1、 replication
如图.1所示,同一个 partition 可能会有多个 replica(对应 server.properties 配置中的 default.replication.factor=N)。没有 replica 的情况下,一旦 broker 宕机,其上所有 patition 的数据都不可被消费,同时 producer 也不能再将数据存于其上的 patition。引入replication 之后,同一个 partition 可能会有多个 replica,而这时需要在这些 replica 之间选出一个 leader,producer 和 consumer 只与这个 leader 交互,其它 replica 作为 follower 从 leader 中复制数据。
Kafka 分配 Replica 的算法如下:
1. 将所有 broker(假设共 n 个 broker)和待分配的 partition 排序 2. 将第 i 个 partition 分配到第(i mod n)个 broker 上 3. 将第 i 个 partition 的第 j 个 replica 分配到第((i + j) mode n)个 broker上
2 leader failover
当 partition 对应的 leader 宕机时,需要从 follower 中选举出新 leader。在选举新leader时,一个基本的原则是,新的 leader 必须拥有旧 leader commit 过的所有消息。
kafka 在 zookeeper 中(/brokers/.../state)动态维护了一个 ISR(in-sync replicas),由3.3节的写入流程可知 ISR 里面的所有 replica 都跟上了 leader,只有 ISR 里面的成员才能选为 leader。对于 f+1 个 replica,一个 partition 可以在容忍 f 个 replica 失效的情况下保证消息不丢失。
当所有 replica 都不工作时,有两种可行的方案:
1. 等待 ISR 中的任一个 replica 活过来,并选它作为 leader。可保障数据不丢失,但时间可能相对较长。 2. 选择第一个活过来的 replica(不一定是 ISR 成员)作为 leader。无法保障数据不丢失,但相对不可用时间较短。
kafka 0.8.* 使用第二种方式。
kafka 通过 Controller 来选举 leader,流程请参考5.3节。
3 broker failover
kafka broker failover 序列图如下所示:
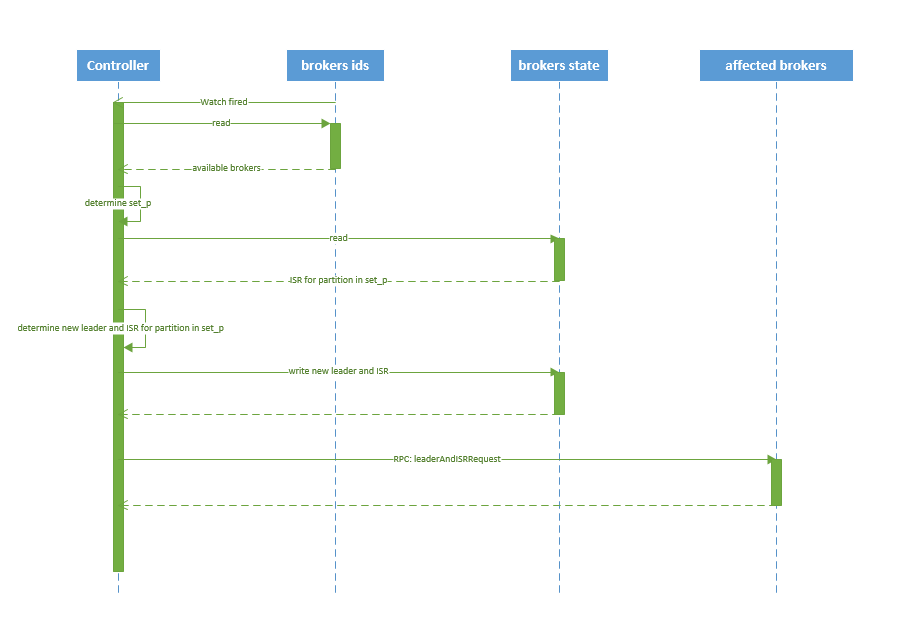
图.7
流程说明:
1. controller 在 zookeeper 的 /brokers/ids/[brokerId] 节点注册 Watcher,当 broker 宕机时 zookeeper 会 fire watch
2. controller 从 /brokers/ids 节点读取可用broker
3. controller决定set_p,该集合包含宕机 broker 上的所有 partition
4. 对 set_p 中的每一个 partition
4.1 从/brokers/topics/[topic]/partitions/[partition]/state 节点读取 ISR
4.2 决定新 leader(如4.3节所描述)
4.3 将新 leader、ISR、controller_epoch 和 leader_epoch 等信息写入 state 节点
5. 通过 RPC 向相关 broker 发送 leaderAndISRRequest 命令
4 controller failover
当 controller 宕机时会触发 controller failover。每个 broker 都会在 zookeeper 的 "/controller" 节点注册 watcher,当 controller 宕机时 zookeeper 中的临时节点消失,所有存活的 broker 收到 fire 的通知,每个 broker 都尝试创建新的 controller path,只有一个竞选成功并当选为 controller。
当新的 controller 当选时,会触发 KafkaController.onControllerFailover 方法,在该方法中完成如下操作:
1. 读取并增加 Controller Epoch。 2. 在 reassignedPartitions Patch(/admin/reassign_partitions) 上注册 watcher。 3. 在 preferredReplicaElection Path(/admin/preferred_replica_election) 上注册 watcher。 4. 通过 partitionStateMachine 在 broker Topics Patch(/brokers/topics) 上注册 watcher。 5. 若 delete.topic.enable=true(默认值是 false),则 partitionStateMachine 在 Delete Topic Patch(/admin/delete_topics) 上注册 watcher。 6. 通过 replicaStateMachine在 Broker Ids Patch(/brokers/ids)上注册Watch。 7. 初始化 ControllerContext 对象,设置当前所有 topic,“活”着的 broker 列表,所有 partition 的 leader 及 ISR等。 8. 启动 replicaStateMachine 和 partitionStateMachine。 9. 将 brokerState 状态设置为 RunningAsController。 10. 将每个 partition 的 Leadership 信息发送给所有“活”着的 broker。 11. 若 auto.leader.rebalance.enable=true(默认值是true),则启动 partition-rebalance 线程。 12. 若 delete.topic.enable=true 且Delete Topic Patch(/admin/delete_topics)中有值,则删除相应的Topic。