1 文本和字节序列
我们都知道字符串,就是由一些字符组成的序列构成串,那么字符又是什么呢?计算机只能识别二进制的东西,那么计算机又为什么会显示我们的汉字,或者是某个字母呢?
由于最早发明使用计算机是美国人,他们为了解决了英语如何在电脑上显示,就制定了一套标准:ASCII ((American Standard Code for Information Interchange): 美国信息交换标准代码),主要用于显示现代英语和其他西欧语言。到目前为止共定义了128个字符,从0-127的二进制数分别对应了相应的字符,这样就将现实中的字符和计算机的二进制联系起来,从而将字符表达显示在计算机上。
随机计算机的普遍,各国有不同的语言,每个国家为了普及计算机的使用,那么如何将各自国家的语言表达在计算机上就成了一个问题。于是,不同的国家都在制定适用自个国家的字符集,比如对于我国来说,就有gbk《汉字内码扩展规范》,它也是将每个字符(字)和计算机的二进制对应起来。那么问题来了,不同的国家使用各自国家的一套规范,在跨国交流时,就会出现文本显示的乱码。于是就有了一套统一的机制Unicode。Unicode(统一码、万国码、单一码),它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
1.1 字符和字节
目前使用的基本是Unicode定义的字符,从Python3的str对象中获取的元素就是Unicode字符。字符的具体表述取决于所用的编码。编码是在码位和字节序列之间转换时使用的算法。使用最多的是utf-8编码,使用该编码,文本文件可以跨平台显示。把码位转换成字节序列的过程是编码;把字节转换成码位的过程是解码。
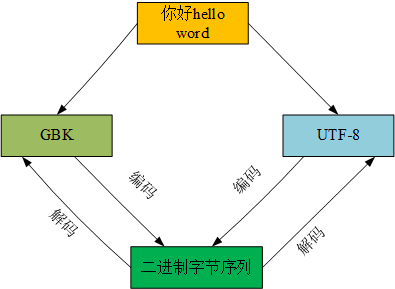
编码时使用的编码算法要与解码时使用的解码算法相同,要不然会出现乱码的现象。
1.2 字符与字节的转换
字符是组成字符串有序序列的单个元素,字符可以用上面的编码来理解。字符串按照不同的字符集编码返回字节序列bytes。

字节序列安装不同的字符集解码返回字符串
1 bytes.decode(encoding="utf-8", errors="strict") -> str
2 bytearray.decode(encoding="utf-8", errors="strict") -> str
1.3 bytes与bytearray
Python中内置了两种基本的二进制序列类型:Python 3 引入的不可变bytes类型和Python 2.6 增加的可变bytearray类型(字节数组)
1.3.1 bytes定义
bytes有以下的定义方法:
| Definition | Function |
| bytes() | 定义空的bytes |
|
bytes(int) |
指定字节的bytes,被0填充 |
| bytes(iteeable_of_ints) | bytes[0,255]的int组成的可迭代对象 |
| bytes(string, encoding[, errors]) | 等价于string.encode() |
| bytes(bytes_or_buffer) |
immutable copy of bytes_or_buffer 从一个字节序列或者buffer复制出 |
| 使用b前缀定义 |
只允许基本ASCII使用字符形式b'abc9'; 使用16进制表示b"x41x61" |
1.3.2 bytes操作
和str类型类似,都是不可变类型,所以很多方法都一样。只不过bytes的方法,输入的是bytes,输出的也是bytes。下面看bytes的基本操作:
- b'abcdef'.replace(b'f',b'k')
- b'abc'.find(b'b')
- bytes.fromhex(string) string必须是2个字符的16进制的形式,比如bytes.fromhex('6162 09 6a 6b00'),空格将被忽略
- 'abc'.encode().hex() 返回16进制表示的字符串
- b'abcdef'[2] 返回该字节对应的数,int类型
1.3.3 bytearray定义
| Definition | Function |
| bytearray() | 空bytearray |
| bytearray(int) | 指定字节的bytearray,被0填充 |
| bytearray(iterable_of_ints) | bytearray [0,255]的int组成的可迭代对象 |
| bytearray(string, encoding[, errors]) | bytearray 近似string.encode(),不过返回可变对象 |
| bytearray(bytes_or_buffer) | 从一个字节序列或者buffer复制出一个新的可变的bytearray对象 |
1.3.4 bytearray操作
和bytes类型的方法相同:
- bytearray(b'abcdef').replace(b'f',b'k')
- bytearray(b'abc').find(b'b')
- bytearray.fromhex('6162 09 6a 6b00')
- bytearray('abc'.encode()).hex()
- bytearray(b'abcdef')[2] 返回该字节对应的数,int类型
bytearray是字节型的数组,相当于列表一样,只不过bytearray中存储的是字节形式的序列。它也支持和列表一些相同的操作: