首先安装requests组件,用来访问网页。如果事先安装了anconda,也会有这个组件。
anaconda指的是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。因为包含了大量的科学包,Anaconda 的下载文件比较大(约 515 MB),如果只需要某些包,或者需要节省带宽或存储空间,也可以使用Miniconda这个较小的发行版(仅包含conda和 Python)。
Anaconda默认安装的包
4.3.0 默认安装的包


python-3.6.0-0 ... _license-1.1-py36_1 ... alabaster-0.7.9-py36_0 ... anaconda-client-1.6.0-py36_0 ... anaconda-navigator-1.4.3-py36_0 ... astroid-1.4.9-py36_0 ... astropy-1.3-np111py36_0 ... babel-2.3.4-py36_0 ... backports-1.0-py36_0 ... beautifulsoup4-4.5.3-py36_0 ... bitarray-0.8.1-py36_0 ... blaze-0.10.1-py36_0 ... bokeh-0.12.4-py36_0 ... boto-2.45.0-py36_0 ... bottleneck-1.2.0-np111py36_0 ... cairo-1.14.8-0 ... cffi-1.9.1-py36_0 ... chardet-2.3.0-py36_0 ... chest-0.2.3-py36_0 ... click-6.7-py36_0 ... cloudpickle-0.2.2-py36_0 ... clyent-1.2.2-py36_0 ... colorama-0.3.7-py36_0 ... configobj-5.0.6-py36_0 ... contextlib2-0.5.4-py36_0 ... cryptography-1.7.1-py36_0 ... curl-7.52.1-0 ... cycler-0.10.0-py36_0 ... cython-0.25.2-py36_0 ... cytoolz-0.8.2-py36_0 ... dask-0.13.0-py36_0 ... datashape-0.5.4-py36_0 ... dbus-1.10.10-0 ... decorator-4.0.11-py36_0 ... dill-0.2.5-py36_0 ... docutils-0.13.1-py36_0 ... entrypoints-0.2.2-py36_0 ... et_xmlfile-1.0.1-py36_0 ... expat-2.1.0-0 ... fastcache-1.0.2-py36_1 ... flask-0.12-py36_0 ... flask-cors-3.0.2-py36_0 ... fontconfig-2.12.1-2 ... freetype-2.5.5-2 ... get_terminal_size-1.0.0-py36_0 ... gevent-1.2.1-py36_0 ... glib-2.50.2-1 ... greenlet-0.4.11-py36_0 ... gst-plugins-base-1.8.0-0 ... gstreamer-1.8.0-0 ... h5py-2.6.0-np111py36_2 ... harfbuzz-0.9.39-2 ... hdf5-1.8.17-1 ... heapdict-1.0.0-py36_1 ... icu-54.1-0 ... idna-2.2-py36_0 ... imagesize-0.7.1-py36_0 ... ipykernel-4.5.2-py36_0 ... ipython-5.1.0-py36_0 ... ipython_genutils-0.1.0-py36_0 ... ipywidgets-5.2.2-py36_1 ... isort-4.2.5-py36_0 ... itsdangerous-0.24-py36_0 ... jbig-2.1-0 ... jdcal-1.3-py36_0 ... jedi-0.9.0-py36_1 ... jinja2-2.9.4-py36_0 ... jpeg-9b-0 ... jsonschema-2.5.1-py36_0 ... jupyter-1.0.0-py36_3 ... jupyter_client-4.4.0-py36_0 ... jupyter_console-5.0.0-py36_0 ... jupyter_core-4.2.1-py36_0 ... lazy-object-proxy-1.2.2-py36_0 ... libffi-3.2.1-1 ... libgcc-4.8.5-2 ... libgfortran-3.0.0-1 ... libiconv-1.14-0 ... libpng-1.6.27-0 ... libsodium-1.0.10-0 ... libtiff-4.0.6-3 ... libxcb-1.12-1 ... libxml2-2.9.4-0 ... libxslt-1.1.29-0 ... llvmlite-0.15.0-py36_0 ... locket-0.2.0-py36_1 ... lxml-3.7.2-py36_0 ... markupsafe-0.23-py36_2 ... matplotlib-2.0.0-np111py36_0 ... mistune-0.7.3-py36_0 ... mkl-2017.0.1-0 ... mkl-service-1.1.2-py36_3 ... mpmath-0.19-py36_1 ... multipledispatch-0.4.9-py36_0 ... nbconvert-4.2.0-py36_0 ... nbformat-4.2.0-py36_0 ... networkx-1.11-py36_0 ... nltk-3.2.2-py36_0 ... nose-1.3.7-py36_1 ... notebook-4.3.1-py36_0 ... numba-0.30.1-np111py36_0 ... numexpr-2.6.1-np111py36_2 ... numpy-1.11.3-py36_0 ... numpydoc-0.6.0-py36_0 ... odo-0.5.0-py36_1 ... openpyxl-2.4.1-py36_0 ... openssl-1.0.2k-0 ... pandas-0.19.2-np111py36_1 ... partd-0.3.7-py36_0 ... path.py-10.0-py36_0 ... pathlib2-2.2.0-py36_0 ... patsy-0.4.1-py36_0 ... pcre-8.39-1 ... pep8-1.7.0-py36_0 ... pexpect-4.2.1-py36_0 ... pickleshare-0.7.4-py36_0 ... pillow-4.0.0-py36_0 ... pip-9.0.1-py36_1 ... pixman-0.34.0-0 ... ply-3.9-py36_0 ... prompt_toolkit-1.0.9-py36_0 ... psutil-5.0.1-py36_0 ... ptyprocess-0.5.1-py36_0 ... py-1.4.32-py36_0 ... pyasn1-0.1.9-py36_0 ... pycosat-0.6.1-py36_1 ... pycparser-2.17-py36_0 ... pycrypto-2.6.1-py36_4 ... pycurl-7.43.0-py36_2 ... pyflakes-1.5.0-py36_0 ... pygments-2.1.3-py36_0 ... pylint-1.6.4-py36_1 ... pyopenssl-16.2.0-py36_0 ... pyparsing-2.1.4-py36_0 ... pyqt-5.6.0-py36_2 ... pytables-3.3.0-np111py36_0 ... pytest-3.0.5-py36_0 ... python-dateutil-2.6.0-py36_0 ... pytz-2016.10-py36_0 ... pyyaml-3.12-py36_0 ... pyzmq-16.0.2-py36_0 ... qt-5.6.2-3 ... qtawesome-0.4.3-py36_0 ... qtconsole-4.2.1-py36_1 ... qtpy-1.2.1-py36_0 ... readline-6.2-2 ... redis-3.2.0-0 ... redis-py-2.10.5-py36_0 ... requests-2.12.4-py36_0 ... rope-0.9.4-py36_1 ... scikit-image-0.12.3-np111py36_1 ... scikit-learn-0.18.1-np111py36_1 ... scipy-0.18.1-np111py36_1 ... seaborn-0.7.1-py36_0 ... setuptools-27.2.0-py36_0 ... simplegeneric-0.8.1-py36_1 ... singledispatch-3.4.0.3-py36_0 ... sip-4.18-py36_0 ... six-1.10.0-py36_0 ... snowballstemmer-1.2.1-py36_0 ... sockjs-tornado-1.0.3-py36_0 ... sphinx-1.5.1-py36_0 ... spyder-3.1.2-py36_0 ... sqlalchemy-1.1.5-py36_0 ... sqlite-3.13.0-0 ... statsmodels-0.6.1-np111py36_1 ... sympy-1.0-py36_0 ... terminado-0.6-py36_0 ... tk-8.5.18-0 ... toolz-0.8.2-py36_0 ... tornado-4.4.2-py36_0 ... traitlets-4.3.1-py36_0 ... unicodecsv-0.14.1-py36_0 ... wcwidth-0.1.7-py36_0 ... werkzeug-0.11.15-py36_0 ... wheel-0.29.0-py36_0 ... widgetsnbextension-1.2.6-py36_0 ... wrapt-1.10.8-py36_0 ... xlrd-1.0.0-py36_0 ... xlsxwriter-0.9.6-py36_0 ... xlwt-1.2.0-py36_0 ... xz-5.2.2-1 ... yaml-0.1.6-0 ... zeromq-4.1.5-0 ... zlib-1.2.8-3 ... anaconda-4.3.0-np111py36_0 ... ruamel_yaml-0.11.14-py36_1 ... conda-4.3.8-py36_0 ... conda-env-2.6.0-0 ...
C:UsersAdministrator>pip install requests
Collecting requests
Downloading requests-2.18.4-py2.py3-none-any.whl (88kB)
100% |████████████████████████████████| 92kB
19kB/s
Collecting chardet<3.1.0,>=3.0.2 (from requests)
Downloading chardet-3.0.4-py2.py3-none-any.whl (133kB)
100% |████████████████████████████████| 143k
B 27kB/s
Collecting idna<2.7,>=2.5 (from requests)
Downloading idna-2.6-py2.py3-none-any.whl (56kB)
100% |████████████████████████████████| 61kB
14kB/s
Collecting certifi>=2017.4.17 (from requests)
Downloading certifi-2018.1.18-py2.py3-none-any.whl (151kB)
100% |████████████████████████████████| 153k
B 24kB/s
Collecting urllib3<1.23,>=1.21.1 (from requests)
Downloading urllib3-1.22-py2.py3-none-any.whl (132kB)
100% |████████████████████████████████| 133k
B 13kB/s
Installing collected packages: chardet, idna, certifi, urllib3, requests
Successfully installed certifi-2018.1.18 chardet-3.0.4 idna-2.6 requests-2.18.4
urllib3-1.22
You are using pip version 8.1.1, however version 9.0.1 is available.
You should consider upgrading via the 'python -m pip install --upgrade pip' comm
and.
C:UsersAdministrator>
第一个爬虫代码
import requests
res = requests.get('http://mil.news.sina.com.cn/china/2018-02-23/doc-ifyrvspi0920389.shtml')
#设置编码为UTF-8
res.encoding='utf-8'
res1=res.text
print(res1)
分析
美丽汤解析器
获取到内容后我们不可能对所有内容进行观察分析,大部分情况下只对我们自己感兴趣或者有价值的内容进行抓取,在Python中我们用到BeautifulSoup4和jupter。美丽汤提供强大的选择器,其原理是构建的DOM树,结合各种选择器实现。
Successfully installed BeautifulSoup4-4.6.0 MarkupSafe-1.0 Send2Trash-1.5.0 bleach-2.1.2 colorama-0.3.9 decorator-4.2.1 entrypoints-0.2.3 html5lib-1.0.1 ipykernel-4.8.2 ipython-6.2.1 ipython-genutils-0.2.0 ipywidgets-7.1.2 jedi-0.11.1 jinja2-2.10 jsonschema-2.6.0 jupyter-1.0.0 jupyter-client-5.2.2 jupyter-console-5.2.0 jupyter-core-4.4.0 mistune-0.8.3 nbconvert-5.3.1 nbformat-4.4.0 notebook-5.4.0 pandocfilters-1.4.2 parso-0.1.1 pickleshare-0.7.4 prompt-toolkit-1.0.15 pygments-2.2.0 python-dateutil-2.6.1 pywinpty-0.5.1 pyzmq-17.0.0 qtconsole-4.3.1 simplegeneric-0.8.1 six-1.11.0 terminado-0.8.1 testpath-0.3.1 tornado-4.5.3 traitlets-4.3.2 wcwidth-0.1.7 webencodings-0.5.1 widgetsnbextension-3.1.4 win-unicode-conso
le-0.5
ID选择器
import requests
from bs4 import BeautifulSoup
res = requests.get('http://test.shtml')
#设置编码为UTF-8
res.encoding='utf-8'
res1=res.text
#将内容放进汤内
# #由于是id选择器,所以要加#。
# soup = BeautifulSoup(res1,'html.parser')
# soupres = soup.select('#main_title')[0].text
# print(soupres)
类选择器
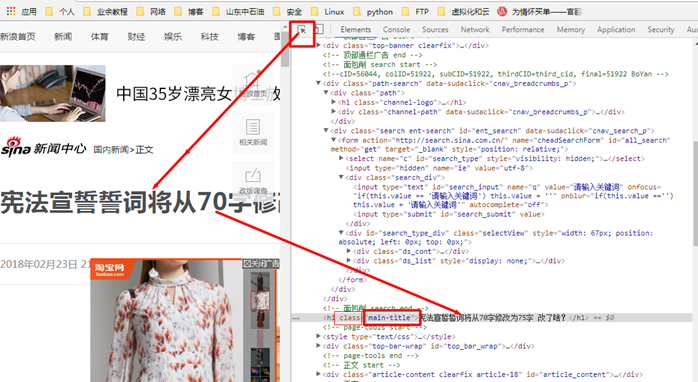
此处标题有class类,我们选择class,如果没有class有id,也可以选择id
import requests
from bs4 import BeautifulSoup
res = requests.get('http://news.sina.com.cn/c/nd/2018-02-24/doc-ifyrvaxe9482255.shtml')
#设置编码为UTF-8
res.encoding='utf-8'
res1=res.text
#类选择器
# #由于是id选择器,所以要加"."。
soup = BeautifulSoup(res1,'html.parser')
soupres = soup.select('.main-title')[0].text
print(soupres)
#links= soup
标签选择器
针对元素标签的选择器,可以理解为关键词。例如选出所有在test标签中的内容
titils = soup.select('test')
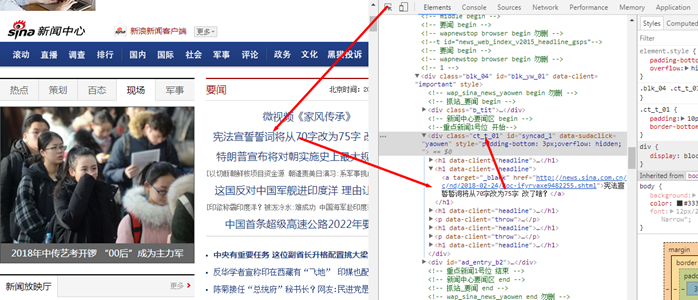
获取a标签中的链接
import requests
from bs4 import BeautifulSoup
res = requests.get('http://news.sina.com.cn/')
#设置编码为UTF-8
res.encoding='utf-8'
res1=res.text
soup = BeautifulSoup(res1,'html.parser')
soupres = soup.select('.ct_t_01 h1 a')[1]['href']#通过href取出超链接
soupres1 = soup.select('.ct_t_01 h1 a')[1].text#通过tag中的text方法取出汉子
print(soupres,soupres1)
抓取新闻列表
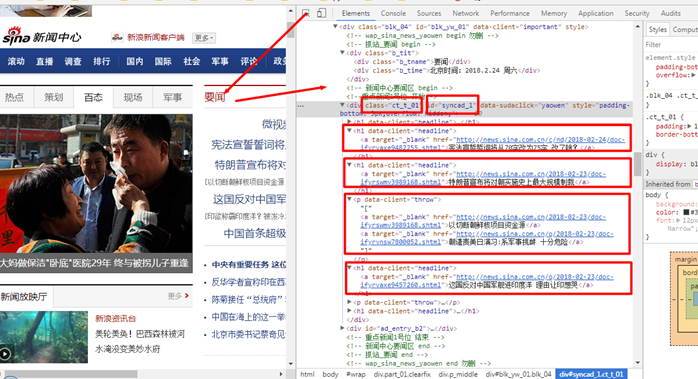
# 抓取新闻列表
import requests
from bs4 import BeautifulSoup
res = requests.get('http://news.sina.com.cn/')
#设置编码为UTF-8
res.encoding='utf-8'
res1=res.text
soup = BeautifulSoup(res1,'html.parser')
#soupres = soup.select('.ct_t_01 h1 a')#指定class,h1和a为标签
soupres = soup.select('#syncad_1 h1 a')#指定ID
#print(soupres)
for title in soupres:
print(title.text,title['href'])
抓取新闻正文内容
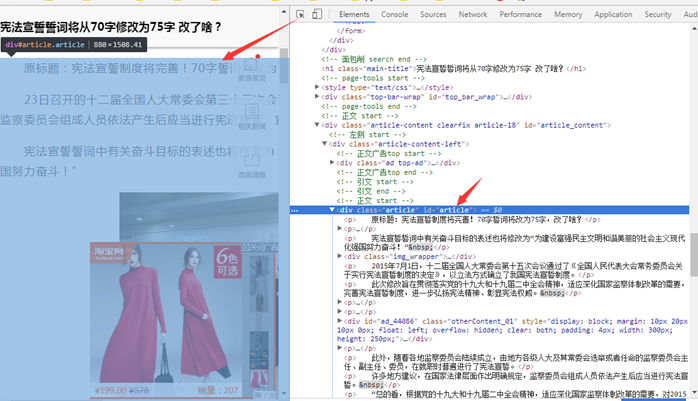
import requests
from bs4 import BeautifulSoup
res = requests.get('http://news.sina.com.cn/c/nd/2018-02-24/doc-ifyrvaxe9482255.shtml')
#设置编码为UTF-8
res.encoding='utf-8'
res1=res.text
soup = BeautifulSoup(res1,'html.parser')
soupres = soup.select('#article p')
#打印出内容
for title in soupres:
print(title.text)
获取新闻标题,责任编辑、来源和时间
# 获取新闻标题,责任编辑、来源和时间
import requests
from bs4 import BeautifulSoup
result = {}
res = requests.get('http://news.sina.com.cn/c/nd/2018-02-24/doc-ifyrvaxe9482255.shtml')
#设置编码为UTF-8
res.encoding='utf-8'
res1=res.text
soup = BeautifulSoup(res1,'html.parser')
soupres = soup.select('#article p')
content = ''
# 取出内容
for article in soupres[:-1]:#[-1}去掉最后一行
content = content + article.text
result['content']=content
# 取出标题
title = soup.select('.main-title')[0].text
result['title']=title
# 取出作者
article_editor = soup.select('.show_author ')[0].text
result['editor'] = article_editor
# 取出时间,来源
date = soup.select('.date')[0].text
source = soup.select('.source')[0].text
result['date'] = date
result['source'] = source
print(result)
抓取文章评论数
<span class="num" node-type="comment-num">915</span>
通过上述取class标签方法抓取的结果:
[<span class="num" node-type="comment-num">0</span>, <ul class="num"></ul>, <ul class="num"></ul>]
因为评论数比较特殊,是JavaScript的一个异步url请求的一个结果
URL请求的链接放置目录:

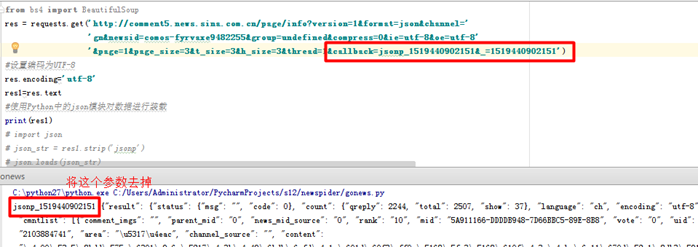
# 抓取文章评论数
import requests
from bs4 import BeautifulSoup
res = requests.get('http://comment5.news.sina.com.cn/page/info?version=1&format=json&channel=gn&newsid=comos-fyrvaxe9482255&group=undefined&compress=0&ie=utf-8&oe=utf-8&page=1&page_size=3&t_size=3&h_size=3&thread=1')
#设置编码为UTF-8
res.encoding='utf-8'
res1=res.text
#使用Python中的json模块对数据进行装载
#print(res1)
import json
json_load = json.loads(res1)['result']['count']['total']
print(json_load)
一个整合
# # 获取新闻标题,责任编辑、来源和时间
import requests
from bs4 import BeautifulSoup
result = {}
res = requests.get('http://news.sina.com.cn/c/nd/2018-02-24/doc-ifyrvaxe9482255.shtml')
#设置编码为UTF-8
res.encoding='utf-8'
res1=res.text
soup = BeautifulSoup(res1,'html.parser')
soupres = soup.select('#article p')
content = ''
# 取出内容
for article in soupres[:-1]:#[-1}去掉最后一行
content = content + article.text
result['content']=content
# 取出标题
title = soup.select('.main-title')[0].text
result['title']=title
# 取出作者
article_editor = soup.select('.show_author ')[0].text
result['editor'] = article_editor
# 取出时间,来源
date = soup.select('.date')[0].text
source = soup.select('.source')[0].text
result['date'] = date
result['source'] = source
# 取出评论数
import json
# json_str = res1.strip('jsonp')
res = requests.get('http://comment5.news.sina.com.cn/page/info?version=1&format=json&channel=gn&newsid=comos-fyrvaxe9482255&group=undefined&compress=0&ie=utf-8&oe=utf-8&page=1&page_size=3&t_size=3&h_size=3&thread=1')
res2 = res.text
json_load = json.loads(res2)['result']['count']['total']
result['talk'] = json_load
print(result)