BoTNet::Bottleneck Transformers for Visual Recognition(视觉识别的瓶颈transformer)
0、摘要
我们提出了BoTNet,一个简单但功能强大的骨干网络,可用于多种视觉任务,包括图像分类、目标检测、实例分割。通过在ResNet的最后三个 bottleneck blocks 中用全局自注意力机制替换卷积而不做其他改变,我们的方法在实例分割和目标检测的 baselines 上有了显著的改进,同时也减少了参数,并且将延迟开销降最小。通过BoTNet的设计,我们将具有 self-attention 的 ResNet bottleneck blocks 视为 Transformer blocks 。没有任何华丽的点缀,基于Mask R-CNN框架,BoTNet在COCO基准数据集上达到了(44.4\%)的mask AP和(49.7\%)的box AP;超越了之前在COCO验证集上评估的ResNeSt[72]的最佳单模型和单尺度结果。最后,我们提出了一个针对图像分类的简单的适应:BoTNet网络,它在 (ImageNet) 上实现了 (2.33 imes)的计算速度,同时 Top-1 精度达到了 (84.7%),计算设备为(TPU_{v3}) 。我们希望这个简单、高效的研究将作为未来在视觉自注意力模型的一个 strong baseline。
1、介绍
深度卷积backbone框架[40,56,29,70,59]在图像分类[54],目标检测[17, 42, 21, 20, 53],实例分割[25, 12, 28]实现了显著的提升。大多数标志性的backbone框架都大量使用了 (3 imes 3) 的卷积。
虽然卷积运算可以有效地捕获局部信息,但是目标检测、实例分割、关键点检测等视觉任务需要建立长距离依赖模型。例如,实例分割模型,能够从一个大的邻域中收集和关联场景信息,这对于学习对象之间的关系非常有用[34]。为了全局聚合本地捕获的 filter 响应,基于卷积的架构需要堆叠多个层[56, 29]。虽然堆叠更多的层在这些backbone[72] 上确实的能提高性能,但是,建立全局(非局部)依赖关系模型的显式机制可能是一种更强大和可扩展的解决方案,而不需要那么多层。
