一、索引介绍
1.1 什么是索引
索引就好比一本书的目录,它会让你更快的找到内容。
让获取的数据更有目的性,从而提高数据库检索数据的性能。
分为以下四种:
- BTREE:B+树索引(基本上都是使用此索引)
- HASH:HASH索引
- FULLTEXT:全文索引
- RTREE:R树索引
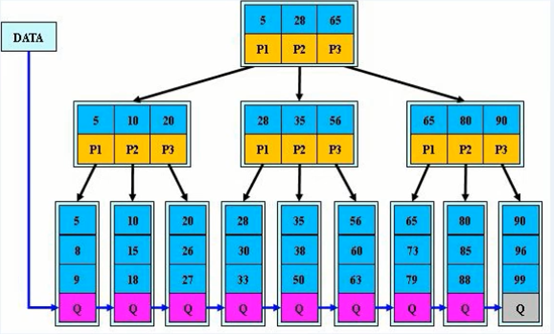
树形结构(B树:B树、B+树、B*树),
B树索引由多个层次构成:‘根’,‘枝’,‘叶’,它建立在表的列上
stu(id, name, age)
假如说,在id列上建索引
A. 对id列的值,进行自动排序,把这些值有规律的存放到各个叶子节点
B. 并且叶子节点还会存储整行数据的指针信息
C. 生成上层枝节点,存储每个对应叶子节点最小值和叶子节点指针
D. 生成根节点,存储每个枝节点的最小值以及对应的存储指针
以上是B树索引的基本构成
E. 对于B+树索引结构,对于范围查询有了更好的优化,叶子节点还会记录相邻叶子节点指针
F. 对于B*树索引结构,枝节点还会记录相领枝节点的指针情况
B+树图:
1.2 主键和索引的区别
索引:索引好比是一本书的目录,可以快速的通过页码找到你需要的那一页。惟一地标识一行。
主键:做为数据库表唯一行标识,作为一个可以被外键有效引用的对象。
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。索引可以大大提高MySQL的检索速度。
数据库有两种查询方式,一个全表扫描,条件匹配。一个是索引。
主键是特殊的索引,主键是索引,索引不一定是主键,索引可以是多列,主键只能是一列。
二、索引执行计划管理
基于特点的一些分类:
- 主键索引(聚集索引 cluseter indexes):parmary key(创建主键后自动生成的,最符合B+ 树的)
- 唯一键:唯一键索引(都是唯一值的列)
- 普通键:辅助索引(sec indexex)
优先使用主键索引,查询的时候还要基于主键索引进行查询。
三、添加、查询、删除索引
-- 添加一张表 mysql> create table stu (id int not null auto_increment primary key,name varchar(20),age tinyint,gender enum('m','f'),telnum varchar(12),qq varchar(20)); Query OK, 0 rows affected (0.02 sec) -- 把name列设置为普通索引,idx_name为key的名字 mysql> alter table stu add index idx_name(name); Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 -- 查询索引 mysql> desc stu; +--------+---------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------+---------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | varchar(20) | YES | MUL | NULL | | | age | tinyint(4) | YES | | NULL | | | gender | enum('m','f') | YES | | NULL | | | telnum | varchar(12) | YES | | NULL | | | qq | varchar(20) | YES | | NULL | | +--------+---------------+------+-----+---------+----------------+ 6 rows in set (0.00 sec) mysql> show index from stu; +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | stu | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | | | stu | 1 | idx_name | 1 | name | A | 0 | NULL | NULL | YES | BTREE | | | +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ 2 rows in set (0.00 sec) mysql> show index from stuG *************************** 1. row *************************** Table: stu Non_unique: 0 Key_name: PRIMARY Seq_in_index: 1 Column_name: id Collation: A Cardinality: 0 Sub_part: NULL Packed: NULL Null: Index_type: BTREE Comment: Index_comment: *************************** 2. row *************************** Table: stu Non_unique: 1 Key_name: idx_name Seq_in_index: 1 Column_name: name Collation: A Cardinality: 0 Sub_part: NULL Packed: NULL Null: YES Index_type: BTREE Comment: Index_comment: 2 rows in set (0.00 sec) -- 删除索引 mysql> alter table stu drop key idx_name; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> show index from stu; +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | stu | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | | +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ 1 row in set (0.00 sec) -- key就是索引的意思,PRI就是主键,MUL就是普通的索引,UNQ、UNI 是唯一键
四、创建表的时候创建自增主键
CREATE TABLE `stu` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(20) DEFAULT NULL, `age` tinyint(4) DEFAULT NULL, `gender` enum('m','f') DEFAULT NULL, `telnum` varchar(12) DEFAULT NULL, `qq` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8
如果当时没有创建,后面可以增加
mysql> CREATE TABLE `stu_test` ( -> `id` int(11) NOT NULL, -> `name` varchar(20) DEFAULT NULL -> ) ENGINE=InnoDB DEFAULT CHARSET=utf8; Query OK, 0 rows affected (0.23 sec) mysql> desc stu_test; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | id | int(11) | NO | | NULL | | | name | varchar(20) | YES | | NULL | | +-------+-------------+------+-----+---------+-------+ 2 rows in set (0.01 sec) mysql> alter table stu_test change id id int(11) primary key not null auto_increment; Query OK, 0 rows affected (0.03 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc stu_test; +-------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | varchar(20) | YES | | NULL | | +-------+-------------+------+-----+---------+----------------+ 2 rows in set (0.00 sec)
五、唯一索引
内容唯一,但不是主键
可以统计一下有没有重复值,用去重后的行数,和总行数做个比较,如果不一样,说明有重复的值。
-- 添加telnum为唯一键索引 alter table stu add UNIQUE key uni_tel(telnum); -- 统计总行数 select count(*) from webdb.t1;
-- telnum列去重之后还剩多少行 SELECT count(distinct telnum) from webdb.t1;
还可以判断是不是唯一索引,最简单的方法是建一建试试,如果建不上 说明有重复的。

