1.问题描述
已知[k,k+n)时刻的正弦函数,预测[k+t,k+n+t)时刻的正弦曲线。
因为每个时刻曲线上的点是一个值,即feature_len=1,如果给出50个时刻的点,即seq_len=50,如果只提供一条曲线供输入,即batch=1。输入的shape=[seq_len, batch, feature_len] = [50, 1, 1]。
2.代码实现
1 import numpy as np 2 import torch 3 import torch.nn as nn 4 import torch.optim as optim 5 from matplotlib import pyplot as plt 6 7 8 input_size = 1 9 hidden_size = 16 10 output_size = 1 11 12 13 class Net(nn.Module): 14 15 def __init__(self, ): 16 super(Net, self).__init__() 17 18 self.rnn = nn.RNN( 19 input_size=input_size, #feature_len=1 20 hidden_size=hidden_size, #隐藏记忆单元尺寸hidden_len 21 num_layers=1, #层数 22 batch_first=True, #在传入数据时,按照[batch,seq_len,feature_len]的格式 23 ) 24 for p in self.rnn.parameters(): #对RNN层的参数做初始化 25 nn.init.normal_(p, mean=0.0, std=0.001) 26 27 self.linear = nn.Linear(hidden_size, output_size) #输出层 28 29 30 def forward(self, x, hidden_prev): 31 ''' 32 x:一次性输入所有样本所有时刻的值(batch,seq_len,feature_len) 33 hidden_prev:第一个时刻空间上所有层的记忆单元(batch,num_layer,hidden_len) 34 输出out(batch,seq_len,hidden_len)和hidden_prev(batch,num_layer,hidden_len) 35 ''' 36 out, hidden_prev = self.rnn(x, hidden_prev) 37 #因为要把输出传给线性层处理,这里将batch和seq_len维度打平,再把batch=1添加到最前面的维度(为了和y做MSE) 38 out = out.view(-1, hidden_size) #[batch=1,seq_len,hidden_len]->[seq_len,hidden_len] 39 out = self.linear(out) #[seq_len,hidden_len]->[seq_len,feature_len=1] 40 out = out.unsqueeze(dim=0) #[seq_len,feature_len=1]->[batch=1,seq_len,feature_len=1] 41 return out, hidden_prev 42 43 44 #训练过程 45 lr=0.01 46 47 model = Net() 48 criterion = nn.MSELoss() 49 optimizer = optim.Adam(model.parameters(), lr) 50 51 hidden_prev = torch.zeros(1, 1, hidden_size) #初始化记忆单元h0[batch,num_layer,hidden_len] 52 num_time_steps = 50 #区间内取多少样本点 53 54 for iter in range(6000): 55 start = np.random.randint(3, size=1)[0] #在0~3之间随机取开始的时刻点 56 time_steps = np.linspace(start, start + 10, num_time_steps) #在[start,start+10]区间均匀地取num_points个点 57 data = np.sin(time_steps) 58 data = data.reshape(num_time_steps, 1) #[num_time_steps,]->[num_points,1] 59 x = torch.tensor(data[:-1]).float().view(1, num_time_steps - 1, 1) #输入前49个点(seq_len=49),即下标0~48[batch, seq_len, feature_len] 60 y = torch.tensor(data[1:]).float().view(1, num_time_steps - 1, 1) #预测后49个点,即下标1~49 61 #以上步骤生成(x,y)数据对 62 63 output, hidden_prev = model(x, hidden_prev) #喂入模型得到输出 64 hidden_prev = hidden_prev.detach() 65 66 loss = criterion(output, y) #计算MSE损失 67 model.zero_grad() 68 loss.backward() 69 optimizer.step() 70 71 if iter % 1000 == 0: 72 print("Iteration: {} loss {}".format(iter, loss.item())) 73 74 75 #测试过程 76 #先用同样的方式生成一组数据x,y 77 start = np.random.randint(3, size=1)[0] 78 time_steps = np.linspace(start, start + 10, num_time_steps) 79 data = np.sin(time_steps) 80 data = data.reshape(num_time_steps, 1) 81 x = torch.tensor(data[:-1]).float().view(1, num_time_steps - 1, 1) 82 y = torch.tensor(data[1:]).float().view(1, num_time_steps - 1, 1) 83 84 predictions = [] 85 86 input = x[:, 0, :] #取seq_len里面第0号数据 87 input = input.view(1, 1, 1) #input:[1,1,1] 88 for _ in range(x.shape[1]): #迭代seq_len次 89 90 pred, hidden_prev = model(input, hidden_prev) 91 input = pred #预测出的(下一个点的)序列pred当成输入(或者直接写成input, hidden_prev = model(input, hidden_prev)) 92 predictions.append(pred.detach().numpy().ravel()[0]) 93 94 95 x = x.data.numpy() 96 y = y.data.numpy() 97 plt.plot(time_steps[:-1], x.ravel()) 98 99 plt.scatter(time_steps[:-1], x.ravel(), c='r') #x值 100 plt.scatter(time_steps[1:], y.ravel(), c='y') #y值 101 plt.scatter(time_steps[1:], predictions, c='b') #y的预测值 102 plt.show()
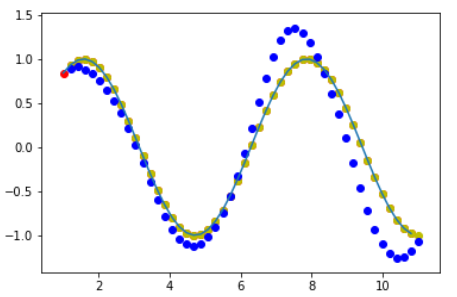
Iteration: 0 loss 0.4788994789123535
Iteration: 1000 loss 0.0007066279067657888
Iteration: 2000 loss 0.0002824284601956606
Iteration: 3000 loss 0.0006475357222370803
Iteration: 4000 loss 0.00019797398999799043
Iteration: 5000 loss 0.00011313191498629749
3.梯度裁剪
如果发生梯度爆炸,在上面67~69行之间要进行梯度裁剪:
1 model.zero_grad() 2 loss.backward() 3 for p in model.parameters(): 4 # print(p.grad.norm()) #查看参数p的梯度 5 torch.nn.utils.clip_grad_norm_(p, 10) #将梯度裁剪到小于10 6 optimizer.step()