考虑到Sizzle里面函数互相调用的关系,接下来的函数就不会按从上到下的顺序分析,而是采用调用的顺序进行分析。
这篇博客参考了这篇文章里的说明(靠这篇文章才理解的。。。。)
首先就是要讲到编译函数,JS是单线程语言,但是在执行程序时,一段函数的运行,会导致线程的阻塞,导致整个程序停顿。这时候异步就出现了,异步的原理不多说了。异步使得JS能够更加灵活的运行,克服了其单线程的限制,但是,大量采用异步会导致整个程序看起来乱糟糟的。所以异步,同步编程的安排还是需要根据实际来控制的。
好像说偏了。。按照上面参考文章的说法,'JavaScript是单线程的,代码也是同步从上向下执行的,执行流程不会随便地暂停,当遇到异步的情况,从而改变了整个执行流程的时候,我们需要对代码进行自动改写,也就是在程序的执行过程中动态生成并执行新的代码,这个过程我想称之为编译函数的一种运用吧.'
Sizzle通过compile函数实现了编译函数,compile函数的作用是根据传入的selector进行分词,即调用tokenize,根据返回的结果,对其中每个词形成特定的判断函数,然后将函数集中返回(返回的是一个function)
废话不多说,直接上源码:
compile = Sizzle.compile = function( selector, group /* Internal Use Only */ ) { var i, setMatchers = [], elementMatchers = [], cached = compilerCache[ selector + " " ]; if ( !cached ) { // 判断词是否被分解过 if ( !group ) { group = tokenize( selector ); } i = group.length; while ( i-- ) { // 调用matcherFromTokens,生成特定词的判断函数 cached = matcherFromTokens( group[i] ); // 根据函数添加到不同的数组中 if ( cached[ expando ] ) { setMatchers.push( cached ); } else { elementMatchers.push( cached ); } } // 整合,缓存 cached = compilerCache( selector, matcherFromGroupMatchers( elementMatchers, setMatchers ) ); } return cached; };
可以看到,函数中最关键的是通过matcherFromTokens来生成特定判定函数,下面的就是这段函数的源码:
function matcherFromTokens( tokens ) { var checkContext, matcher, j, len = tokens.length, leadingRelative = Expr.relative[ tokens[0].type ], implicitRelative = leadingRelative || Expr.relative[" "], i = leadingRelative ? 1 : 0, // 保证可以从最顶端的context访问到这些元素 matchContext = addCombinator( function( elem ) { return elem === checkContext; }, implicitRelative, true ), matchAnyContext = addCombinator( function( elem ) { return indexOf.call( checkContext, elem ) > -1; }, implicitRelative, true ), matchers = [ function( elem, context, xml ) { return ( !leadingRelative && ( xml || context !== outermostContext ) ) || ( (checkContext = context).nodeType ? matchContext( elem, context, xml ) : matchAnyContext( elem, context, xml ) ); } ]; //根据传入的tokens循环 for ( ; i < len; i++ ) { if ( (matcher = Expr.relative[ tokens[i].type ]) ) { // 若分词为'+','~',' ','>',调用addCombinator生成总的判断函数 matchers = [ addCombinator(elementMatcher( matchers ), matcher) ]; } else { // 若分词为TAG等 matcher = Expr.filter[ tokens[i].type ].apply( null, tokens[i].matches ); // 特殊的位置判断符,如:eq(0) if ( matcher[ expando ] ) { // 找到下一个相对位置的匹配符 j = ++i; for ( ; j < len; j++ ) { if ( Expr.relative[ tokens[j].type ] ) { break; } } return setMatcher( i > 1 && elementMatcher( matchers ), i > 1 && toSelector( // If the