1.1.urlopen函数的用法
#encoding:utf-8 from urllib import request res = request.urlopen("https://www.cnblogs.com/") print(res.readlines()) #urlopen的参数 #def urlopen(url, data=None, timeout=socket._GLOBAL_DEFAULT_TIMEOUT, # *, cafile=None, capath=None, cadefault=False, context=None):
1.2.urlretrieve函数
将网页上的文件保存到本地
#coding:utf-8 from urllib import request res = request.urlretrieve("https://www.cnblogs.com/",'cnblog.html') #urlretrieve参数 #def urlretrieve(url, filename=None, reporthook=None, data=None):
1.3.参数编码和解码函数
urlencode函数用于编码中文和特殊字符
#urlencode函数 # 简单用法 #from urllib import parse # data = {'name':'德瑞克','age':100} # qs = parse.urlencode(data) # print(qs) #name=%E5%BE%B7%E7%91%9E%E5%85%8B&age=100 #实际用例 from urllib import request,parse url = "http://www.baidu.com/s" params = {"wd":"博客园"} qs = parse.urlencode(params) url = url + "?" + qs res = request.urlopen(url) print(res.read())
parse_qs函数用于将经过编码后的url参数进行解码。
from urllib import parse qs = "name=%E5%BE%B7%E7%91%9E%E5%85%8B&age=100" print(parse.parse_qs(qs)) #{'name': ['德瑞克'], 'age': ['100']}
1.4.urlparse和urlsplit函数用法
urlparse和urlsplit都是用来对url的各个组成部分进行分割的,唯一不同的是urlsplit没有"params"这个属性.
from urllib import request,parse url = "https://www.baidu.com/s?wd=cnblog#2" result = parse.urlparse(url) print(result) #ParseResult(scheme='https', netloc='www.baidu.com', path='/s', params='', query='wd=cnblog', fragment='2') print('scheme:',result.scheme) #协议 print('netloc:',result.netloc) #域名 print('path:',result.path) #路径 print('query:',result.query) #查询参数 #结果 #scheme: https # netloc: www.baidu.com # path: /s # query: wd=cnblog
1.5.Request爬去拉勾网职位信息
Request类的参数
class Request: def __init__(self, url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None):
爬去拉钩网职位信息
拉勾网的职位信息是在Ajax.json里面
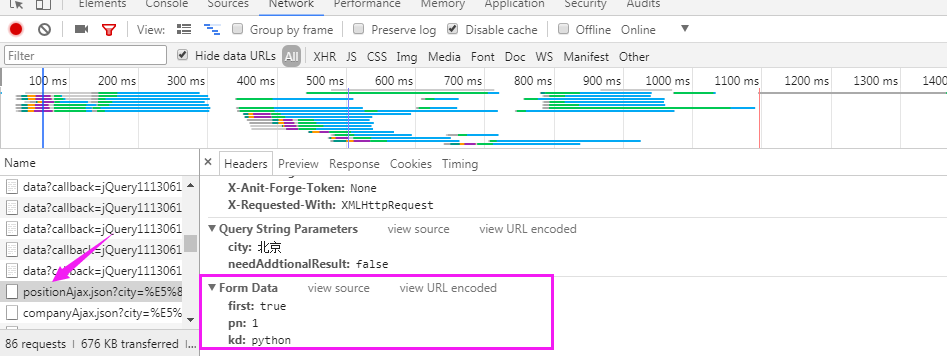
代码:
#利用Request类爬去拉勾网职位信息 from urllib import request,parse url = "https://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false" #请求头 headers = { "User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36", "Referer":"https://www.lagou.com/jobs/list_python?city=%E5%8C%97%E4%BA%AC&cl=false&fromSearch=true&labelWords=&suginput=" } #post请求需要提交的数据 data = { 'first':'true', 'pn':1, 'kd':'python' } #post请求的data数据必须是编码后的字节类型 req = request.Request(url,headers=headers,data=parse.urlencode(data).encode('utf-8'),method='POST') #建立一个请求对象 res = request.urlopen(req) #获取的信息是字节类型,需要解码 print(res.read().decode('utf-8'))
1.6.ProxyHandler代理
代理原理:在请求目的网站之前,先请求代理服务器,然后让代理服务器去请求目的网站,获取到数据后,再返回给我们。
#代理的使用 from urllib import request url = "https://www.baidu.com/s?wd=cnblog" #1.使用ProxyHandler传入代理构建一个handler # handler = request.ProxyHandler({'http':'115.210.31.236.55:9000'}) handler = request.ProxyHandler({'http':'115.210.31.236.55:9000'}) #2.使用创建的handler构建一个opener opener = request.build_opener(handler) #3.使用opener去发送一个请求 res = opener.open(url) print(res.read())