转自:https://blog.csdn.net/davion_zhang/article/details/51536807
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/fzs333/article/details/51536807
P1020网络底层收发探究
一、基本框架
简单看了一下p1020内核中,网络底层的数据收发
先看一下linux内核中网络的层次结构
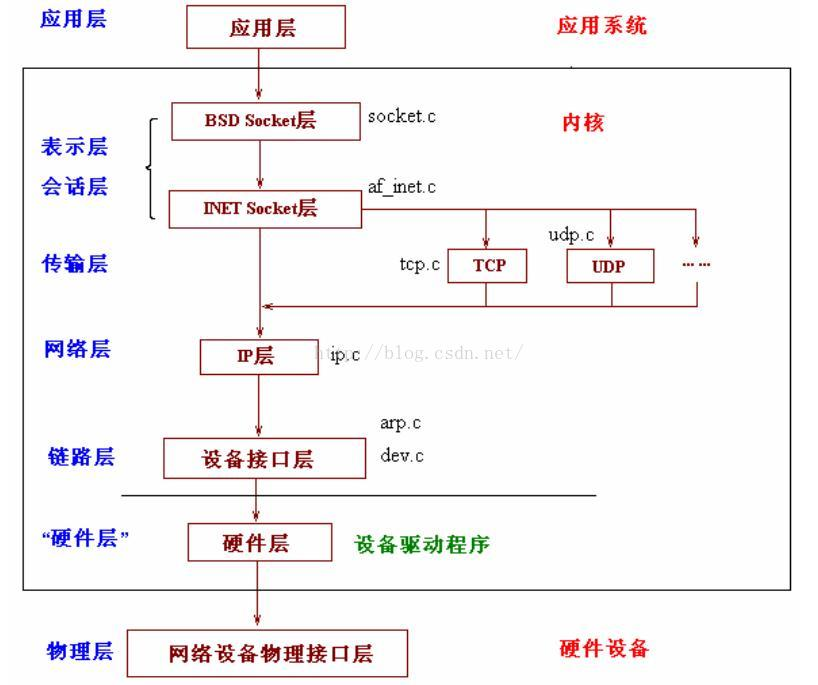
也是基本按照7层来构造
由于从ip层(网络层)往上就比较统一了,这里主要分析硬件层和链路层
二、名词解释
1.NAPI
CPU数据接收靠中断和轮询的配合,达到较高的收发效率。
CPU接收外部数据时一般采用中断的方式,中断的好处是响应及时,如果数据量较小,则不会占用太多的CPU事件;缺点是数据量大时,会产生过多中断,
而每个中断都要消耗不少的CPU时间,从而导致效率反而不如轮询高。轮询方式与中断方式相反,它更适合处理大量数据,因为每次轮询不需要消耗过多的CPU时间;缺点是即使只接收很少数据或不接收数据时,也要占用CPU时间。
NAPI是两者的结合,数据量低时采用中断,数据量高时采用轮询。平时是中断方式,当有数据到达时,会触发中断,处理函数会关闭中断开始处理。如果此时有数据到达,则没必要再触发中断了,因为中断处理函数会轮询处理数据,直到没有新数据时才打开中断。
很明显,数据量很低与很高时,NAPI可以发挥中断与轮询方式的优点,性能较好。
//如果数据量不稳定,且说高不高说低不低,则NAPI则会在两种方式切换上消耗不少时间,效率反而较低一些。
2.CPU私有变量
通过struct softnet_data __get_cpu_var(softnet_data)获取到的CPU的私有变量,硬中断中将数据挂上,软中断中取出来处理
三、驱动分析
P1020的物理层驱动(TSEC驱动)主要在/drivers/net/gianfar.c文件中
链路层驱动主要在/net/core/dev.c
1.初始化
gianfar.c函数gfar_probe执行了初始化的操作。比较重要的就是napi的注册,
调用函数netif_napi_add将gfar_poll注册进NAPI中
netif_napi_add(dev, &priv->gfargrp[i].napi, gfar_poll, GFAR_DEV_WEIGHT);
另一段比较重要的初始化在gfar_enet_open中,先来看一下gfar设备的文件操作符可以使用的函数
static const struct net_device_opsgfar_netdev_ops = {
.ndo_open= gfar_enet_open,
.ndo_start_xmit= gfar_start_xmit,
.ndo_stop= gfar_close,
.ndo_change_mtu= gfar_change_mtu,
.ndo_set_multicast_list= gfar_set_multi,
.ndo_tx_timeout= gfar_timeout,
.ndo_do_ioctl= gfar_ioctl,
.ndo_get_stats= gfar_get_stats,
.ndo_vlan_rx_register= gfar_vlan_rx_register,
.ndo_set_mac_address= eth_mac_addr,
.ndo_validate_addr= eth_validate_addr,
。。。
};
当通过IOCTL操作gfar这个网络设备时,调用gfar_enet_open函数执行初始化
static int gfar_enet_open(struct net_device*dev)
{
enable_napi(priv); //使能NAPI
gfar_set_mac_address(dev); //设置mac
