1.Spark SQL出现的 原因是什么?
Hive是Shark的前身,Shark是SparkSQL的前身,Spark SQL产生的根本原因是其完全脱离了Hive的限制。
特点:
引入了新的RDD类型SchemaRDD,可以像传统数据库定义表一样来定义SchemaRDD。
在应用程序中可以混合使用不同来源的数据,如可以将来自HiveQL的数据和来自SQL的数据进行Join操作。
内嵌了查询优化框架,在把SQL解析成逻辑执行计划之后,最后变成RDD的计算。
2.用spark.read 创建DataFrame
使用spark.read操作可以实现从不同类型的文件中加载数据创建DataFrame,如:读取文本文件并创建DataFrame:saprk.read.text("文件名.txt")或spark.read.format.("text").load("文件名.txt"),读取JSON文件并创建DataFrame:saprk.read.json("文件名.json")或spark.read.format.("json").load("文件名.json"),读取Parquet文件并创建DataFrame:saprk.read.parquet("文件名.parquet")或spark.read.format.("parquet").load("文件名.parquet")。
3.观察从不同类型文件创建DataFrame有什么异同?
在已有的RDDs转换成DateFrame
数组等结构化数据文件读取创建成DateFrame
JSO数据集创建成DateFrame
Hive表读取类似excel表数据创建成DateFrame
外部数据库读取数据创建成DateFrame
4.观察Spark的DataFrame与Python pandas的DataFrame有什么异同?
工作方式:pandas的是单机single machine tool,没有并行机制parallelism不支持Hadoop,处理大量数据有瓶颈
Spark的是分布式并行计算框架,内建并行机制parallelism,所有的数据和操作自动并行分布在各个集群结点上。以处理in-memory数据的方式处理distributed数据。 支持Hadoop,能处理大量数据
5.Spark SQL DataFrame的基本操作
创建:
spark.read.text()

spark.read.json()

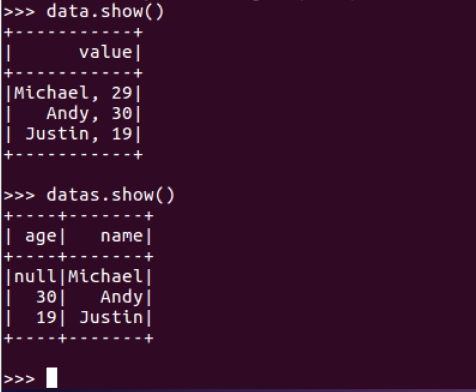
打印数据
data.show()默认打印前20条数据,data.show(n)
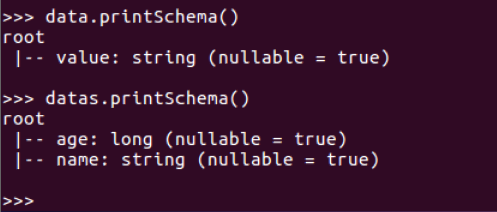
打印概要
data.printSchema()
查询总行数
data.count()

data.head(3) #list类型,list中每个元素是Row类

输出全部行
data.collect() #list类型,list中每个元素是Row类

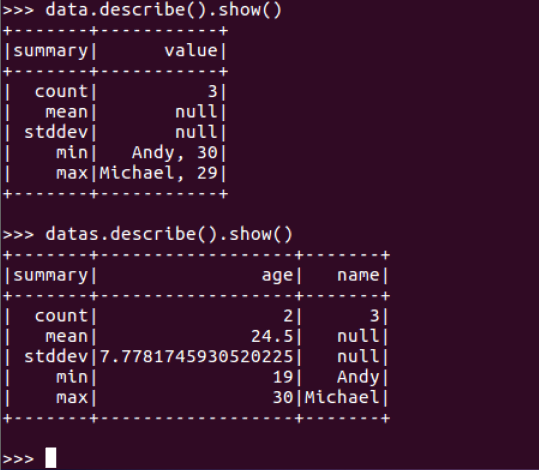
查询概况
data.describe().show()
取列
datas[‘name’]
datas.name
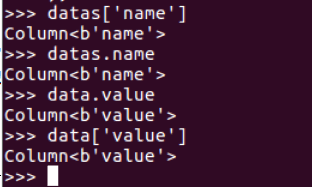
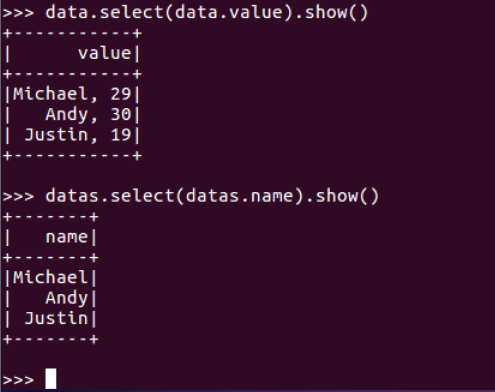
datas.select()
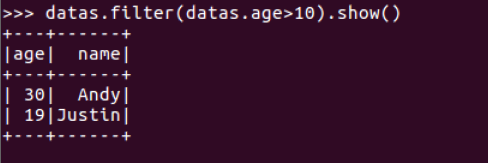
datas.filter()
datas.groupBy()

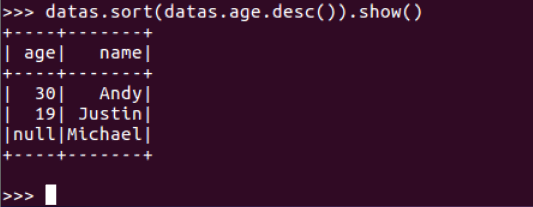
datas.sort()