT 3;
排序
- 对选定的列以字母顺序排序
- SELECT col FROM table ORDER BY col
过滤
- 检索两个列,返回特定值的行
- SELECT col1, col2 FROM table WHERE col = 1;
- 检索两个列,返回不等于特定值的行
- SELECT col1, col2 FROM table WHERE col <> 1;
- 检索两个列,返回特定范围值的行
- SELECT col1, col2 FROM table WHERE col BETWEEN 5 AND 10;
函数
- 使用函数
- UPPER():将字符串转为大写
- LTRIM():去掉字符串左边空格
- LENGTH():返回字符串的长度
- 聚集函数
- ABS(col):返回某列数的绝对值
- AVG(col):返回某列的平均值
- COUNT(col):返回某列有值的行的个数
- MAX(col)/MIN(col):返回某列最大/最小值
- SUM(col):返回某列值之和
分组
- 使用BROUP BY子句,指示DBMS按某字段排序并分组数据
- 返回供应商1001提供的产品数目
- SELECT COUNT(*) AS num_prods FROM Products
- WHERE vend_id = '1001';
- 统计所有供应商的产品数目
- SELECT vend_id, COUNT(*) AS num_prods FROM Products
- GROUP BY vend_id;
- 统计所有产品数目>2的供应商
- SELECT vend_id, COUNT(*) AS num_prods FROM Products
- GROUP BY vend_id HAVING mum_prods > 2;



子查询
- 列出订购物品FB的所有顾客
- SELECT cust_id FROM Orders WHERE order_num IN
- (SELECT order_num FROM OrderItems WHERE prod_id = 'FB');
- 思路:先到订单物品表中找出包含FB的所有订单号,然后再到订单表中找出是谁下的单,返回用户id
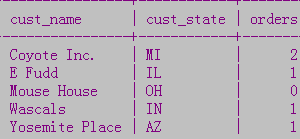
- 显示Customers表中每个顾客的订单总数
- SELECT cust_name, cust_state, (SELECT COUNT(*) FROM Orders
- WHERE Orders.cust_id = Customers.cust_id) AS orders
- FROM Customers ORDER BY Cust_name;
- 思路:从Customers表中检索顾客列表,对于检索出的每个顾客,统计其在Orders表中的订单数目
- 原理:在子查询中,对于Orders表中cust_id等于Customers表中cust_id的行,统计其行数,并将该列命名为orders返回
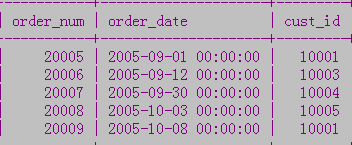
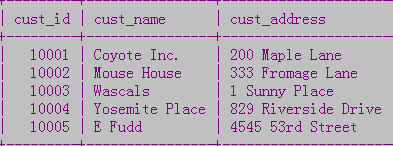 ...
...
联结表
- 联结的三种形式
- 内联结(inner join):联结具有相同字段的另一个表,可基于两个表之间的等值条件做过滤
- 自联结(self join):同一个表联结自己的副本,用于表内信息筛选,比子查询效率高
- 外联结(outer join):联结具有相同字段的另一个表,可基于两个表之间的等值条件做过滤,返回包括在相关表中没有关联行的行
- 联结的原理
- 关系数据库数据表的设计原则是相同的数据不出现多次,这样可以保证较强的可伸缩性(scale,即适应不断增加的数据量)
- 故数据常存储在多个表中,这时就需要使用联结机制将结果输出
- 联结两个表时,会将第一个表中的每一行与第二个表中的每一行配对,即返回笛卡尔积,而不管逻辑上是否匹配
- 加上WHERE作为过滤条件,会删除不符合逻辑的行,只返回包含匹配给定条件(联结条件)的行
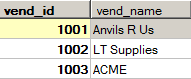
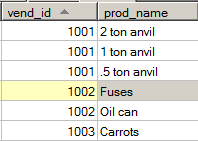
- 例1(内连接):返回包含vend_name、prod_name、prod_price的新表(即把产品表中的vend_id换成vend_name,看起来更加直观)
- SELECT vend_name, prod_name, prod_price
- FROM Vendors, Products
- WHERE Vendors.vend_id = Products.vend_id;
- 或:
- SELECT vend_name, prod_name, prod_price
- FROM Vendors INNER JOIN Products
- ON Vendors.vend_id = Products.vend_id;

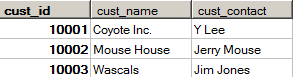
- 例2(自联结):找出和Y Sam在同一个公司的所有顾客,并返回相关信息(显示某一cust_name下的所有cust_contact)
- SELECT c1.cust_id, c1.cust_name, c1.cust_contact
- FROM Customers AS c1, Customers As c2
- WHERE c1.cust_name = c2.cust_name
- AND c2.cust_name = 'Y Sam';
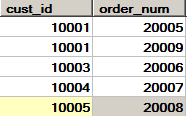
- 例3(外联结):对每个顾客下的订单进行统计,包括未下单的顾客(返回cust_id和order_num两列,)
- select customers.cust_id,orders.order_num
- from customers left outer join orders
- on customers.cust_id = orders.cust_id;

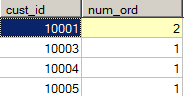
- 例4(带内联函数的联结):检索所有顾客及每个顾客下的订单数
- select customers.cust_id , count(orders.order_num) as num_ord
- from customers inner join orders on customers.cust_id = orders.cust_id
- group by customers.cust_id;
- 其中,count(orders.order_num) 实现了对每个顾客的订单计数
组合查询
- 利用UNION,将多个SELECT语句组成一个结果集
- UNION中的每个查询必须包含相同的列、表达式或聚集函数
- UNION从查询结果中自动去除了重复的行(不去重就用UNION ALL)
插入数据
- INSERT
- 插入所有行
- INSERT INTO Customers VALUES(
- '1000006', 'TONY', ... , NULL) ;
- 插入部分行
- INSERT INTO Customers (cust_id,cust_name)
- VALUES('1000006', 'TONY');
- 插入索引出的数据
- INSERT INTO Customers (cust_id,cust_name,...)
- SELECT cust_id,cust_name,... FROM CustNew;
- 从一个表复制到另一个表(创建新表CustCopy,将Customers内容复制进去)
- SELECT TABLE CustCopy AS SELECT * FROM Customers;
更新删除
- UPDATE:更新表中的行
- 例:将 cust_id = 1000005 行的邮箱信息更新为 kim@thetoystore.com
- UPDATE Customers SET cust_email = 'kim@thetoystore.com'
- WHERE cust_id = '1000005';
- 注:SET后可设置多个字段的值,不加WHERE将更新素有行
- DELETE:删除某行
- 例:将 cust_id = 1000006 行删除
- DELETE FROM Customers
- WHERE cust_id = '1000006';
- 注:不加WHERE将删除所有行
创建表
- CREATE:创建新表
- CREATE TABLE Products(
- prod_id CHAR(10) NOT NULL,
- vend_id CHAR(10) NOT NULL,
- prod_name CHAR(254) NOT NULL,
- );
- ALERT:更新表
- 增加一列
- ALERT TABLE Vendors
- ADD vend_phone CHAR(20);
- DROP:删除表
- DROP TABLE CustCopy;
工具
- MySQL-Front:一款数据库管理工具
参考
Hive和Mysql的区别
https://blog.csdn.net/qq_39597203/article/details/89481867?
https://blog.csdn.net/qq_28652401/article/details/83509636?
partition
https://www.cnblogs.com/tfiremeteor/p/6296599.html
https://www.cnblogs.com/SmileIven/p/9133548.html
开窗函数