1 概述
本实例主要使用Node.js去抓取电影的节目单,方便大家使用下载。
2 node package
- fs
- cheerio
- superagent
- superagent-charset
- express
- path
fs 用来读写文件
cherrio 类似jquery
superagent (ajax http模块)
superagent-charset 解决中文乱码问题
express 搭建server
path 路径
统一安装这些包,可以使用一下命令:
npm i express cheerio superagent superagent-charset path fs --save-dev
如果想深入了解这些包 可以去下面这个网址了解下
find package
3 步骤
第一步:
利用express 搭建本地服务
const app = require('express')();
const port = 3000;
app.get('/', (req, res)=>{
res.send('hello world');
});
app.listen(port, ()=>{
console.log('listening port on', port);
});
打开浏览器 输入 localhost:3000
看到下面页面,说明初步成功
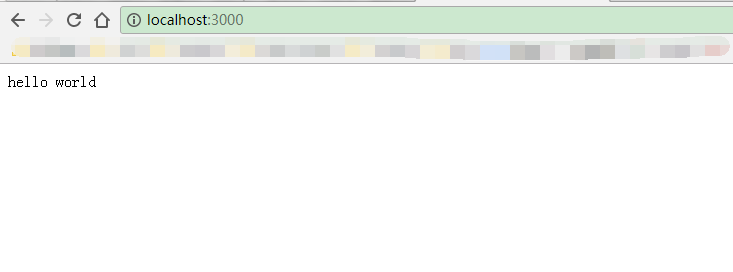
第二步
先试用superagent(http模块)去获取页面的数据,然后用cheerio(类似jquery)去获取页面数据。
具体代码如下
var item = [];
function getMovies() {
item = [];
var url = 'http://www.dytt8.net';
superagent.get(url + '/index.htm').charset().end((err, sres) => {
if (err) {
throw err;
}
var $ = cherrio.load(sres.text);
$('.bd3rl .co_area2').each(function (i, n) {
if (i > 1) return;
var $n = $(n);
var obj = {
name: $n.find('.title_all strong').text(),
data: []
};
$n.find('tr').each(function (i, m) {
var $m = $(m);
var childUrl = url + $m.find('.inddline').eq(0).find('a').eq(1).attr('href');
obj.data.push({
title: $m.find('.inddline').eq(0).text(),
href: url + $m.find('.inddline').eq(0).find('a').eq(1).attr('href'),
date: $m.find('.inddline').eq(1).text(),
download_url: ''
});
});
item.push(obj);
});
fs.writeFile(path.join(__dirname, './doc', 'dy.txt'), '', function () { });
item.forEach(n => {
n.data.forEach((m, i) => {
superagent.get(m.href).charset().end((err, cres) => {
var _$ = cherrio.load(cres.text);
var download_url = _$('#Zoom table a').text();
var title = _$('.bd3r .title_all').text();
title = title.substring(title.indexOf('《') + 1, title.indexOf('》'));
// console.log(title)
var total_movie = title + '~~' + download_url + '
';