六、前缀索引和联合索引
如果字符较长的时候,可以使用前缀索引
-- 根据字段的前10个字符建立索引,名称为index_note alter table stu add note varchar(200); alter table stu add index index_note(note(10));
联合索引
多个字段建立一个索引
条件:a(女生) and b(身高165) and c(身材好)
Index(a,b,c)
特点:前缀生效特性。
a,ab,abc,ac 可以走索引或者部分走索引
原则:把最常用来作为条件查询的列放在前面。
mysql> alter table stu add money int; Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> alter table stu add index idx_dup(gender,age,money); Query OK, 0 rows affected (0.00 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> show index from stu; +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | stu | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | | | stu | 0 | uni_tel | 1 | telnum | A | 0 | NULL | NULL | YES | BTREE | | | | stu | 1 | idx_dup | 1 | gender | A | 0 | NULL | NULL | YES | BTREE | | | | stu | 1 | idx_dup | 2 | age | A | 0 | NULL | NULL | YES | BTREE | | | | stu | 1 | idx_dup | 3 | money | A | 0 | NULL | NULL | YES | BTREE | | | +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ 5 rows in set (0.00 sec)
七、explain 命令分析
MySQL中的执行计划,只分为两种。都是优化器决定的
全表扫描:
一般在线上业务系统,要避免全表扫描
索引扫描:
将要获取的数据,变得更有目的性。
通过explain命令来 获取优化器选择后的执行计划,并不输出后面的语句结果。
mysql> explain select id,name from t1 where name='andy'; +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | t1 | ALL | NULL | NULL | NULL | NULL | 2 | Using where | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ 1 row in set (0.00 sec) -- type 表示的是使用的是全表扫描还是索引扫描 -- type 类型如下:ALL、index、range、ref、eq_ref、const、system、Null -- 从左到右,性能越来越好,我们在使用索引是,最底应达到range
-- key_len值越小越好
-- rows值越小越好
ALL 全表扫描
index:Full index scan,index与ALL区别为index类型只遍历索引树
range:索引范围扫描,对索引的扫描开始于某一点,返回匹配值域的行。显而易见的索引范围扫描是带有between或者where子句里带有<,>查询。
where条件后 > < >= <= in or between and like 'm%'

不等于是不走索引的!= 、<>、like '%m%'

此句性能略差

可改写为

ref:使用非唯一索引扫描或者唯一索引的前缀扫描,返回匹配某个单独值的记录行

eq_ref:类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者unique key作为关键条件。
A join B
on A.sid=b.sid
const、system:当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类方法访问。
如:将主键置于where列表中,MySQL就能将该查询转换为一个常量。

NULL:MySQL在优化过程中分解语句,执行时甚至不用访问表过索引。
例如:从一个索引列里选取最小值可通过单独索引查找完成
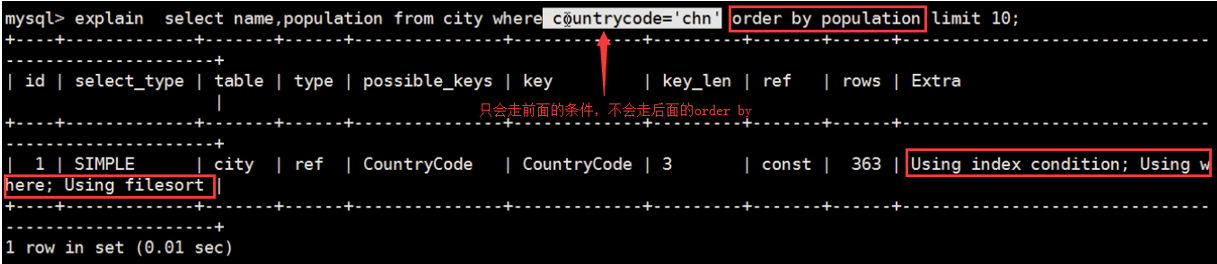
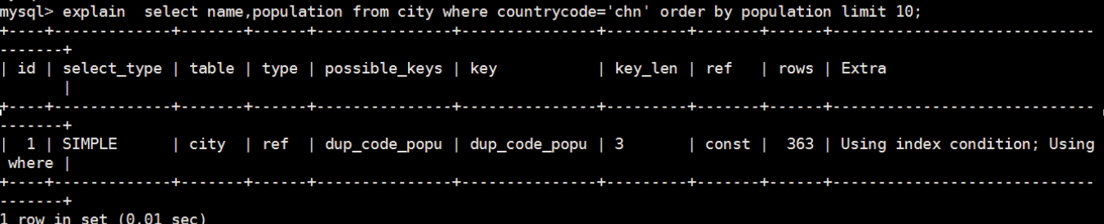
如果出现以上附加信息,请检查order by,group by,distince,join条件列上有没有合理的索引。(联合索引)
单列索引也不会避免filesort的出现
如果想优化,必须创建联合索引。
会发现,下面有两个索引,最后走的新创建的dup_codepogo

但是基于countcode有两个索引,需要删除一个,否则会影响优化器的算法。

Possible_key只有一个了,里面的extra正常了,只要不是filesort就正常。
八、建立索引的原则(运维规范)
数据库索引的设计原则:
为了使索引的使用效率更高,在创建索引时,必须考虑在哪些字段上创建索引和创建什么类型的索引,那么索引设计原因又是怎样的呢?
- 选择唯一性索引
- 唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录
- 例如:学生表中学号是具有唯一性的字段。为该字段建立唯一性索引可以很快的确定某个学生的信息,如果使用姓名的话,可能存在同名现象,从而降低查询速度。
- 主键索引和唯一索引,在查询中使用的效率最高的。
注意:如果重复值较多,可以考虑采用联合索引
2.为经常需要排序、分组和联合操作的字段建立索引
- 经常需要order by、group by、distinct和union等操作的字段,排序操作会浪费很多时间。
- 如果为其建立索引,可以有效地避免排序操作。
3.为常作为查询条件的字段建立索引
- 如果某个字段经常用来做查询条件,那么该字段查询的速度会影响整个表的查询速度。因此为这样的字段建立索引,可以提高整个表的查询速度。
- 经常查询
- 列值的重复值少
4.尽量使用前缀来索引
- 如果索引字段的值很长,最好使用值的前缀来索引。
- 例如:TEXT和BLOG类型的字段,进行全文检索会很浪费时间。如果只检索字段前面的若干字符,这样可以提高检索速度。
――――以上重点关注――――以下是能保护则保证的―――――
- 限制索引的数目
- 索引的数目不是越多越好。每个索引都需要占用磁盘空间,索引越多,需要占用的磁盘就越大,修改表时,对索引的重构和和更新很麻烦。越多的索引,会使更新表变得很浪费时间
2.删除不再使用,或者很少使用索引
- 表中的数据被大量更新,或者数据的使用方式被改变后,原有的一些索引可能不再需要。数据库管理员应当定期找出这些索引,将它们删除,从而减少索引对更新操作的影响。
――――不走索引的情况---------(开发规范)
重点关注:
1.没有查询条件,或者查询条件没有建立索引
-- 全表扫描 select * from t1; -- 工具生成,和全表扫描是一样的 select * from t1 where 1=1;
在线上业务数据库中,特别是数据量比较大的表,是没有全表扫描这种需求的。
A.对用户查看是非常痛苦的。
B.对服务器来讲是毁灭性的
例外:数据处理分析的业务,一般也不用mysql了
select * from t1; -- SQL改写成以下语句 -- 需要在price列上建立索引 select * from t1 ORDER BY price limit 10;
2.查询结果集是原表中的大部分数据,应该是25%以上。
查询的结果集,超过了总数行数25%,优化器觉得没必要走索引了。
如果业务允许,可以使用limit控制
怎么改写?
结合业务判断,有没有更好的方式。如果没有更好的改写方案,尽量不要在mysql存放这个数据了,放到redis中。
3.索引本身失效,统计数据不真实
索引有自我维护能力。
对于表内容变化比较频繁的情况下,有可能会出现索引失败。
4.查询条件使用函数在索引列上,或者对索引进行运算。运算符包括(+ - * / ! 等)
-- 错误的 select * from test where id-1=9; --正确的 select * from test where id=10;
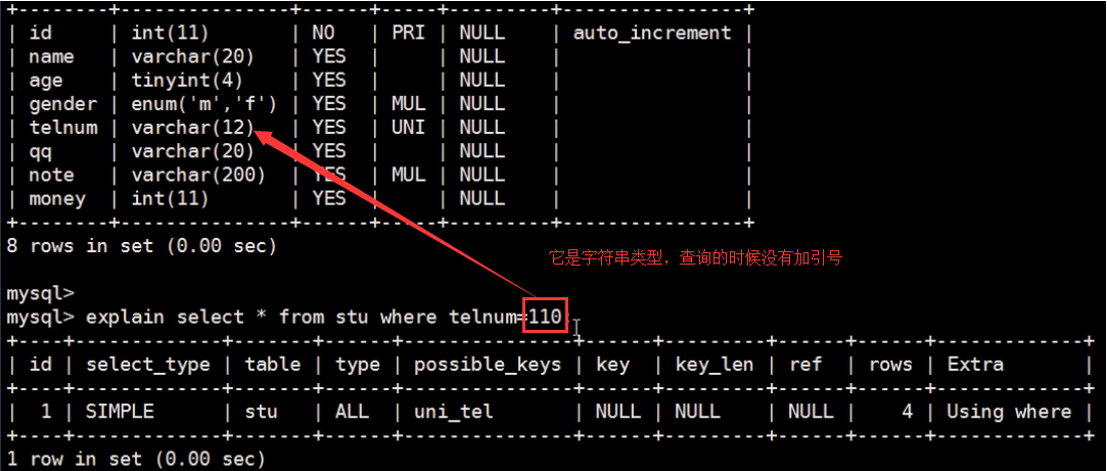
5.隐式转换导致索引失效,这一点应当引起重视,也是开发中常犯的错误。
这样会导航不索引失效,错误的例子

隐式的把数字转换成字符串
6.<> 、not in 不走索引
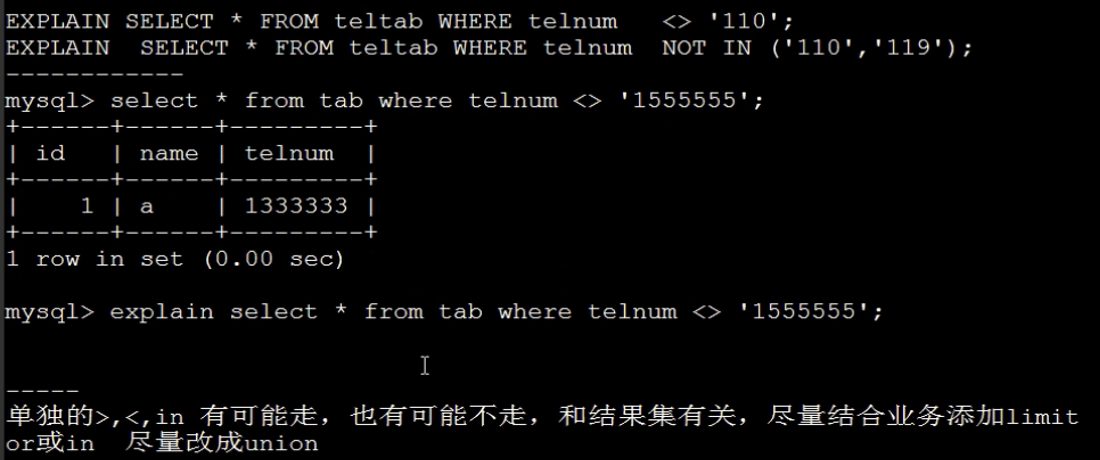
7.like '%a' 百分号在最前面不走索引

%linux%类的搜索需求,可以使用elasticsearch
8. 单独引用复合索引里非第一位置的索引列。
复合索引index(a,b,c)
where a
where a b
where a b c
保会走a的部分索引
where a c
where a c b
不走索引的:
任何where条件列a不在第一条件列的情况不走索引