列表(list)
- 动态,长度大小不固定,可随意增、删、改元素(链表)
- 可放置任意数据类型
- 支持负数索引,切片操作


1 t = timeit.timeit(stmt="x=[1,2,3,4,5,6]", number=100000) 2 print(t)
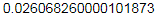
元组(tuple)
- 静态,长度大小固定,无法增、删、改元素(数组)
- 可放置任意数据类型
- 支持负数索引,切片操作
1 t = timeit.timeit(stmt="x=(1,2,3,4,5,6)", number=100000) 2 print(t)
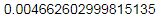
字典(dict)
- 由键--值对组成的有序元素的集合(哈希表)
- 键不可变,不重复
- 查找、添加、删除操作复杂度O(1)
- 底层哈希表中存储哈希值、键、值三个元素
1 d = {'b':1,'a':2,'c':10} 2 d_sorted_by_key = sorted(d.items(),key=lambda x:x[0]) 3 d_sorted_by_value = sorted(d.items(),key=lambda x:x[1]) 4 d_sorted_by_key 5 d_sorted_by_value
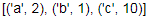
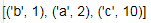
集合(set)
- 无序元素的集合(哈希表)
- 元素不可变,不重复
- 查找、添加、删除操作复杂度O(1)
- 底层哈希表中存储哈希值、键、值三个元素
1 import time 2 3 def find_unique_price_using_set(products): 4 unique_price_set = set() 5 for _, price in products: 6 unique_price_set.add(price) 7 return len(unique_price_set) 8 9 def find_unique_price_using_list(products): 10 unique_price_list = [] 11 for _, price in products: 12 if price not in unique_price_list: 13 unique_price_list.append(price) 14 return len(unique_price_list) 15 16 id = [x for x in range(0,10000)] 17 price = [x for x in range(20000, 30000)] 18 products = list(zip(id,price)) 19 20 start_using_list = time.perf_counter() 21 find_unique_price_using_list(products) 22 end_using_list = time.perf_counter() 23 print("time elapse using list:{}".format(end_using_list - start_using_list)) 24 25 start_using_list = time.perf_counter() 26 find_unique_price_using_set(products) 27 end_using_list = time.perf_counter() 28 print("time elapse using set:{}".format(end_using_list - start_using_list))

字符串(string)
- 不可变,改变字符串就要创建新的字符串
- 分割
1 def query_data(namespace, table): 2 print("data in " + table + " at " + namespace) 3 4 path = 'hive://ads/traning_table' 5 namespace = path.split('//')[1].split('/')[0] 6 table = path.split('//')[1].split('/')[1] 7 data = query_data(namespace,table)
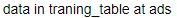
- 格式化输出
1 name = input('your name:') 2 gender = input('you are a boy?(y/n)') 3 4 welcome_str = 'Welcome to the matrix {prefix}{name}.' 5 welcome_dic = { 6 'prefix' : 'Mr. ' if gender == 'y' else 'Mrs. ', 7 'name' : name 8 } 9 10 print('authorizing...') 11 print(welcome_str.format(**welcome_dic))
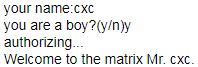
- 数据清洗
1 import re 2 3 def parse(text): 4 # 去除标点符号和换行符 5 text = re.sub(r'[^w]',' ',text) 6 # 转为小写 7 text = text.lower() 8 # 生成所有单词的列表 9 word_list = text.split(' ') 10 # 去除空白单词 11 word_list = filter(None, word_list) 12 # 生成单词和词频的字典 13 word_cnt = {} 14 for word in word_list: 15 if(word not in word_cnt): 16 word_cnt[word] = 0; 17 word_cnt[word] += 1 18 #按词频倒序排序 19 sorted_word_cnt = sorted(word_cnt.items(),key=lambda kv:kv[1],reverse=True) 20 return sorted_word_cnt 21 22 with open('in.txt','r') as fin: 23 text = fin.read() 24 25 word_and_freq = parse(text) 26 27 with open('out.txt','w') as fout: 28 for word, freq in word_and_freq: 29 fout.write('{} {} '.format(word,freq))
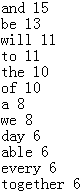 ...(输入为马丁路德金的《I have a dream》)
...(输入为马丁路德金的《I have a dream》)
- json
- dumps():打包(序列化),字典->字符串
- loads():解包(反序列化),字符串->字典
1 import json 2 3 params = { 4 'symbol':'123456', 5 'type':'limit', 6 'price':123.4, 7 'amount':23 8 } 9 10 params_str = json.dumps(params) 11 print('after json serialization') 12 print('type of params_str = {}, params_str = {}'.format(type(params_str),params_str)) 13 14 original_params = json.loads(params_str) 15 print('after json deserialization') 16 print('type of original_params = {}, original_params={}'.format(type(original_params),original_params))