模型的长距离依赖在NLP的任务中也很重要。自注意机制是一种计算原语[64],它通过基于内容的寻址机制实现成对实体交互,从而在长序列中学习丰富的层次关联特征。这已经成为NLP中的标准工具:Transformer[64]块,突出的例子是GPT[48, 3]和BERT[13, 44]模型。
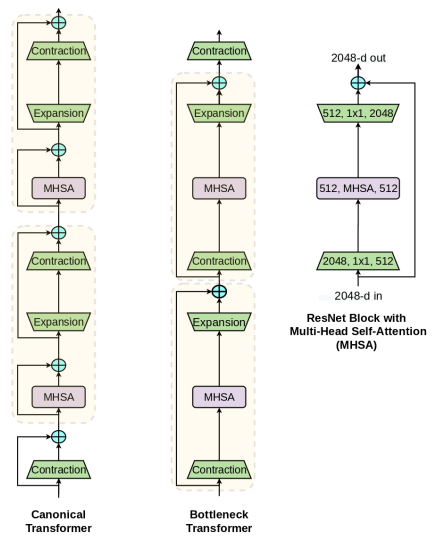
在视觉中使用自注意力机制的一个简单方法是用Transformer[64]中提出的多头自注意力机制(MHSA)层替换空间卷积层(如下左图)。最近,这种方法在两种看似不同的方法上取得了进展。一方面, SASA [51], SANet [73], Axial-SASA [66]等,提出用不同形式的自注意力机制(局部、全局、向量、轴向等)取代ResNet botleneck块[29]中的空间卷积。另一方面,有 Vision Transformer (ViT) [14], 它建议将Transformer blocks[64]堆叠在非重叠patches的线性投影上。这些方法可能呈现两种不同的体系结构。我们发现事实并非如此。相反,具有MHSA层的ResNet boteneck块可以被视为具有瓶颈结构、模次要差异(例如剩余连接)、可选的标准化层的Transformer块(右图)。鉴于这种等价性,我们将具有MHSA层的ResNet瓶颈块称为Bottleneck Transformer(BoT)块。

在视觉中使用自注意力机制有几个挑战:
- (1)与图像分类(224×224)相比,在目标检测和实例分割中,图像尺寸要大得多(1024×1024)。
- (2) 自注意力机制的记忆和计算与空间维度成二次比例[61],导致训练和推理的开销。
为了克服这些挑战,做了如下的设计:
- (1)利用卷积有效地从大图像中学习抽象的低分辨率特征图;
- (2)使用全局(all2all)自注意力机制来处理和聚合卷积捕获的featuremaps中包含的信息。
这样的混合设计:
- (1)使用现有的和优化的特征进行卷积和全局自注意力机制;
- (2)在高分辨率上使用处理高效的卷积、空间下采样等技术;在低分辨率上使用注意力机制。
下面是这个混合设计的一个简单实用的实例:
使用BoT块替换ResNet最后三个bottleneck blocks,其他层没有任何改变。也即我们只使用MHSA替换了3个(3 imes 3)卷积。这个改变在COCO数据集上 mask AP提升了(1.2\%)(使用了ResNet-50, 模型为Mask R-CNN)。这个结构我们称之为BoTNet。虽然我们注意到它的构造并不新颖,但我们相信它的简单性和性能使它成为一个有用的参考主干体系结构,值得研究。
使用BoTNet,我们是实例分割、目标检测上取得了显著的提升。关于其的几个关键结果为:
- (1)各种训练配置(第4.1节)、数据扩充(第4.2节)和ResNet系列主干(第4.5节)的性能增益;
- (2)BoTNet对小对象的显著增强(+2.4 mask AP和+2.6 box AP)(第4.4节,第A.3节);
- (3)非局部层的性能增益(第4.7节);
- (4)这种增益可以很好地扩展到更大的图像,从而产生44.4%的mask AP,在那些只研究骨干架构的项目中具有最先进的性能,这些项目的训练计划适中(最多72个epochs),并且没有额外的数据或扩充。
我们最后提出了简单的BoTNet架构调整,以在ImageNet基准[54]上获得良好的收益,因为我们注意到直接使用BoTNet并不能提供实质性的收益。基于该调整,我们设计了一簇BoTNet网络,并且在 ImagNet 的验证集上达到了(84.7\%)的 Top-1 精度,比受欢迎的 EffificientNet模型还快 (2.33 imes)。通过BoTNet提供强大的结果,我们希望自注意力机制成为未来视觉体系结构中广泛使用的基本元素。
2、相关工作
图2给出了一个将 self-attention 用于视觉的深度学习体系结构的分类。我们将关注以下三个方面:
- (1)Transformer vs BoTNet;
- (2)DETR vs BoTNet;
- (3)Non-Local vs BoTNet.
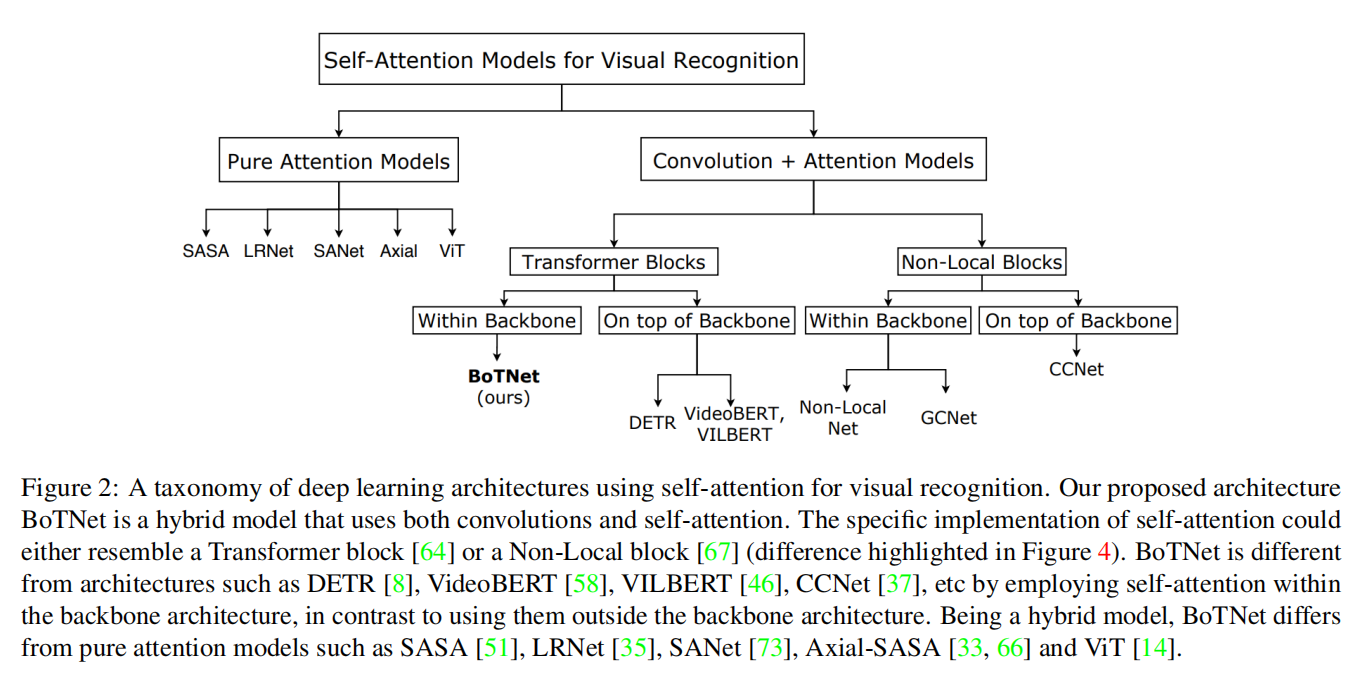
2.1 Connection to the Transformer
正如本文的标题所指出的,本文的一个关键信息是,具有MHSA层的ResNet瓶颈块可以被视为具有瓶颈结构的Transformer块。如1中的右图所示,我们称之为 Bottleneck Transformer (BoT)。这里要注意,图中的BoT块设计并不是我们的贡献。相反,我们指出了MHSA ResNet瓶颈块和Transformer之间的关系,希望它能提高我们对计算机视觉中self-attention的架构设计空间[49,50]的理解。除了图中已经显示的差异(剩余连接和块边界)之外,还有一些差异:
- (1)Normalization:Transformers 使用 Layer Normalization、 BoT blocks使用BN;
- (2)Non-Linearities:Transformers在FFN块中使用一个非线性,而ResNet结构允许BoT块使用三个非线性;
- (3)Output projections:Transformers中的MHSA块包含输出预测,而BoT块(图1)中的MHSA层(图4)不包含输出预测;
- (4)我们使用了视觉中常用的带动量的SGD优化器,而Transformers使用的是Adam优化器。
2.2 Connection to DETR
Detection Transformer (DETR) 是一种检测框架,它使用变换器来隐式地执行区域建议和对象定位,而不是使用R-CNN [21, 20, 53, 28]。DETR 与 BoTNet 都使用了self-attention提升目标检测和实例分割的性能。不同之处是DETR是在backbone之外使用的,以去除区域建议和非最大化抑制;另一方面,BoTNet的目标是提供一个主干架构,它使用 Transformer-like 的块进行检测和实例分割。我们不知道检测框架(无论是DETR还是R-CNN)。我们使用Mask[28]和faster R-CNN[53]系统进行了实验,并将其留给将来的工作,以便在DETR框架中集成 BoTNet 作为主backbone。由于BoTNet在小目标上的显著提升,我们相信,未来可能有机会解决DETR中小物体识别不佳的问题(第A.3节)。
2.3 Connection to Non-Local Neural Nets
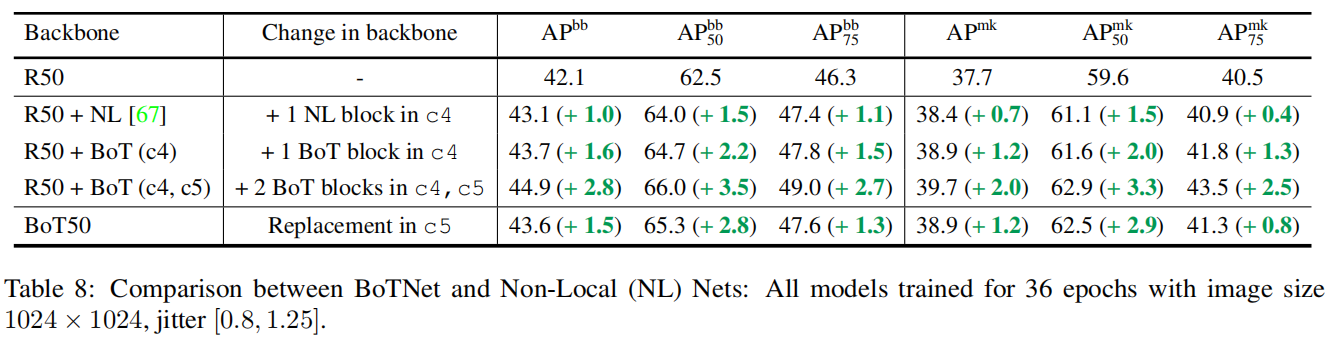
Non-Local(NL)网络 [67] Transformer与 Non-Local-Means(非局部均值滤波算法) 之间进行连接。他们将NL块插入最后一个或最后两个blockgroups (c4, c5),其提升了视频的目标检测与实例分割效果。与 NL 网络类似,僵尸网络是一种混合设计,使用卷积和全局self-attention。
-
关于NL layer 与 MHSA layer 的不同点:
-
MHSA使用了多头、值投影、位置编码
NL 块的每种实施都没有使用这几块的东西:https://github.com/facebookresearch/ImageNet-Adversarial-Training/blob/master/resnet_model.py#L92
-
-
NL块使用通道衰减因子为2的bottleneck(而不是采用ResNet结构的BoT块中的4);
-
NL块作为附加块插入到ResNet主干中,而不是像 BoTNet 那样替换现有卷积块。
第4.7节提供了BoTNet、NLNet以及NL-like的BoTNet版本之间的比较,其中我们以与NL块相同的方式插入BoT块,而不是替换。
3、方法
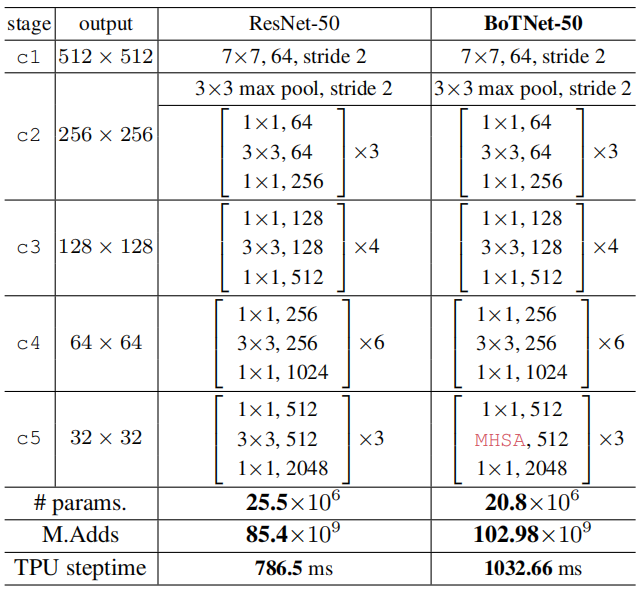
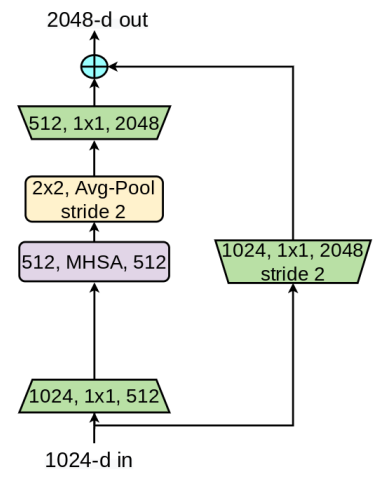
BoTNet的设计是简单的:在ResNet中使用MHSA替换最后三个(3 imes3)卷积,MHSA是在2D特征图上进行global (all2all) self-attention的实施(如图4)。ResNet有4个典型的stages:[c2,c3,c4,c5],相对于输入图像其步长为[4,8,16,32]。这些stages都是多个带残差连接的bottleneck 堆叠而成(如:R50有[3,4,6,3]个bottleneck blocks)。
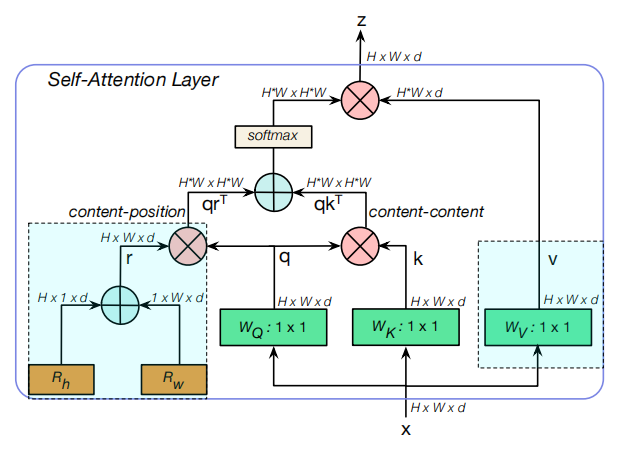

在整个backbone中使用self-attention的方法是可行的[51, 2, 73, 14] 。我们的目标是在实例分割模型中的高级语义阶段使用注意力机制,通常使用更高分辨率(1024×1024)的图像。考虑到(O(n^{2}d))的显存占用和计算量,我们认为遵循上述因素的最简单的设置是在主干中以最低分辨率的特征图将自我注意力结合起来,即这里的stage5。在c5这 Part,有3个残差块,每个残差块只有一个(3 imes3)卷积。使用MHSA层替换它们构成了BoTNet体系结构的基础。前一个使用步长为2,后两个使用步长为1。在第一个block中,因为BoT块没有stride操作,所以我们使用(2 imes2)的平均池化。 BoTNet的结构设计如上表所示,MHSA的示意图见图4,带步长操作的结构如下。