preceding token was a descendant combinator, insert an implicit any-element `*` tokens.slice( 0, i - 1 ).concat({ value: tokens[ i - 2 ].type === " " ? "*" : "" }) ).replace( rtrim, "$1" ), matcher, i < j && matcherFromTokens( tokens.slice( i, j ) ), //如果位置伪类后面还有选择器需要筛选 j < len && matcherFromTokens( (tokens = tokens.slice( j )) ), //如果位置伪类后面还有关系选择器还需要筛选 j < len && toSelector( tokens ) ); } matchers.push( matcher ); } } return elementMatcher( matchers ); }
其实,仔细看可以发现,压入matchers中的函数都只是返回true或false的用来检验元素匹配与否的,但是在这里都不是立刻执行的,而是将其压入,合并。
elementMatcher函数通过闭包的方式,将matches一直保存在内存中。
注意到,关系符出现后就会合并前面的函数
matchers = [ addCombinator(elementMatcher( matchers ), matcher) ];
首先调用的就是elementMatcher,将原来matchers中的内容合并:
function elementMatcher( matchers ) { return matchers.length > 1 ? function( elem, context, xml ) { var i = matchers.length; while ( i-- ) { if ( !matchers[i]( elem, context, xml ) ) { return false; } } return true; } : matchers[0]; }
通过返回一个函数,在返回函数中将matchers中的每一项进行执行,都为true才返回true,否则就直接返回false。
然后是将elementMatcher生成的函数和关系选择符用addCombinator生成一个判断函数:
function addCombinator( matcher, combinator, base ) { var dir = combinator.dir, checkNonElements = base && dir === "parentNode", doneName = done++; return combinator.first ? // 确定是否是紧跟在后面的子代元素或者兄弟元素 function( elem, context, xml ) { while ( (elem = elem[ dir ]) ) { if ( elem.nodeType === 1 || checkNonElements ) { return matcher( elem, context, xml ); } } } : // 对于不是紧跟的节点 function( elem, context, xml ) { var oldCache, outerCache, newCache = [ dirruns, doneName ]; // 不能再xml节点上设置额外信息,所以不能使用cache if ( xml ) { while ( (elem = elem[ dir ]) ) { if ( elem.nodeType === 1 || checkNonElements ) { if ( matcher( elem, context, xml ) ) { return true; } } } } else { while ( (elem = elem[ dir ]) ) { if ( elem.nodeType === 1 || checkNonElements ) { outerCache = elem[ expando ] || (elem[ expando ] = {}); if ( (oldCache = outerCache[ dir ]) && oldCache[ 0 ] === dirruns && oldCache[ 1 ] === doneName ) { // 有缓存且符合关系的话就直接返回不需调用matcher了 return (newCache[ 2 ] = oldCache[ 2 ]); } else { outerCache[ dir ] = newCache; // 有match时就说明成功了,就可以直接返回,否则要继续循环 if ( (newCache[ 2 ] = matcher( elem, context, xml )) ) { return true; } } } } } }; }
这样通过一些列函数的调用,就完成了当前词的匹配器
在没有'+','~',' ','>'这些词素时,如#a.b[value='c']时,就只需要从右到左检测一遍就可以了。
但是,在有了上面那些词素后,就需要对其进行深一度的打包。
这样,在有很多词素的选择器中,就会形成一个嵌套很深的闭包函数
借图一张来说明:
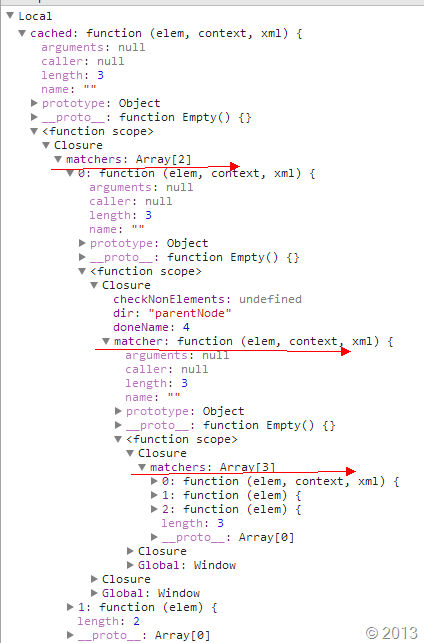
对于这些组合之后怎么执行,我继续研究下,应该是通过matcherFromGroupMatchers函数。现在还在学习中,在下一章会详细讲一下。