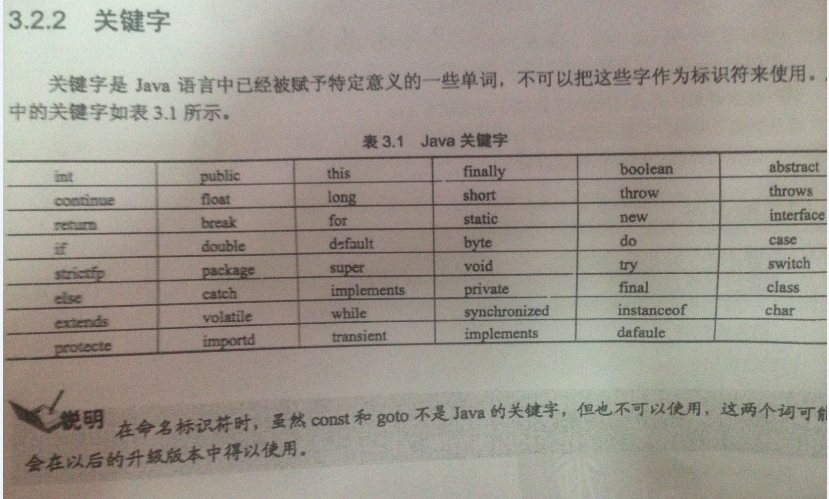
一.标识符
1.标识符可以简单地理解为一个名字,用来标识类名、变量名、方法名、数组名、文件名的有效字符序列。
2.标识符的命名规则
(1)可以包含字母,数字,$,_,数字不能在开始的位置
(2)Java语言中的字母可以使Unicode字符集中的任何字符,包括拉丁字母,汉字,日文和其他许多语言中的字符
(3)标识符不能使Java的关键字和保留字
(4)严格区分大小写,如果两个标识符的字母相同但是大小写不同,就是不同的标识符
3.说明
在程序开发中,虽然可以使用汉字,日文等作为标识符,但为了避免出现错误,尽量不要使用,最好连下划线和数字也不要使用,而只用英文进行命名,且首字母用大写字母书写。
二.基本数据类型
在Java中有8种基本数据类型,其中6种是数值类型,另外两种分别是字符类型和布尔类型,而6种数值类型中有4种是整数类型,另外两种是浮点类型。
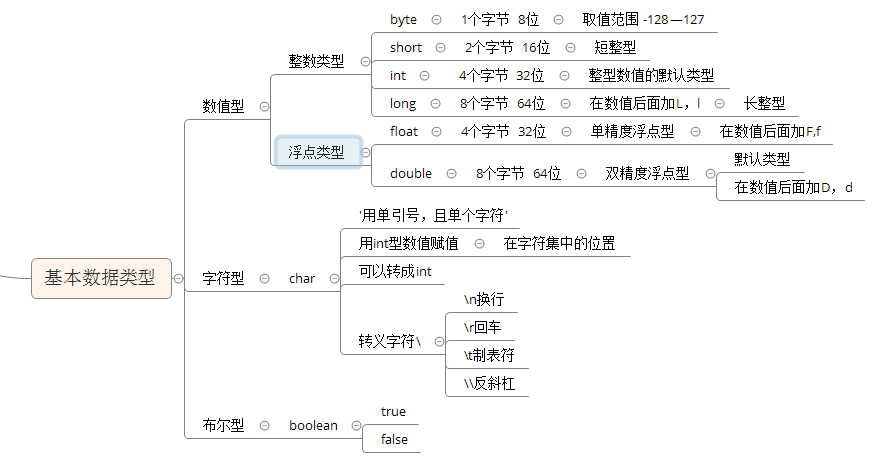
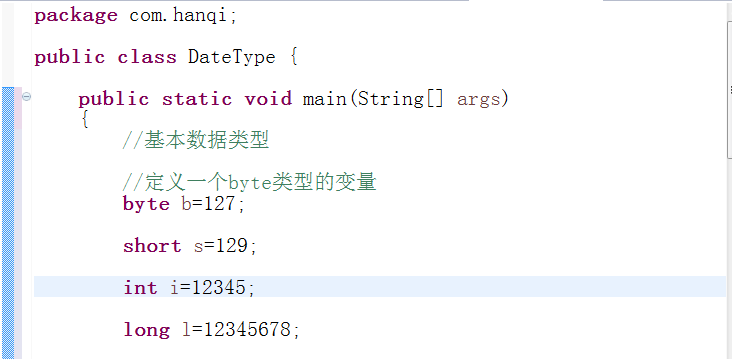
(1).byte型
可以一次定义多个变量并对其进行赋值,也可以不进行赋值。byte型是整型中所分配的内存空间最少的,只分配1个字节;取值范围也是最小的,只在-128~127之间。
(2).short型
即短整型,可以一次定义多个变量并对其进行赋值,也可以不进行赋值。系统给short型分配2个字节的内存,取值范围在-32768~32767之间。也要注意数据溢出。
(3)int型
即整型,可以一次定义多个变量并对其进行赋值,也可以不进行赋值。int型变量取值范围很大,在-2147483648~2147483647之间,足够一般情况下使用,是整型变量中应用最广泛的。
(4)long型
即长整型,可以一次定义多个变量并对其进行赋值,也可以不进行赋值。在对long型变量赋值时结尾必须加上“L”或者“l”;否则将不被认为是long型。当数值过大,超出int型范围时就使用long型,系统分配给long型变量8个字节,取值范围更大,在-9223372036854775808~9223372036854775807之间。
(5).float型
即单精度浮点型,可以一次定义多个变量并对其进行赋值,也可以不进行赋值。在对float型变量赋值时结尾必须加上“F”或者“f”;如果不加,系统自动将其定义为double型变量。float型变量取值范围在1.4E-45和3.4028235E-38之间。
(6)double型
即双精度浮点型,可以一次定义多个变量并对其进行赋值,也可以不进行赋值。在对double型变量赋值时结尾必须加上“D”或者“d”;但加不加并没有硬性规定,可以加也可以不加。取值范围在4.9E-324和1.7976931348623157E-308之间。

(7)字符型
char型即字符型,使用char关键字进行声明,用于存储单个字符,系统分配两个字节的内存空间。在定义字符型变量时,使用单引号括起来,且单引号中只能有一个字符,多了就不是字符类型了,而是字符串类型,需要用双引号进行声明。

转义字符有:


(8).布尔类型
布尔类型又称逻辑类型,只有true和false两个值,分别代表布尔逻辑中的“真”和“假”。使用boolean关键字声明布尔类型变量,通常被用在流程控制中作为判断条件。

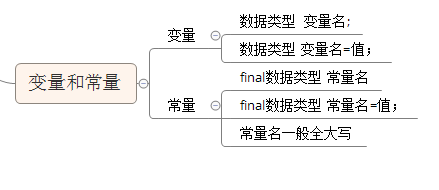
三.变量和常量

utf-8
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,又称万国码。由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。UTF-8用1到6个字节编码UNICODE字符。用在网页上可以同一页面显示中文简体繁体及其它语言(如英文,日文,韩文)。