1. 栈的定义
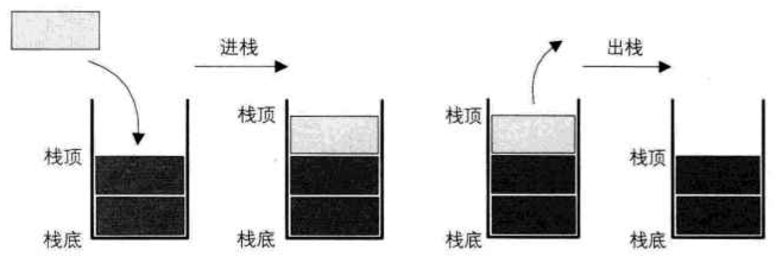
栈(stack):是限定仅在表尾进行插入和删除操作的线性表
栈顶(top)允许插入和删除的一端称为栈顶;另一端称为栈底(bottom)
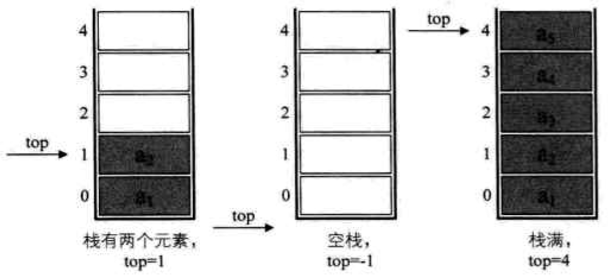
空栈:不包含任何数据元素的栈
栈又被称为后进先出(Last In First Out)的线性表,简称 LIFO 结构
栈的插入操作,叫做进栈,也称压栈,入栈
栈的删除操作,叫做出栈,也有的叫作弹栈
2. 栈的抽象数据类型
ADT 栈(stack) Data 同线性表。元素具有相同的类型,相邻元素具有前驱和后堆关系。 Operation InitStack ( *S ):初始化操作.建立一个空栈S。 DestroyStack ( *S ):若栈存在,則销毁它。 ClearStack (*S):将栈清空。 StackEmpty ( S ):若栈为空,返回true,否則返回 false。 GetTop (S,*e):若栈存在且非空,用e返回S的栈顶元素。 Push (*S,e):若栈S存在,插入新元素e到栈S中并成为栈頂元素。 Pop (*S,*e):删除栈S中栈顶元素,并用e返回其值。 StackLength (S):返回回栈S的元素个数。 endADT
3. 栈的顺序存储结构及实现
定义一个 top 变量来指示栈顶元素在数组中的位置
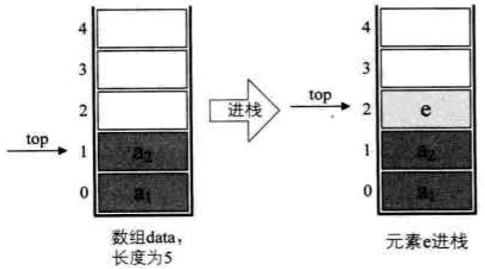
进栈操作
- 栈顶指针加一
- 将新插入元素赋值给栈顶空间
出栈操作
- 将要删除的栈顶元素赋值给 e
- 栈顶指针减一
进栈和出栈都未涉及循环语句,时间复杂度为 O(1)
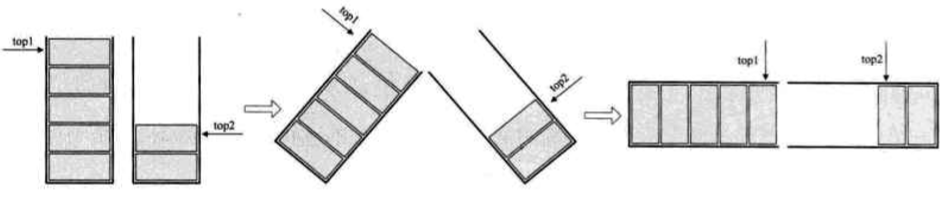
4. 两栈共享空间
数组有两个端点,两个栈有两个栈底,让一个栈的栈底为数组的始端,即下标为 0 处,另一个栈为栈的末端,即下标为数组长度 n-1 处
这样,两个栈如果增加元素,就使两端点向中间延伸
关键思路
- 它们是在数组的两端,向中间靠拢
- top1 和 top2 是栈 1 和栈 2 的栈顶指针
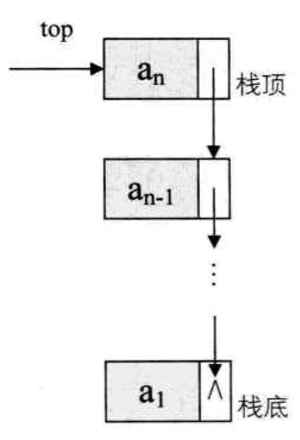
5. 栈的链式存储结构及实现
存储结构
- 把栈顶放在单链表的头部,已经有了栈顶在头部了,单链表中常用的头结点就失去了意义
- 通常对于链栈来说,是不需要头结点的
- 对于空栈来说,链表原定义是头指针指向空,那么链栈的空其实就是 top=NULL 的时候
进栈操作
- 假设元素值为 e 的新结点是 s,top 为栈顶指针
- 插入元素 e 为新的栈顶元素
- 把当前的栈顶元素赋值给新结点的直接后继,如图中 1
- 将新的结点 s 赋值给栈顶指针,如图中 2
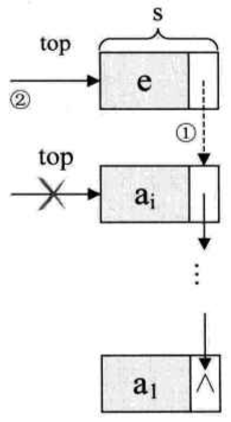
出栈操作
- 假设变量 p 用来存储删除的栈顶结点,将栈顶执政下移一位,最后释放 p 即可
- 将栈顶结点赋值给 p ,如图 3
- 使得栈顶指针下移一位,指向后一节点,如图 4
- 释放结点 p

链栈的进栈 push 和出栈 pop,时间复杂度均为 O(1)
顺序栈,需先确定一个固定的长度,可能会存在内存空间浪费问题;优势是存取时定位方便
链栈,要求每个元素都有指针域,这同时也增加了一些内存开销,但对于栈的长度无限制
选择
- 如果栈的使用过程中元素变化不可预料,有时很小,有时非常大,那么最好是用链栈
- 反之,如果他的变化在可控范围内,建议使用顺序栈会更好一些
6. 栈的作用
栈的引用简化了程序设计的问题,划分了不同关注层次,使得思考范围缩小,更加聚焦于我们要解决的问题核心
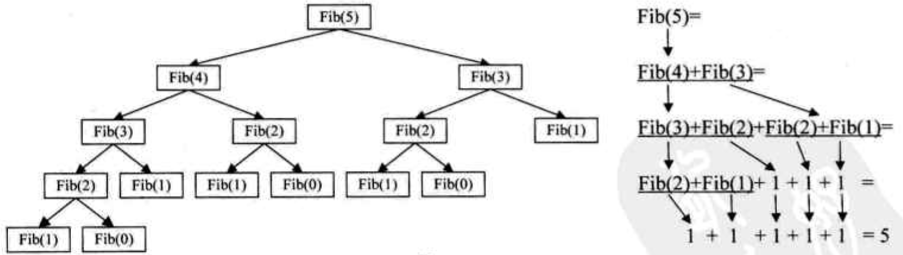
7. 栈的应用——递归
递归定义
-
一个直接调用自己或通过一系列的调用语句间接地调用自己的函数
-
每个递归定义必须至少有一个条件,满足时递归不再进行,即不再引用自身而是返回值退出
-
迭代和递归的区别
- 迭代使用的时循环结构,不需要反复调用函数和占用额外的内存
- 递归能使程序更清晰,更简洁,更易理解,从而减少读懂代码的时间
- 大量的递归调用会建立函数的副本,会耗费大量的时间和内存
8. 栈的应用——四则运算表达式求值
后缀(逆波兰)表示法定义
- 一种不需要括号的后缀表示法
- 所有的符号都是在要运算数字的后面出现
- ”9+(3-1)*3+10/2“ 的后缀表达式:”9 3 1 - 3 * + 10 2 / +“
后缀表达式计算结果
-
后缀表达式:9 3 1 - 3 * + 10 2 / +
-
规则
- 从左到右遍历表达式的每个数字和符号,遇到数字就进栈;遇到符号,就将处于栈顶两个数字出栈,进行运算,运算结果进栈,一直到最终获得结果
中缀表达式转后缀表达式
-
”9+(3-1)*3+10/2“,平时所用的这种标准四则运算表达式,叫做中缀表达式
-
中缀转后缀规则
- 从左到右遍历中缀表达式的每个数字和符号,若是数字就输出,即成为后缀表达式的一部分;
- 若是符号,则判断其与栈顶符号的优先级,是右括号或优先级低于栈顶符号(乘除优先于加减)则栈顶元素依次出栈并输出,并将当前符号进栈,一直到最终输出后缀表达式为止
-
中缀转化为后缀,栈用来进出运算的符号
-
后缀转化为中缀,栈用来进出运算的数字
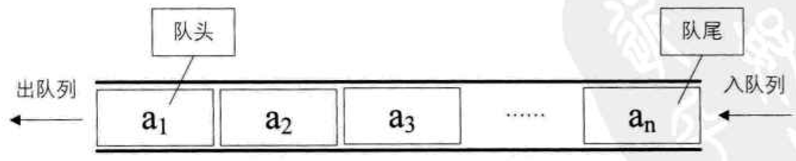
9. 队列的定义
队列(queue)是只允许在一端进行插入操作,而在另一端进行删除操作的线性表
队列是一种先进先出(First In First Out)的线性表,简称FIFO
允许插入的一端称为队尾,允许删除的一端称为队头

10. 队列的抽象数据类型
ADT 队列(Queue) Data 同线性表。元素具有相同的类型,相邻元素具有前驱和后继关系。 Operation InitQueue(*Q):初始化操作,建立一个空队列Q。 DestroyQueue(*Q):若队列Q存在,則销毀它。 ClearQueue(*Q):将队列 Q 清空。 QueueEmpty(Q):若队列Q为空,送回true,否則退回false。 GetHead(Q, *e):若队列Q存在且非空,用e返因队列Q的队头元素。 EnQueue(*Q,e):若队列Q存在,插入新元素e到队列Q中并成为队尾元素。 DeQueue(*Q, *e):刪除队列Q中队头元素,并用e返回其值。 QueueLength(Q):送回队列Q的元素个教。 endADT
11. 循环队列
不足
- 为了避免当只有一个元素时,队头和队尾重合使处理变得麻烦,所以引入两个指针
- front 指针指向队头元素,rear 指针指向队尾元素的下一个位置
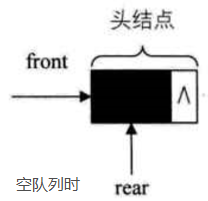
- 当 front 等于 rear 时,此队列不是还剩一个元素,而是空队列


定义
- 我们把队列的头尾相接的顺序存储结构称为循环队列
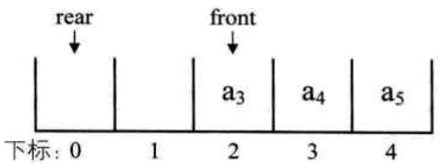
问题:当 front 等于 rear 时,如何判断此时队列是空还是满?

-
办法一
- 设置一个标志变量 flag,当 front == rear,且 flag = 0时为队列空,当 front == rear,且 flag = 1 时为队列满
-
办法二
- 当队列孔时,条件就是 front = rear,当队列满时,我们修改其条件,保留一个元素空间。
- 也就是说,队列满时,数组中还有一个空闲单元
- 若队列的最大长度为 QueueSize ,队列满的条件是:(reat + 1) % QueueSize == front

12. 队列的链式存储结构及实现
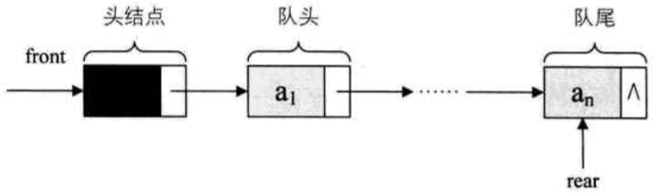
队列的链式存储结构,其实就是线性表的单链表,只不过它只能尾进头出而已,简称链队列
为了操作上的方便,我们将队头指针指向链队列的头结点
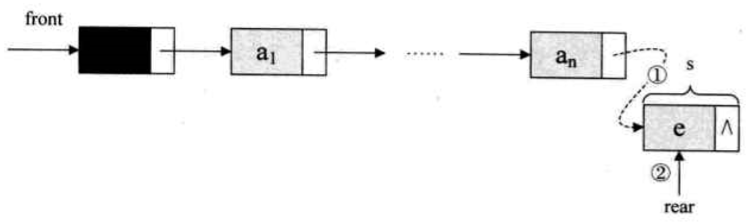
入队操作
- 在链表尾部插入结点
- 把拥有元素 e 新结点 s 赋值给原队尾结点的后继,如图 1
- 把当前的 s 设置为队尾结点,rear 指向 s,如图 2
出队操作
- 出队操作时,就是头结点的后继结点出队,将头结点的后继改为它后面的结点
- 若链表除头结点外只剩一个元素时,则需将 rear 指向头结点