3.1 相对位置编码 Relative Position Encodings
为了使attention操作对位置感知,基于Transformer的架构通常使用位置编码[64]。最近研究发现,相对距离感知位置编码[55]更适合视觉任务[2,51,73]。这可归因于注意力不仅考虑了内容信息,而且还考虑了不同位置的特征之间的相对距离,从而能够有效地将跨对象的信息与位置感知相关联。在BoTNet中,我们采用了文献[51,2]中的二维相对位置self-attention实现。
4、实验
评价指标:
- ( m AP^{bb}) 超过IOU的平均值;
- ( m AP^{bb}_{50}) 、( m AP^{bb}_{75}) 、( m AP^{mk}) ; ( m AP^{mk}_{50})、( m AP^{mk}_{75});
4.1 BoTNet vs ResNet
设置训练策略:一个训练周期定义为12个epoch,以此类推。
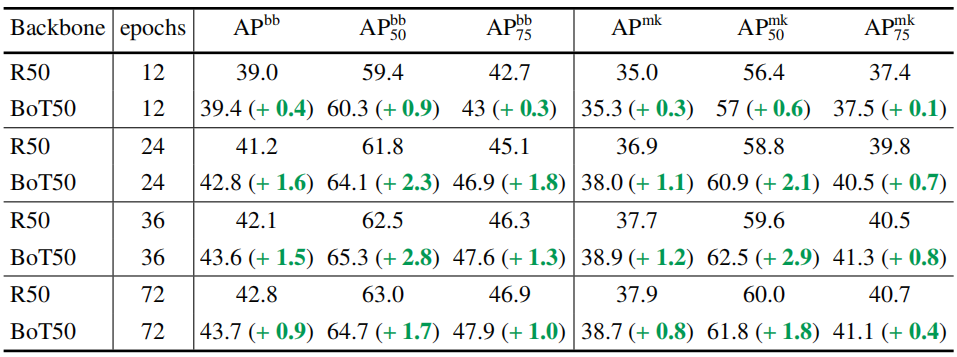
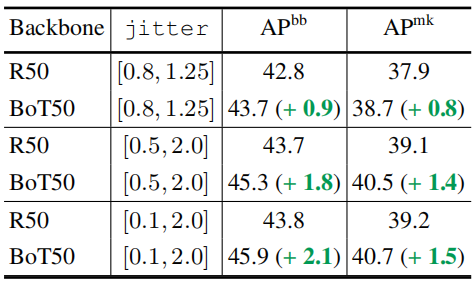
4.2 Scale Jitter对BoTNet的帮助更大
参考资料:https://www.zhihu.com/question/52157389
4.3 相对位置编码

4.4 stage5卷积替换实验
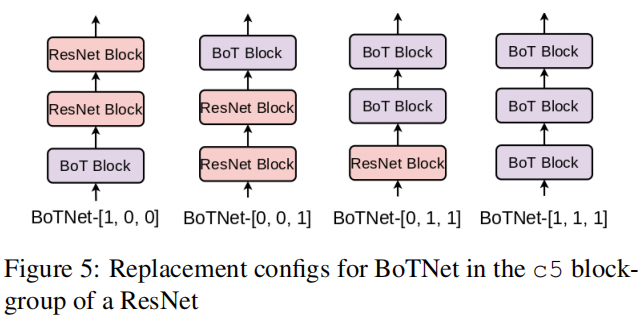
实验结果:

4.5 BoTNet提高了ResNet家族的骨干地位
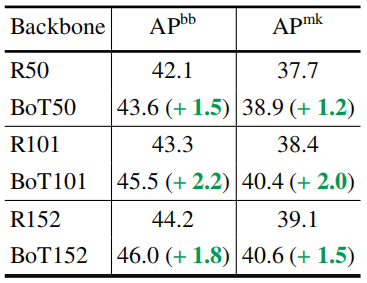
4.6 高分辨率上的BoTNet
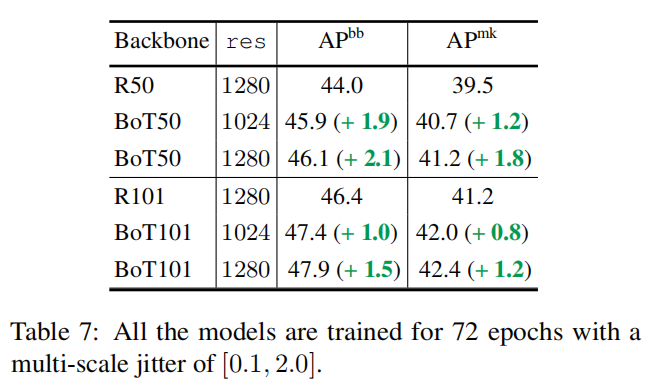
4.7 与NL网络的比较
参考链接:https://zhuanlan.zhihu.com/p/53010734
4.8 ImageNet的图像分类
4.8.1 BoTNet-S1 架构
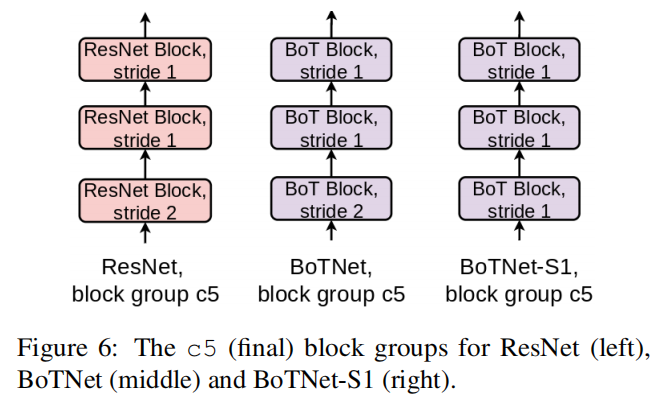
实验结果:
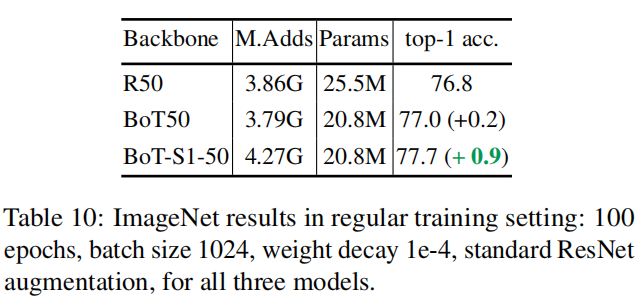
4.8.2 标准训练的评估
见上表。
4.8.3 数据增强和长时间训练的影响
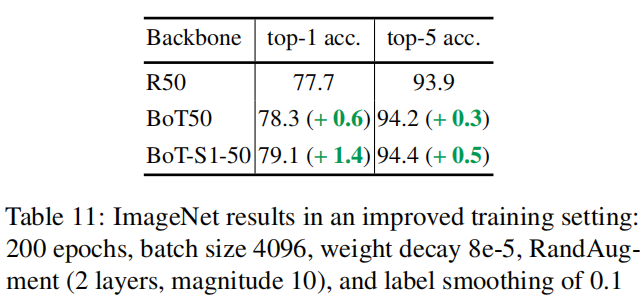
4.8.4 SE、SiLU的影响和低权值衰减
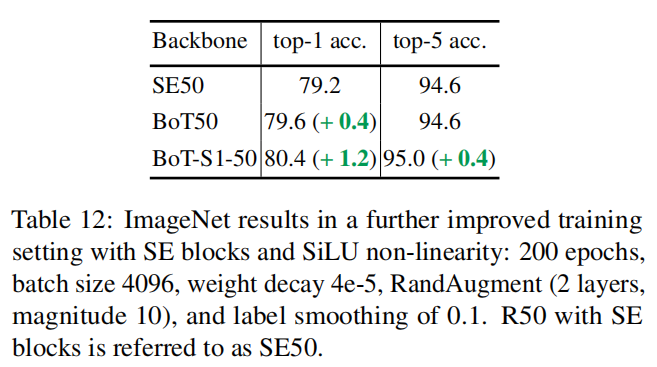
4.8.5 BoTNet vs EffificientNets
模型设置:
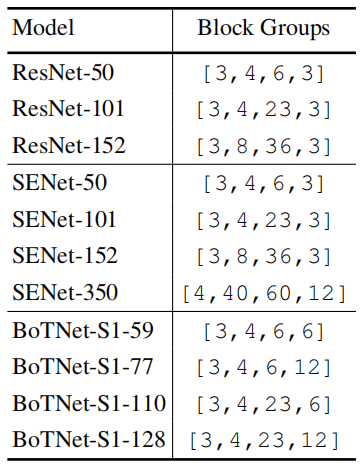
基于这些模型得出如下发现:
- 在更高精度的情况下(B4及以上),BoTNets在计算每个迭代的时间方面明显比EfficientNets更高效。
- ResNets 和 SENets 在较低精度的情况下表现非常好,优于EfficientNets和BoTNets(直到并包括B4)。
- 在M.Adds方面,EfficientNets可能比BoTNets更好,但在TPUs等最新硬件加速器上的映射不如BoTNets。对于几乎每一个EfficientNet模型,都存在一个更好的ResNet、SENet或BoTNet(精度相似,计算时间更高效)。
- BoTNet所需的输入图像大小比高效网络要小得多,这表明与深度可分离卷积相比,self-attention是一种更有效的上下文pooling操作。
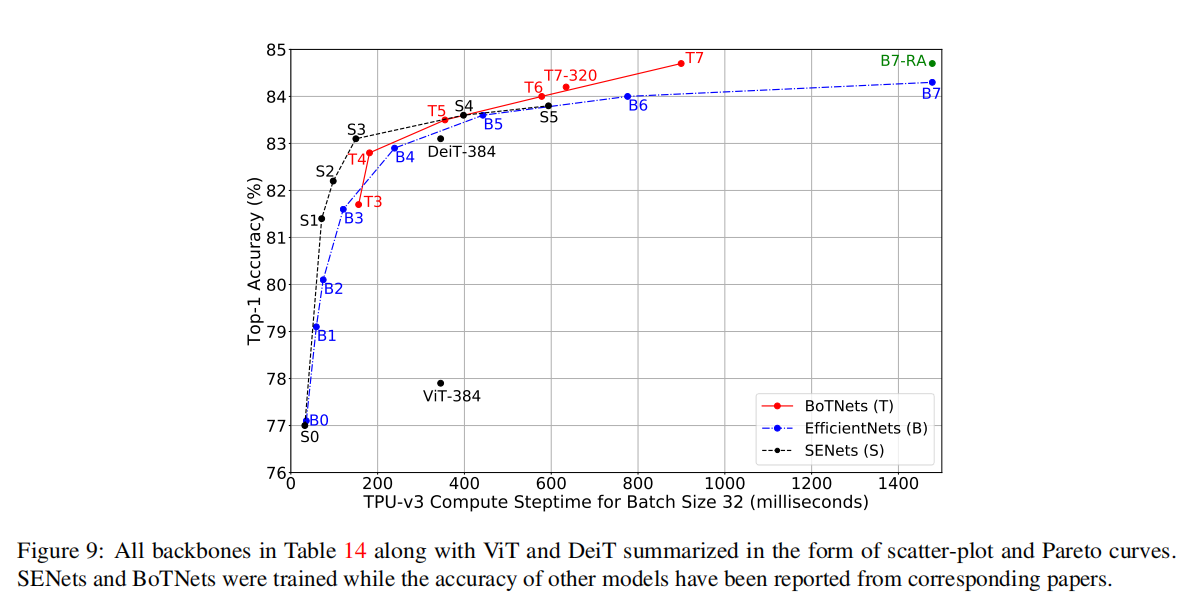
实验结果: (table 14)

4.8.6 ResNets 和 SENets是强大的baseline,精度达到(83\%)
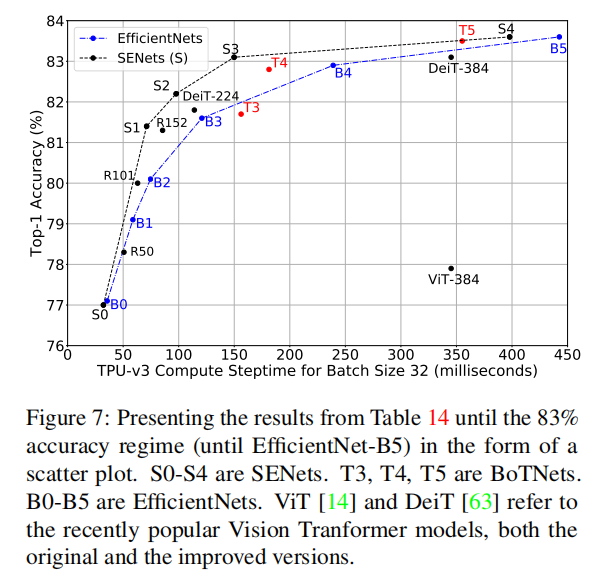
4.8.7 BoTNets是Top-1精度超过(83\%)的最好模型

三种模型的精度可视化:
4.9 讨论
如前几节所讨论的,SENets是一种功能强大的模型,性能比EfficientNets更好,可以一直扩展到83.8%的top-1精度,而无需任何诸如ResNet-D之类的工具, BoTNets最初的性能比SENets差(如T3),但从T4开始,它的性能开始取代SENets,并严格地优于EfficientNets,尤其是在接近尾声时。EfficientNets不能很好地扩展,特别是在更大的精度范围内。这无疑表明,EfficientNets中的复合缩放规则可能不够强大,而简单的深度缩放(如SENets和BoTNets中的深度缩放)工作得足够好。对所有这些模型类的缩放规则的更仔细的研究留给将来的研究。
最近,基于Transformer的视觉识别模型在视觉Transformer(ViT)模型出现后得到了广泛的应用[14]。虽然我们的论文是与ViT同时开发的,但是对ViT的许多后续研究,如DeiT[63],进一步改进了ViT的结果。从结果中可以看出,DeiT-384和ViT-384目前明显优于SENets和BoTNet。这表明卷积和混合(卷积和self-attention)模型仍然是很强的模型,可以击败ImageNet的基准测试。ViT中的信息是,纯注意模型在小数据(ImageNet)区域13中挣扎,但在大数据区域(JFT数据集)中闪耀,在大数据区域(JFT数据集)中,数据增强和正则化技巧等诱导性偏差在EfficientNet训练设置中使用并不重要。尽管如此,我们认为探索混合模型(如BoTNets)是一项有趣的工作,即使是在大数据环境下,这仅仅是因为它们似乎比SENets和EfficientNets具有更好的伸缩性,并且在ImageNet上实现了比DeiT更好的性能。我们将如此大规模的努力留给今后的工作。在大数据区域,也可以设计比ViT更具扩展性的纯注意模型,例如那些采用局部注意的模型,如SASA[51]。
我们还不清楚什么是正确的模型类别,因为我们还没有探索大数据区域中混合和局部注意模型的局限性,而且纯注意模型目前落后于小数据区域中的卷积和混合模型。尽管如此,希望IMANET的基准已经代表了视觉社区中表现最好的模型,BoTNet很可能是一个简单而令人信服的baseline。虽然为了简单起见,它们可能被视为混合ViT模型,但是在第2节中强调了BoT块如何不同于常规Transformer块,从而不同于ViT。
5、总结
使用self-attention的视觉backbone架构的设计是一个令人兴奋的话题。我们希望我们的工作有助于提高对架构设计的理解。如前所述,将我们的backbone与DETR[8]相结合并研究对小物体的影响是未来工作的一个有趣途径。将self-attention纳入其他计算机视觉任务,如关键点检测[7]和三维形状预测[23];研究计算机视觉中自我监督学习的self-attention结构[31、26、62、9、24、10];以及扩展到更大的数据集,如JFT、YFCC和Instagram,是未来研究的成熟途径。
完