图结构在现实世界中随处可见。道路、社交网络、分子结构都可以使用图来表示。图是我们拥有的最重要的数据结构之一。
今天有很多的资源可以教我们将机器学习应用于此类数据所需的一切知识。
已经有很多学习有关图机器学习的相关理论和材料,特别是图神经网络,所以本文将避免在这里解释这些内容。如果你对该方面不太熟悉,推荐先看下CS224W,这会对你的入门有很大的帮助。
本篇文章使用PyTorch Geometric来实现我们需要的模型,所以首先就是安装
Cora 数据集
Cora 数据集包含 2708 篇科学出版物,分为七类之一。引用的网络由 5429 个链接组成。数据集中的每个出版物都由一个 0/1 值的词向量描述,该向量表示字典中对应单词是否存在。该词典包含1433个独特的单词。
首先让我们探索这个数据集以了解它是如何生成的:
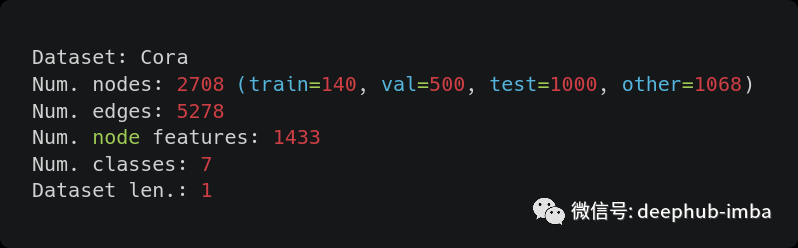
我们可以看到一些信息:
- 为了获得正确的边数,我们必须将数据属性“num_edges”除以2,这是因为 Pytorch Geometric “将每个链接保存为两个方向的无向边”。
- 这样做以后数字也对不上,显然是因为“Cora 数据集有重复的边”,需要我们进行数据的清洗
- 另一个奇怪的事实是,移除用于训练、验证和测试的节点后,还有其他节点。
- 最后就是我们可以看到Cora数据集实际上只包含一个图。
我们使用 Glorot & Bengio (2010) 中描述的初始化来初始化权重,并相应地(行)归一化输入特征向量。( Kipf & Welling ICLR 2017 arxiv:1609.02907)
完整文章: