如果有新知识,需要完善的知识,本人表达错误的地方,等等。欢迎大家留言,一起进步。
在博客 java-完整项目搭建 中有具体应用。
章节目录:
一:基础
二:持久化
三:架构
四:搭建
五:与springboot整合
一:基础
k.v形式,基于内存,支持多种类型。
具体的参考网络上资料。
二:持久化
2.1 为什么持久化?
redis是基于内存的数据库,所以在机器宕机,或者服务重启,内存数据就不在了,所以需要持久化到磁盘。
2.2 一定要持久化吗?
如果不持久化,那么就相当于要重新查数据,缓存数据了。
如果持久化了,重启服务时候恢复了之前持久化的数据,那么redis就接着之前的继续使用了。
2.3 怎么持久化?
2.3.1 持久化的方式
有两种:RDB(默认方式)与AOF(默认是关闭的)
1:RDB方式(数据快照)
1.1 在默认情况下,Redis 将数据快照保存在名字为 dump.rdb的二进制文件中,启动redis时候加载dump.rdb文件即可。
1.2 执行方式
1,阻塞方式(即 save ,阻塞Redis服务,无法响应客户端请求,好处是数据不丢失):
过程:客户端中发起save命令 -->
服务端停止客户端的服务请求,创建新的rdb文件,然后替换掉旧文件 -->
服务端恢复客户端的服务请求。

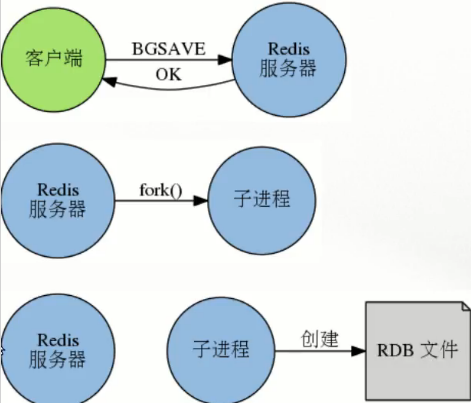
2,非阻塞方式(即 bgsave ,坏处是可能造成数据丢失)
过程:客户端发起bgsave命令 -->
服务端会 fork() (创建)一个子进程 -->
这个子进程开始创建rdb文件 -->
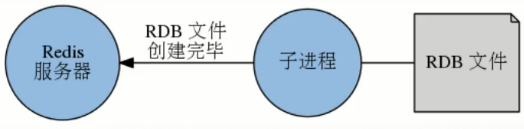
创建完成通知父进程 -->
父进程将新的rdb文件替换旧文件。
1.3 执行策略
1,自动(本质为bgsave)
默认的配置(配置文件 redis.conf 中):(只要满足下面三个的任意一个就会执行持久化操作)
save 900 1
save 300 10
save 60 10000
创建rdb文件之后,时间计数器和次数计数器会清零。所以多个条件的效果不是叠加的。
说明:例如 save 60 1000,Redis要满足在60秒内至少有1000个键被改动,会自动保存一次;
2,手动
在客户端发起save,bgsave命令
3,比较save,bgsave
save 不用创建新的进程,速度略快,但是会阻塞,不适合线上运行。
bgsave 需要创建子进程,消耗额外的内存,但是是非阻塞,适合线上运行。
1.4 优缺点
优点
可以设置rdb文件的归档时间,可以恢复到不同的版本;
单一的rdb文件,很容易远程传输,适合灾难恢复;
恢复大数据集速度比AOF快;
缺点
会丢失最近写入、修改的而未能持久化的数据;
fork过程较为耗时,会造成毫秒级客户端请求的延迟;
2:AOF方式(日志的记录方式)
2.1 默认文件appendonly.aof,记录所有的写操作命令,在服务启动的时候使用这些命令就可以还原数据库,
调整AOF持久化策略,可以在服务出现故障时,不丢失任何数据,也可以丢失一秒的数据。相对于RDB损失小得多
2.2 执行机制
1 AOF写入机制
1.1:什么是写入机制:
日志先写入内存缓冲区(buffer),等buffer满了,或者执行fsync或fdatasync时写入磁盘appendonly.aof文件。所以如果内存缓冲区的数据未写入磁盘时宕机,
那么就会数据丢失。
1.2:写入磁盘的策略:(appendfsync选项控制,选项值有:always、everysec、no)
always:(运行速度慢,不会产生数据丢失)
服务器写入一个指令就调用一次fdatasync,即写入磁盘。
everysec:(默认选项,运行速度快,如果宕机可能会丢失1s的数据)
服务器每1s就执行一次fdatasync。
no:(运行速度快,丢失数据有不确定性)
服务器不会主动调用fdatasync,由操作系统决定何时调用。
2 AOF重写机制
2.1:什么是重写机制:
aof文件中会写入很多重复的命令,导致文件也会很大。重写机制会合并一些重复的命令,使用尽量少的命令记录。
2.2:重写过程
首先fork(创建)一个子进程负责重写aof工作。
子进程创建一个临时文件用于写入aof信息。
父进程开辟一个内存缓冲区写入新的aof命令。
子进程重写好aof文件之后,会通知父进程,父进程再把缓冲区新的aof命令交由子进程写入新临时文件。新临时文件会替换旧临时文件。
注意:如果中途发生故障,可以通过redis-check-aof工具修复。
2.3 重写机制触发方式
1,手动
客户端向服务端发出bgrewriteaof命令
2,自动(通过配置文件中选项,自动执行bgrewriteaof命令)
auto-aof-rewrite-min-size <size>:(触发AOF重写所需的最小体积)
只要在AOF文件的体积大于等于size时,才会考虑是否需要进行AOF重写,这个选项用于避免对体积过小的AOF文件进行重写
auto-aof-rewrite-percentage<percent>:(指定触发重写所需的AOF文件体积百分比)
实际上就是对AOF的一个扩容,即当aof达到一个程度没办法再进行压缩重写时候,就按照这个比例对AOF扩容
举例:
auto-aof-rewrite-min-size 64mb 当AOF文件大于64MB时候,可以考虑重写AOF文件
auto-aof-rewrite-percentage 100 只有当AOF文件的增量大于起始size的100%时(就是文件大小翻了一倍),启动重写
appendonly no 或者 yes 默认关闭,请开启
2.3 优缺点
优点:
写入机制,默认fysnc每秒执行,性能很好不阻塞服务,最多丢失一秒的数据;
重写机制,优化AOF文件;
缺点:
相同数据集,AOF文件体积较RDB大很多;
恢复数据库速度叫RDB慢(文本,命令重演);
开启AOF操作后,默认不再使用RDB作为备选,但二者仍然可以同时开启;
三:架构(2.0版本架构与3.0版本架构)
1:2.0版本架构(主从架构)
1.1 角色
主节点(master):增删改查(指的是处理客户端请求)
从节点(slaves):查(可以处理客户端的查询请求)
高可用(Sentinel 哨兵):实现主从的转换等,可以监控多个集群,哨兵需要做HA
1.2 集群配置:参考网络资料
1.3 哨兵搭建
1.3.1:Sentinel 配置文件说明:
port 26379 //哨兵默认的端口号是26379
sentinel monitor mymaster 127.0.0.1 6379 2 //sentinel monitor哨兵监控
//mymaster 要监控的集群名称(随便起的,用来区分)
//127.0.0.1 6379监控的master
//2两个哨兵同意才重新选举master
1.3.2:Sentinel 配置举例
1 cp src/redis-sentinel redis/bin //将redis的哨兵执行文件cp到bin下
2 创建目录,在目录下创建配置文件(此处创建3个哨兵,需要3个配置文件)
找个目录下创建sentinel1.conf,sentinel2.conf,sentinel3.conf:
sentinel1.conf的内容为:
port 26379
Sentinel monitor s1 127.0.0.1 6380 2 //哨兵监控s1这个集群的6380的这个,2个哨兵同意之后就可以主从切换
sentinel2.conf的内容为:
Port 26380
Sentinel monitor s1 127.0.0.1 6380 2
Sentinel3.conf的内容为:
Port 26381
Sentinel monitor s1 127.0.0.1 6380 2
3 启动redis集群(到创建三个配置文件的目录下)
$redis-sentinel sentinel1.conf
$redis-sentinel sentinel2.conf
$redis-sentinel sentinel3.conf
1.4 存在的问题
问题1:从节点掉线,读能力下降
问题2:主节点掉线,写能力缺失(解决:可以使用哨兵)
问题3:只有一个主节点才有写的能力,所以写的性能是个问题
解决思路:让多个节点处理。
使用:twemproxy(代理模式,具体可以查询网络资料,本人觉得3.0版本架构更胜一筹)。
2:3.0版本架构(集群架构)
2.1 架构
由多个节点的redis集群组成,每个节点上都有master(用于存储数据)与slave(是master的复制品,可以有多个副本)
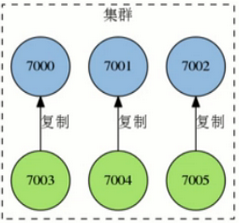
图中:7000 7001 7002为主节点,7003 7004 7005为相对应的复制节点
问题:如果7000掉线,怎么切换到7003的呢?这里就不用sentinel(哨兵)了,由集群中其他master决定,即7001 7002。
2.2 数据存储方式(槽位的形式,分担了数据写的压力)
集群分片说明:Slot(槽位),集群将整个数据库分为16384个槽位,有多少个集群节点,就会来平分这些槽位。
举个栗子:有个数据进来了,那么我们去到key值,通过公式 crc16(key)%16384 (crc16为16位的循环冗余校验和函数,我也不懂...,就是一个函数),
来计算出槽位,然后找个处理这个数据对应的节点是哪个。
四:搭建(搭建版本3.0版本)
1 安装与环境:
1、创建目录redis-cluster,在redis-cluster下解压安装redis3.0(tar xf redis.....gz);
2、在redis的目录下安装redis3.0(make && make PREFIX=/opt/redis install)意思是将redis安装到/opt/redis目录下;
3、安装ruby编译环境(ruby脚本进行槽位的分发)
# yum -y install ruby rubygems
4、在redis-cluster安装目录下安装 redis gem 模块(安装gem块进行槽位分发)
# gem install --local redis-3.3.0.gem(生成出 redis-trib.rb 文件)
2 搭建:
5、创建配置文件 redis.conf :
步骤:
mkdir cluster-test
cd cluster-test
mkdir 7000 7001 7002 7003 7004 7005
在7000-7005每个目录中均放入redis的redis.conf
redis.conf内容如下:
cluster-enabled yes //集群方式集群
port 700X //这台的端口
说明:
指定3个主节点端口为7000、7001、7002,对应的3个从节点端口为7003、7004、7005
5、创建配置文件redis.conf(启集群模式: 3.0 支持单机集群,但必须在配置文件中说明) (已完成)
指定不冲突的端口 及 <对应端口号>
文件内容:
声明支持集群模式,指定端口:
在7000-7005每个目录中均放入redis.conf
redis.conf内容如下:
cluster-enabled yes //集群方式集群
port 700X //这台的端口
6、创建集群,槽位认领
在安装目录下的src中,找到 redis-trib.rb 这是rubby脚本执行程序,完成redis3.0集群创建
# ./redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
执行之后,自动分配了主从,自动分配了slots,所有槽都有节点处理,集群状态上线
7、6个实例分别读取6个配置文件(启动redis)
# cd 700x
# redis-server redis.conf
8、查看运行状态
# ss -tanl | grep 700
9、客户端连接(一般应用是整合springboot使用)
# redis-cli -p 7000 -c
五:与springboot整合
1:jar包依赖(使用RedisTemplate工具包)
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2:application.properties文件配置
# Redis数据库索引(默认为0) spring.redis.database=0 # Redis服务器地址 spring.redis.host=127.0.0.1 # Redis服务器连接端口 spring.redis.port=6379 # Redis服务器连接密码(默认为空) spring.redis.password= # 连接池最大连接数(使用负值表示没有限制) spring.redis.pool.max-active=8 # 连接池最大阻塞等待时间(使用负值表示没有限制) spring.redis.pool.max-wait=-1 # 连接池中的最大空闲连接 spring.redis.pool.max-idle=8 # 连接池中的最小空闲连接 spring.redis.pool.min-idle=0 # 连接超时时间(毫秒) spring.redis.timeout=0
3:在@configuration中定义bean,可自定义连接工厂JedisConnectionFactory。
设置连接的集群,序列化设置等。(具体设置参考网络资料)
4:使用@Component创建工具类(这里只写引入redisTemplate方式)
@Component public class RedisService { //方式1:自动装配,使用时候需要创建对象 @Autowired private RedisTemplate<String, String> stringRedisTemplate; //方式2:创建静态的,使用时候直接使用即可 private static RedisTemplate<String, Object> objectRedisTemplate; @Autowired //方法名称是随意的 public void setObjectRedisTemplate(ObjectRedisTemplate objectRedisTemplate){ this.objectRedisTemplate = objectRedisTemplate; } }