// var total_movie = download_url.split(']')[1].substr(1) + '~~' + download_url + '
';
var buff = new Buffer(total_movie);
fs.appendFile(path.join(__dirname, './doc', 'dy.txt'), buff, function () { });
});
});
});
});
}
superagent.get()类似ajax get请求,cheerio.load() 类似jquery,获取数据的方法其实就是jquery的方法。
获取完首页的链接,一般我们需要进去详情页才能看得到ftp的地址,可是现在我们做了第二次的轮询请求,就直接得到了ftp的地址,无需进到详情页,节省很多时间。
最终我们会存到本地文件夹里
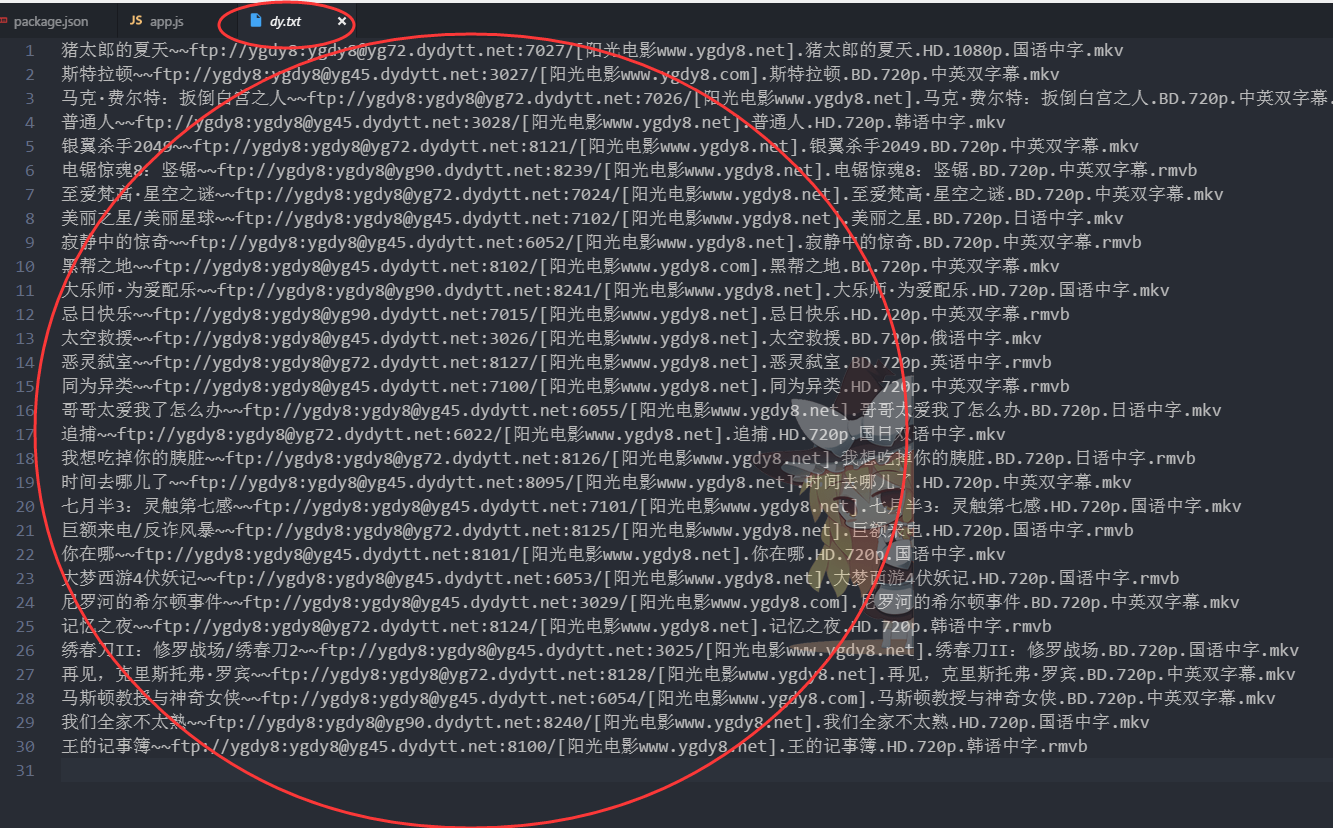
接下来我们会把这些数据呈现到页面中:

代码实现:
app.get('/dy', function (req, res, next) {
var url_data = [];
var img_url = 'https://raw.githubusercontent.com/huainanhai/EXE/master/sevenDay/doc/wz.jpg';
fs.readFile(path.join(__dirname, './doc', 'dy.txt'), 'utf-8', (err, data) => {
if (err) throw err;
url_data = data.split('
').filter(function (n) {
return n != '';
});
var str = '<div style="50%;">';
str += '<h4 style="padding-left:10px;">(温馨提示:复制ftp开头的路径到‘迅雷极速版’(邮件附件里面有)就会自动下载电影了, 最新免费电影节目单不定时更新,福利呦)</h4>'
item.forEach(m => {
str += '<h3 style="padding-left:10px;">' + m.name + '</h3>';
m.data.forEach((n) => {
url_data.forEach(j => {
var name = j.split('~~')[0];
name = name.split('.')[0];
if (n.title.indexOf(name) > -1) {
n.download_url = j.split('~~')[1];
}
});
str += '<div style="">' +
'<a href="' + n.href + '" style="height:30px;display:inline-block;vertical-align: middle;text-decoration:none;margin-left:6px;" target="_blank">' + n.title + '</a>' +
'<span style="height:30px;display:inline-block;vertical-align: middle;color: red;float:right;">' + n.date + '</span>' +
'</div>';
str += '<div style="background:#fdfddf;border:1px solid #ccc;padding:3px 10px;margin-bottom:10px;">' + n.download_url + '</div>';
});
});
str += '<img src="' + img_url + '" width="540" height="748" />';
str += '</div>';
res.send(str);
})
});
4 源码截图

如果要下载本实例,解压 然后 npm install 即可安装所需依赖包,下次我们讲解如果把数据发送到自己的邮箱(或者群发更多人的邮箱)!
Node.js 抓取电影天堂新上电影节目单及ftp链接
注:本文著作权归作者,由demo大师代发,拒绝转载,转载需要作者授权