浏览器缓存(一):强缓存 MEMORY CACHE 和 DISK CACHE
关于memory cache 和 disk cache
随便浏览一个网站:
首次打开,或者开启浏览器的 Disable Cache(浏览器的Network下, 与Preserve log同级别),在size 一栏会显示资源大小。
在关闭 Disable Cache 的情况下,然后再次刷新页面,发现size 一栏 显示(memory cache) 或者(disk cache)
图片对应的是 memory cache
css等资源是 disk cache
查看对应的请求头:
在General下面的 Status Code 会显示 200OK (from memory cache) 或者(from disk cache)
所以了解下两者的区别
disk cache(磁盘缓存) 和 memory cache(内存缓存)的区别?
都属于强缓存,现在浏览器缓存存储图像和网页等(主要在磁盘上),而你的操作系统缓存文件可能大部分在内存缓存中。使用这两个缓存功能,是因为它比从远程的 web 服务器获取这些资源的方式更近、更快。Cpu 本身是有”缓存线”的,它是程序最近使用的内存(RAM)部分的副本。这样,如果一个程序在一个循环中运行(一遍又一遍地做同样的事情) ,它也就不必为每个指令或数据块进入 RAM 了。这个缓存比 RAM 快得多,但是它非常小,因为超快的内存毕竟昂贵。
强缓存作为性能优化中缓存方面最有效的手段,能够极大的提升性能。由于强缓存不会向服务端发送请求,对服务端的压力也是大大减小。对于不太经常变更的资源,可以设置一个超长时间的缓存时间,比如一年。浏览器在首次加载后,都会从缓存中读取。但是由于不会向服务端发送请求,那么如果资源有更改的时候,怎么让浏览器知道呢?现在常用的解决方法是加一个?v=xxx的后缀,在更新静态资源版本的时候,更新这个v的值,这样相当于向服务端发起一个新的请求,从而达到更新静态资源的目的。
至于区别主要在于提取速度上,memory cache 要比 disk cache 快的多,怎么使用要看前端技术人员结合自己网站来选择了,两个都是很不错的缓存方式!举个例子:从远程 web 服务器直接提取访问文件可能需要500毫秒(半秒),那么磁盘访问可能需要10-20毫秒,而内存访问只需要100纳秒,更高级的还有 L1缓存访问(最快和最小的 CPU 缓存)只需要0.5纳秒。
- 200 form memory cache
不访问服务器,一般已经加载过该资源且缓存在了内存当中,直接从内存中读取缓存。浏览器关闭后,数据将不存在(资源被释放掉了),再次打开相同的页面时,不会出现from memory cache。 - 200 from disk cache
不访问服务器,已经在之前的某个时间加载过该资源,直接从硬盘中读取缓存,关闭浏览器后,数据依然存在,此资源不会随着该页面的关闭而释放掉下次打开仍然会是from disk cache。 - 304 Not Modified
访问服务器,发现数据没有更新,服务器返回此状态码。然后从缓存中读取数据。
| 状态 | 类型 | 说明 |
|---|---|---|
| 200 | form memory cache | 不访问服务器,直接读缓存,从内存中读取缓存。此时的数据时缓存到内存中的,当kill进程后,也就是浏览器关闭以后,数据将不存在。但是这种方式只能缓存派生资源 |
| 200 | form disk cache | 不请求网络资源(服务器),直接从磁盘中读取缓存,当kill进程时,数据还是存在。 |
| 200 | 资源大小数值 | 从服务器下载最新资源 |
| 304 | 报文大小 | 请求服务端,返回304,发现资源没更新,然后从缓存中读取数据, 困惑点,服务器如何判断from memory cache还是304 |
但实际上真是如此吗?
再深入研究下

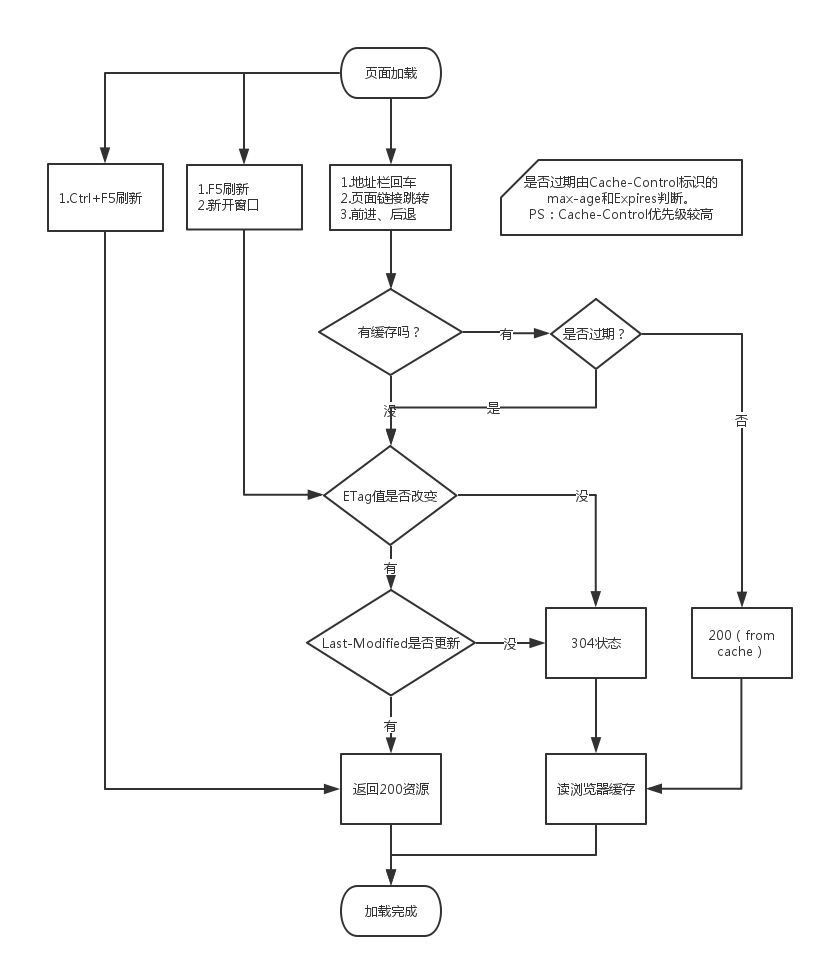
三级缓存原理
1. 先去内存看,如果有,直接加载
2. 如果内存没有,择取硬盘获取,如果有直接加载
3. 如果硬盘也没有,那么就进行网络请求
4. 加载到的资源缓存到硬盘和内存
比如:访问图片-> 200 -> 退出浏览器
再进来-> 200(from disk cache) -> 刷新 -> 200(from memory cache)
http header
max-age
web中的文件被用户访问(请求)后的存活时间,是个相对的值,相对Request_time(请求时间)
Expires
Expires指定的时间根据服务器配置可能有两种:
1. 文件最后访问时间
2. 文件绝对修改时间
如果max-age和Expires同时存在,则被Cache-Control的max-age覆盖
last-modified
WEB 服务器认为对象的最后修改时间,比如文件的最后修改时间,动态页面的最后产生时间
ETag
对象(比如URL)的标志值,就一个对象而言,文件被修改,Etag也会修改
Cache-Control
简单理解,强缓存
结论:所以实际应用中,遇到资源更新之后,还是有缓存的情况,除了刷新cdn,还要检查下是否有设置http响应头,做对应的缓存过期时间处里,如果没有做缓存过期策略,如果客户端缓存的资源,并且走了 disk cache,可能怎么刷新都没办法获取最新的资源。
来自网络的一张图结尾: