今天尝试了一下用python3加正则表达式爬取糗事百科的内容,让我们一起来看一下:
我们的目标是爬取用户名和所对应的段子内容
首先来观察网站,进入糗事百科首页。
(1)鼠标放在用户名上右键点“检查”:

通过观察可以得到用户名的正则表达式:userpart为'target="_blank" onclick.+?<h2>(.*?)</h2>'
(2)鼠标放在段子内容上右键点“检查”:
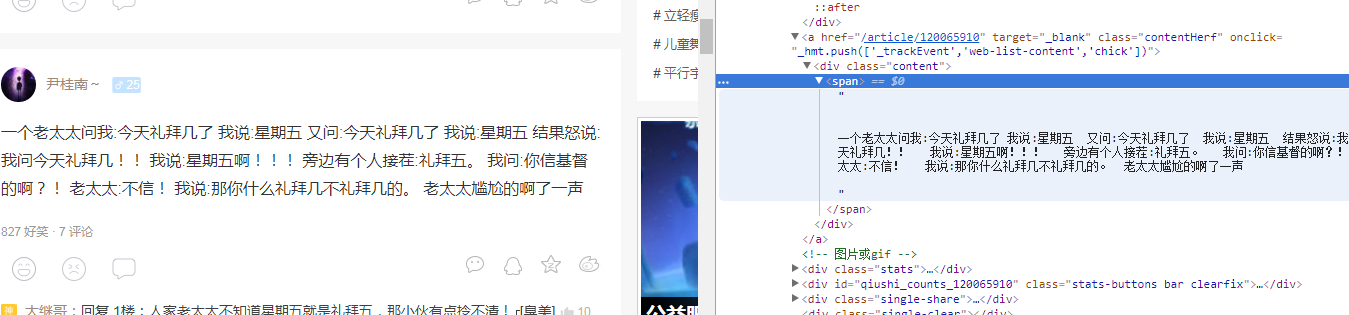
通过观察可以得到段子内容的正则表达式:contentpart为'div class="content".*?<span>(.*?)</span>'
(3)把用户名和列表放进字典存储到json格式文本里面
(4)代码可以成功运行,如有疑问请留言
import urllib.request import re import json def getcontentt(url,page): headers = ( "User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36" ) opener=urllib.request.build_opener() opener.addheaders=[headers] urllib.request.install_opener(opener) data=urllib.request.urlopen(url).read().decode('utf-8') userpart='target="_blank" onclick.+?<h2>(.*?)</h2>' contentpart='div class="content".*?<span>(.*?)</span>' userlist=re.compile(userpart,re.S).findall(data) contentlist=re.compile(contentpart,re.S).findall(data) #print(userlist[2]) #print(contentlist[0]) x=0 # for content in contentlist: # content=content.replace(' ','') # name="content"+str(x) # exec(name+'=content') # x+=1 # y=1 # for user in userlist: # name="content"+str(y) # print("用户"+str(page)+str(y)+"是:"+user) # print("内容是:") # exec("print("+name+")") # print(" ") # y+=1 for user in userlist: user=user.replace(" ","") print("用户名:"+user) content=contentlist[x].replace(" ","") print("内容是:"+content) print(" ") items={'用户名:':user,"内容:":content} #把字典写入json文件 items=json.dumps(items,ensure_ascii=False).encode('utf-8') with open("E:/爬虫练习/pj1/文件/duanzi.json", 'ab+')as f: f.write(items+b' ') x=x+1 for i in range(1,2): url="https://www.qiushibaike.com/8hr/page/"+str(i)+'/' getcontentt(url,i)