一、实验目标
利用kettle实现从mysql数据库中的dbf库批量同步表到dbm库(全量同步)
二、实验环境
dbf 库中表f1、f2、f3 。f1中1条数据,f2中100条数据,f3中2条数据。
dbm库中表f1、f2、f3 。f1、f2、f3都为空表。
f1、f2、f3表结构一样如下:
CREATE TABLE `f1` (
`ID` bigint(20) NOT NULL AUTO_INCREMENT,
`anlage` varchar(20) DEFAULT NULL,
`card_count` int(11) DEFAULT NULL,
`card_id` varchar(30) DEFAULT NULL,
`card_no` varchar(30) DEFAULT NULL,
`card_remark` varchar(5) DEFAULT NULL,
`company_code` varchar(20) DEFAULT NULL,
`do_code` varchar(10) DEFAULT NULL,
`updatetime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`ID`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8mb4;
三、实验步骤
1.创建一个job(insert_job):

2.创建转换gettable
表输入: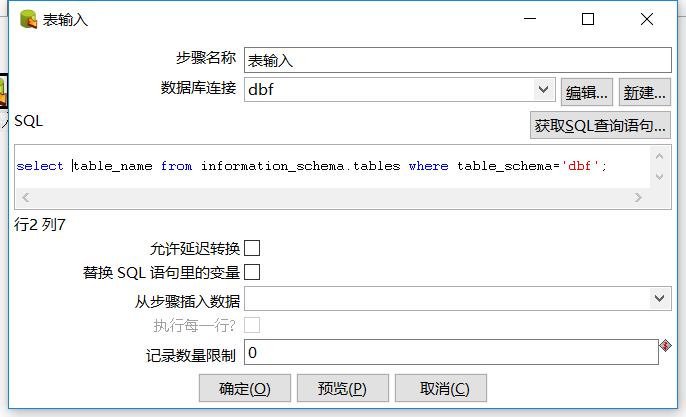
3.创建转换insertall

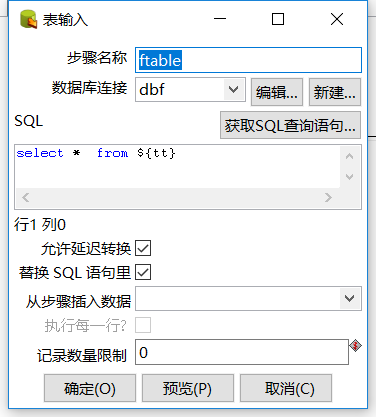
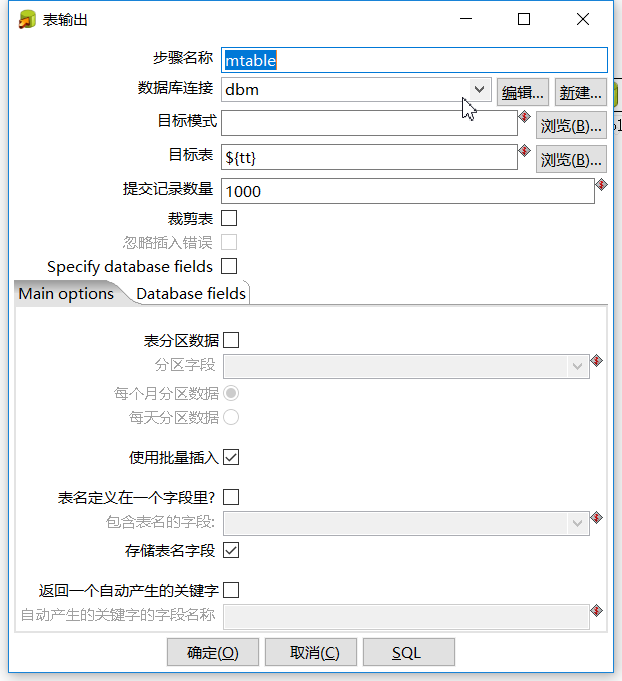
表输入ftable: 表输出mtable:
转换insertall属性:
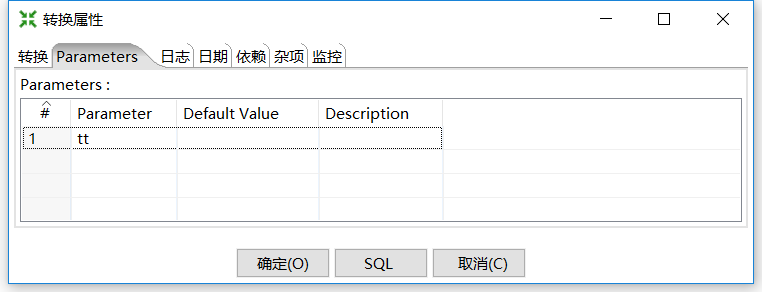
4.insert_job 属性
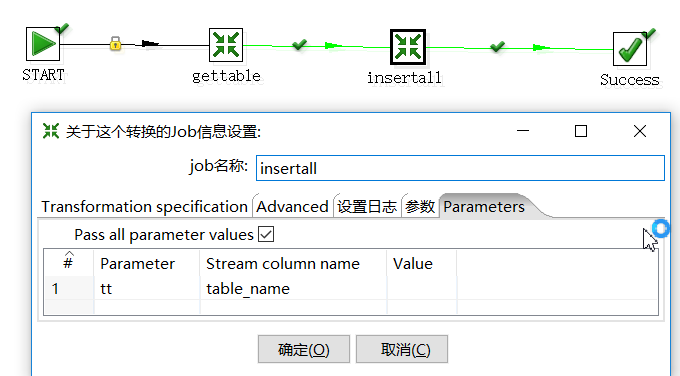
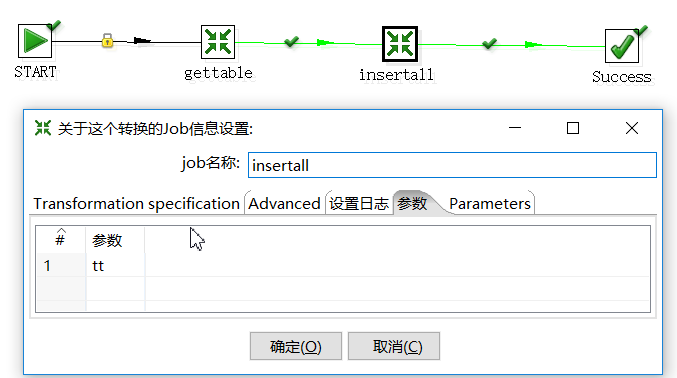
四、实验结果
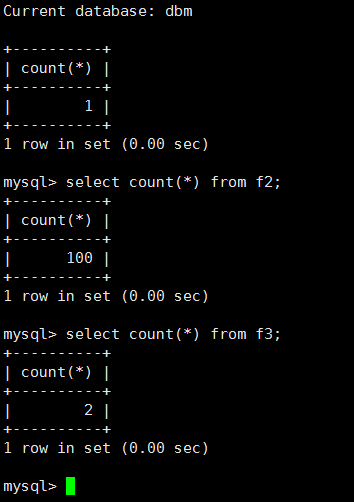
结论:
整个过程简单粗暴,很low,但也记录一下学习点滴