err= init_phy(dev); //初始化phy
err= startup_gfar(dev); //…
netif_tx_start_all_queues(dev); //初始化队列
device_set_wakeup_enable(&priv->ofdev->dev,priv->wol_en);
。。。
}
其中startup_gfar又进行了一系列初始化,然后重要的来了
它调用了函数register_grp_irqs进行IRQ的注册
static int register_grp_irqs(structgfar_priv_grp *grp)
{
request_irq(grp->interruptError,gfar_error,0, grp->int_name_er,grp));
request_irq (grp->interruptTransmit,gfar_transmit, 0, grp->int_name_tx, grp);
request_irq(grp->interruptReceive,gfar_receive, 0, grp->int_name_rx, grp);
request_irq (grp->interruptTransmit,gfar_interrupt,0, grp->int_name_tx, grp));
}
收发报文的中断已经注册好,初始化细节不再扣,主要看看报文的流向
2.报文流向——报文接收
(1).简析
网络数据包进入内核的流程为:
Rj45网口à PHY --> MII à TSEC的DMA Engine à把网络数据包 DMA 到内存
à完整报文触发Rx IRQ à gfar_receiveà net_rx_action ànetif_receive_skb这里就是协议栈了
前面DMA部分配置好后,收到的数据报文会自动搬移到内存中,产生中断后,中断处理会到指定的地址寻找,后续再分析DMA部分的细节,下面是比较重要的处理函数解释。
IRQ处理函数:
gfar_receive
1.关闭RX中断 //这里是NAPI的重点,关闭中断,后续到来的数据不会产生中断
2.置NAPI_STATE_SCHED状态
3.将napi_struct挂到CPU私有变量表上 //报文DMA后的内存地址等,中断下半段处理报文
4.触发软中断
软中断处理函数:
net_rx_action
1.遍历CPU私有变量表,取出napi_struct结构
2.执行napi_struct上的poll函数,循环处理DMA到内存的数据包 //前面中断关闭了,poll函数会遍历所有地址查找数据包,也就是轮询模式
3.若数据包处理完或达到netdev_max_backlog个报文则开RX中断 //数据包处理完或达到这个阈值(一般为300)就会结束轮询,重新进入中断模式
4.调用napi_complete函数将napi_struct结构从CPU私有变量移走并去掉NAPI_STATE_SCHED状态
(2).代码详细
直接从gfar_receive入手
硬中断部分
gfar_receive
à gfar_write(&grp->regs->ievent,IEVENT_RX_MASK); //关闭收中断
à napi_schedule_prep //置NAPI_STATE_SCHED状态
à__napi_schedule(&grp->napi);
à____napi_schedule(&__get_cpu_var(softnet_data), n); //将napi_struct挂到cpu var上
à__raise_softirq_irqoff(NET_RX_SOFTIRQ); //触发软中断
具体分析
gfar_receive
{
/*
* Clear IEVENT, so interrupts aren't calledagain
* because of the packets that have alreadyarrived.
*/
gfar_write(&grp->regs->ievent,IEVENT_RX_MASK); //关闭收中断
if(napi_schedule_prep(&grp->napi)) { //见下
tempval= gfar_read(&grp->regs->imask);
tempval&= IMASK_RX_DISABLED;
gfar_write(&grp->regs->imask, tempval); //关RX mask
__napi_schedule(&grp->napi); //见下
…
}
static inline int napi_schedule_prep(structnapi_struct *n)
{
return!napi_disable_pending(n) &&
!test_and_set_bit(NAPI_STATE_SCHED,&n->state); //置NAPI_STATE_SCHED状态
}
void __napi_schedule(structnapi_struct *n)
{
local_irq_save(flags);
____napi_schedule(&__get_cpu_var(softnet_data),n); //将napi_struct挂到cpu var上,详见下面
local_irq_restore(flags);
}
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi)
{
list_add_tail(&napi->poll_list,&sd->poll_list); //挂变量
__raise_softirq_irqoff(NET_RX_SOFTIRQ); //触发软中断
}
软中断部分
net_rx_action
àwork = n->poll(n, weight);
àgfar_clean_rx_ring //遍历内存数据包地址,获取报文
àgfar_process_frame //对报文进行校验和以太网类型判断
ànetif_receive_skb //Send the packet up to the stack
ànext_bd //下一条报文
ànapi_complete(n); //轮询完成,恢复中断
具体分析
net_rx_action
{
structsoftnet_data *sd = &__get_cpu_var(softnet_data); //获取CPU私有变量
while(!list_empty(&sd->poll_list)) { //遍历poll_list
if(test_bit(NAPI_STATE_SCHED, &n->state)) {
work =n->poll(n, weight); //执行驱动POLL方法,见下
trace_napi_poll(n);
}
}
}
关于这个POLL方法,是否还记得初始化时注册的gfar_poll ? 就是这个函数
gfar_poll
{
while(num_queues && left_over_budget) {
rx_cleaned_per_queue= gfar_clean_rx_ring(rx_queue, //报文获取,详见下
budget_per_queue);
}
if(rx_cleaned < budget) { //判断当前处理的报文数量是否已经达到阈值,达到则关闭NAPI轮询模式,打开Rx中断
napi_complete(napi);
/* Clear the halt bit inRSTAT */
gfar_write(®s->rstat,gfargrp->rstat);
gfar_write(®s->imask,IMASK_DEFAULT);
}
}
gfar_clean_rx_ring
{
skb= rx_queue->rx_skbuff[rx_queue->skb_currx]; //获取报文
pkt_len= bdp->length - ETH_FCS_LEN; //去掉校验
/*Remove the FCS from the packet length */
skb_put(skb,pkt_len);
gfar_process_frame(dev, skb, amount_pull); //报文处理,详见下
/*Add another skb for the future */
newskb= gfar_new_skb(dev); //为下一条报文分配空间
/*Setup the new bdp */
gfar_new_rxbdp(rx_queue,bdp, newskb); //DMA报文内存地址NEXT
/*Update to the next pointer */
bdp= next_bd(bdp, base, rx_queue->rx_ring_size);
}
gfar_process_frame
{
if (priv->rx_csum_enable) //报文校验
gfar_rx_checksum(skb,fcb);
/*Tell the skb what kind of packet this is */
skb->protocol= eth_type_trans(skb, dev); //获取以太网类型
/*Send the packet up the stack */
if(unlikely(priv->vlgrp && (fcb->flags & RXFCB_VLN)))
ret= vlan_hwaccel_receive_skb(skb, priv->vlgrp, fcb->vlctl);
else
ret =netif_receive_skb(skb); //发送到上层协议栈
}
到上层协议栈基本就告别了P1020的TSEC驱动部分
以前的平台就在netif_receive_skb里面添加了一些协议报文的处理,以后也可以继续添加
http://blog.csdn.net/davion_zhang/article/details/50418425
---------------------
作者:Kevin_Smart
来源:CSDN
原文:https://blog.csdn.net/davion_zhang/article/details/51536807
版权声明:本文为博主原创文章,转载请附上博文链接!