目 录
1.预测和控制
预测
单值预测
区间预测
因变量新值的区间预测
因变量新值的平均值的区间估计
控制
2.回归系数的解释
3.回归应用的问题
预测和控制
建立回归模型的目的就是为了应用,回归模型最重要的应用是预测和控制。
一、 预测
1、 单值预测
单值预测就是用单个值作为因变量新值的预测值。比如研究某地区小麦单位产量y 与施肥量 x 之间的关系时,在 n 块单位面积的土地上各施肥量 xi,最后测得相应的产量 yi ,建立回归方程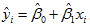 。某农户在一块单位面积的土地上施肥 x = x0 时,该块土地预期的小麦产量为
。某农户在一块单位面积的土地上施肥 x = x0 时,该块土地预期的小麦产量为
 (1)
(1)
此即因变量新值的单值预测。预测目标是一个随机变量,因而这个预测不能用无偏性来衡量。根据式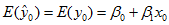 ,说明预测值
,说明预测值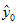 与目标值y0 有相同的均值。
与目标值y0 有相同的均值。
2、 区间预测
对于预测问题,除了知道预测值外,还希望知道预测的精度,这就需要做区间预测。即给出小麦产量的一个预测值范围。给一个预测值范围比只给出单值更可信。问题也就是:对于给定的显著性水平α,找一个区间(T1, T2),使对应于某特定的x0的实际值y0以 1-α 的概率被区间(T1, T2)所包含,用式子表示为
P(T1 < y0 < T2) = 1 – α. (2)
对因变量的区间预测又分为两种情况:一种是对因变量新值的区间预测,另一种是对因变量新值的平均值的区间预测。
(1)因变量新值的区间预测(y0 的置信区间)
首先计算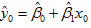 的分布,再利用独立的关系设置统计量。
的分布,再利用独立的关系设置统计量。
① 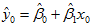 的分布
的分布
∵ 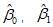 均为y1, y2, …, yn 的线性组合
均为y1, y2, …, yn 的线性组合
∴ 也是 y1, y2, …, yn 的线性组合
正态假定下 ~ 正态分布, 其期望值为
To : 计算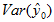
∵ 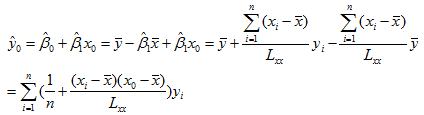
∴ 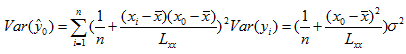
∴ 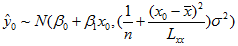 (3)
(3)
记
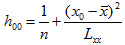 (4)
(4)
为新值x0的杠杆值,则(3)式简写为:
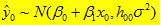 (5)
(5)
② 统计量
∵ 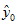 是用先前独立观测到的随机变量 y1, y2, …, yn 的线性组合
是用先前独立观测到的随机变量 y1, y2, …, yn 的线性组合
∴ 新值y0 与先前观测值独立
∴ y0 与是独立的
∴ 
∵ 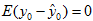
∴  (6)
(6)
进而可知统计量:
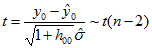 (7)
(7)
可得
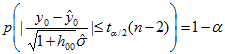 (8)
(8)
∴ y0 的置信水平为 1-α 的置信区间为
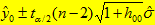 (9)
(9)
当样本容量 n 较大, 较小时,h00接近零,y0的置信水平为95%的置信区间近似为
较小时,h00接近零,y0的置信水平为95%的置信区间近似为
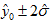 (10)
(10)
由公式(8)可以看出,当显著性水平α确定,样本容量 n 越大,Lxx越大,x0 越靠近x的均值,y0估计值的方差越小,则置信区间长度越短,此时的预测精度越高。
所以,为了提高预测精度,样本量 n 应越大越好,并且不能太集中。
预测时,x0 不能偏离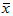 太大,当
太大,当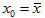 时,置信区间长度最短,此时预测结果最好。
时,置信区间长度最短,此时预测结果最好。
(2)因变量新值的平均值的区间估计
如果该地区的一大片麦地单位面积施肥量同为x0,那么这一大片地小麦的平均单位产量如何?此时的问题是,有多个相等的x0,则预测的平均y0是多少?即估计平均值E(y0)。
E(y0) 的点估计仍为 ,但是其区间估计却与因变量单个新值y0的置信区间式(9)不同。
,但是其区间估计却与因变量单个新值y0的置信区间式(9)不同。
∵ E(y0) = β0 + β1x0 是常数
∴ 由式(3)可知
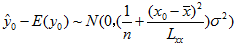 (11)
(11)
∴ 置信水平为 1-α 的置信区间为
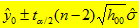 (12)
(12)
二、 控制问题
控制问题相当于预测的反问题。该问题为控制 x 使 y 在一定的范围内取值。
即要求 T1 < y < T2, 如何控制自变量 x ?
可以把问题描述为:控制 x 以 1-α 的概率保证把目标值 y 控制在 T1 < y < T2 中
p(T1 < y < T2) = 1 - α, 0 < α < 1
若 α = 0.05,由式(10)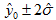 有
有
 (13)
(13)
将 代入上式(13)有:
代入上式(13)有:
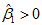 时:
时:
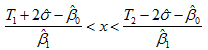 (14)
(14)
 时:
时:
 (15)
(15)
应用要求:因变量 y 与自变量 x 之间有因果关系。
回归系数的解释问题
对于回归方程 : 通常将
: 通常将 解释为:当自变量 x 增加或减少一个单位时,平均地说,y 增加或减少个单位。
解释为:当自变量 x 增加或减少一个单位时,平均地说,y 增加或减少个单位。
对于该解释需要加上几个前提条件才能正确:
◆ x 变化区间在模型内
◆ x 以外的因素对 y 的影响要相当
◆ x 与 y 一起观察所得,不由人事先控制,即x 处于合理的范围内,且必须“自然而然的”产生,而不是认为制造(比如研究身高体重,通过认为减肥来控制变量)
回归应用的问题
- 回归模型作为内插方程,在回归变量范围内用于拟合模型
内插预测:预测时,x 取值在建模时样本数据 x 的取值范围之内(效果好,误差小)
外推预测:预测时,x 取值超出了样本数据 x 的取值范围之内(效果可能不好)
因为建的回归方程是直线方程,而理论上回归方程一般并非是严格的直线。
2. 对 x值的处理在最小二乘拟合中扮演重要角色
所有点在决定回归直线高度中有着相等的权重,但斜率受 x 偏远点的影响更强烈,需要提出异常点作另外分析。
3. 离群点是与数据中的其他点有相当大区别的观测值,可以严重干扰最小二乘拟合,需要区分该点是由错误导致的坏值还是与探索过程相关的十分有用的证据。
4. 回归分析(处理相关性问题):两个变量之间存在强烈的关系,并不意味着变量间存在任何因果关系(必然性问题)。
5. 某些应用中,预测 y 需要的回归变量 x 的值是未知的。