在不断满足当前企业客户数据集成需求的同时,DataPipeline也基于Kafka Connect 框架做了很多非常重要的提升。
1. 系统架构层面。
DataPipeline引入DataPipeline Manager的概念,主要用于优化Source和Sink的全局化生命周期管理。当任务出现异常时,可以实现对目的端和全局生命周期的管理。例如,处理源端到目的端读取速率不匹配以及暂停等状态的协同。
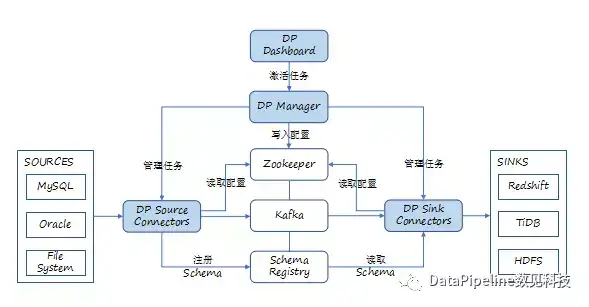
为了加强系统的健壮性,我们把Connector任务的参数保存在ZooKeeper中,方便任务重启后读取配置信息。
DataPipeline Connector通过JMX Client将统计信息上报Dashboard。在Connector中在技术上进行一些封装,把一些通用信息,比如说Connector历史读取信息,跟管理相关的信息都采集到Dashboard里面,提供给客户。
2. 任务并行模式。
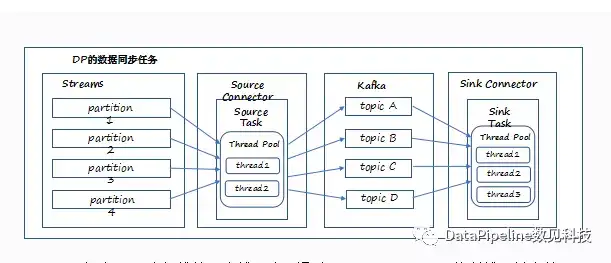
DataPipeline在任务并行方面做了一些加强。我们在具体服务客户的时候也遇到这样的问题,需要同步数十张表。在DataPipeline Connector中,我们允许每个Task内部可以定义和维护一个线程池,通过控制线程并发数,并且每个Task允许设置行级别的IO控制。而对于JDBC类型的Task,我们额外允许配置连接池的大小,减少上游和下游资源的开销。
3. 规则引擎。
DataPipeline在基于Kafka Connect做应用时的基本定位是数据集成。数据集成过程中,不应当对数据进行大量的计算,但是又不可避免地要对一些字段进行过滤,所以在产品中我们也在考虑怎样提供一种融合性。

虽然Kafka Connect提供了一个Transformation接口可以与Source Connector和Sink Connector进行协同,对数据进行基本的转换。但这是以Connector为基本单位的,企业客户需要编译后部署到所有集群的节点,并且缺乏良好的可视化动态编译调试环境支持。
基于这种情况,DataPipeline产品提供了两种可视化配置环境:基本编码引擎(Basic Code Engine)和高级编码引擎(Advanced Code Engine)。前者提供包括字段过滤、字段替换和字段忽略等功能,后者基于Groovy可以更加灵活地对数据处理、并且校验处理结果的Schema一致性。对于高级编码引擎,DataPipeline还提供了数据采样和动态调试能力。
4. 错误队列机制。
我们在服务企业客户的过程中也看到,用户源端的数据永远不会很“干净”。不“干净”的数据可能来自几个方面,比如当文件类型数据源中的“脏记录”、规则引擎处理特定数据产生未预期的异常、因为目的端Schema不匹配导致某些值无法写入等各种原因。
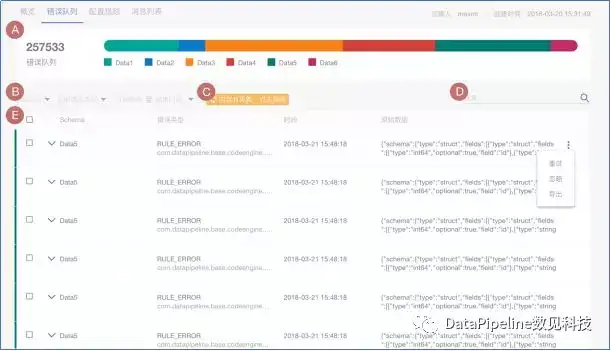
面对这些情况,企业客户要么把任务停下来,要么把数据暂存到某处后续再处理。而DataPipeline采取的是第二种方式,通过产品中错误队列预警功能指定面对错误队列的策略,支持预警和中断策略的设置和实施等,比如错误队列达到某个百分比的时候任务会暂停,这样的设置可以保证任务不会因少量异常数据而中断,被完整记录下来的异常数据可以被管理员非常方便地进行追踪、排查和处理。企业客户认为,相比以前通过日志来筛查异常数据,这种错误队列可视化设置功能大大提升管理员的工作效率。
在做数据集成的过程中,确实不应该对原始数据本身做过多的变换和计算。传统ETL方案把数据进行大量的变换之后,虽然会产生比较高效的输出结果,但是当用户业务需求发生变化时,还需要重新建立一个数据管道再进行一次原始数据的传输。这种做法并不适应当前大数据分析的需求。
基于这种考虑,DataPipeline会建议客户先做少量的清洗,尽量保持数据的原貌。但是,这并不是说,我们不重视数据质量。未来的重要工作之一,DataPipeline将基于Kafka Streaming将流式计算用于数据质量管理,它不对数据最终输出的结果负责,而是从业务角度去分析数据在交换过程中是否发生了改变,通过滑动窗口去判断到底数据发生了什么问题,判断条件是是否超出一定比例历史均值的记录数,一旦达到这个条件将进一步触发告警并暂停同步任务。
总结一下,DataPipeline经过不断地努力,很好地解决了企业数据集成过程需要解决异构性、动态性、可伸缩性和容错性等方面的问题;基于Kafka Connect的良好基础支撑构建了成熟的企业级数据集成平台;基于Kafka Connect进行二次封装和扩展,优化了应用Kafka Connect时面临的挑战:包括Schema映射和演进,任务并行策略和全局化管理等。未来,Datapipeline将会基于流式计算进一步加强数据质量管理。
更多关于实时数据集成和Kafka Connect的问题,欢迎直接访问官方网址申请试用:www.datapipeline.com