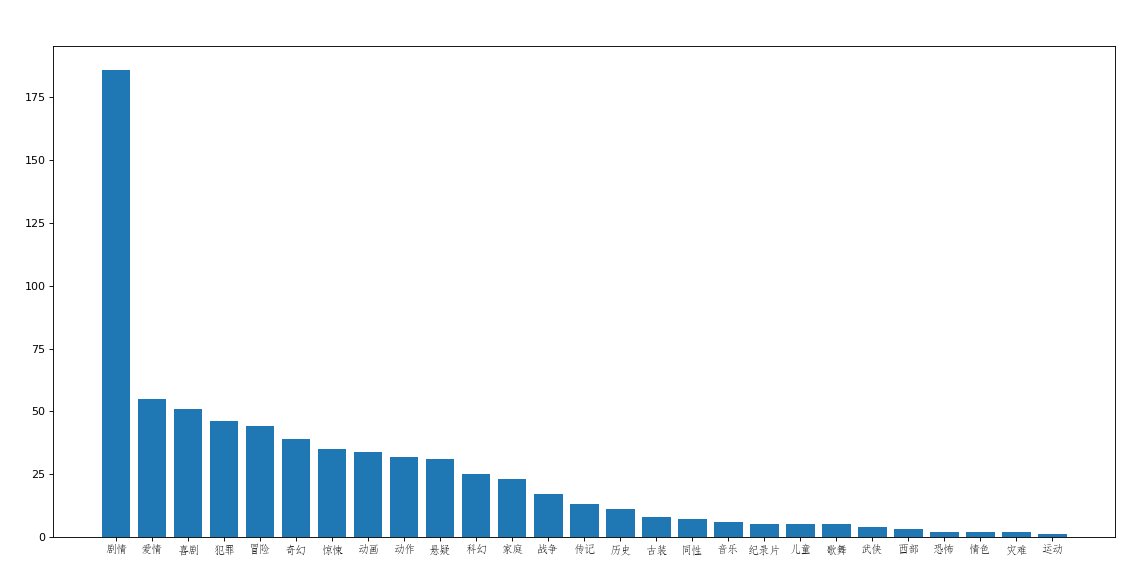
分析250条电影数据的类型数量分布
# coding = utf-8
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname='C:/Windows/Fonts/simfang.ttf')
df = pd.read_csv('E:/pythonob/data/movie_data/data_movie.csv')
temp_list = df['movie_type'].str.split('/').tolist() # 读取全部类型数据
gener_list = [i for j in temp_list for i in j] # 将全部类型数据放到一个列表内
out_data = list(set(gener_list)) # 去重
zero_data = pd.DataFrame(np.zeros((df.shape[0], len(out_data))), columns=out_data) # 构造全为0的数组
# 给每个电影类型出现的位置赋值1
for i in range(df.shape[0]):
zero_data.loc[i, temp_list[i]] = 1
# 统计每个分类的电影数量
movie_count = zero_data.sum(axis=0)
sorted_movie_count = movie_count.sort_values(ascending=False) # 排序
# 画图
plt.figure(figsize=(20, 8), dpi=80)
_x = sorted_movie_count.index
_y = sorted_movie_count.values
plt.bar(range(len(_x)), _y)
plt.xticks(range(len(_x)), _x, fontproperties=my_font)
plt.show()
效果图: