在网上找到一个Rainbow算法的代码(https://gitee.com/devilmaycry812839668/Rainbow),在里面找到了atari游戏环境下帧的预处理操作。
具体代码地址:
https://gitee.com/devilmaycry812839668/Rainbow/blob/master/env.py
# -*- coding: utf-8 -*- from collections import deque import random import atari_py import cv2 import torch class Env(): def __init__(self, args): self.device = args.device self.ale = atari_py.ALEInterface() self.ale.setInt('random_seed', args.seed) self.ale.setInt('max_num_frames_per_episode', args.max_episode_length) self.ale.setFloat('repeat_action_probability', 0) # Disable sticky actions self.ale.setInt('frame_skip', 0) self.ale.setBool('color_averaging', False) self.ale.loadROM(atari_py.get_game_path(args.game)) # ROM loading must be done after setting options actions = self.ale.getMinimalActionSet() self.actions = dict([i, e] for i, e in zip(range(len(actions)), actions)) self.lives = 0 # Life counter (used in DeepMind training) self.life_termination = False # Used to check if resetting only from loss of life self.window = args.history_length # Number of frames to concatenate self.state_buffer = deque([], maxlen=args.history_length) self.training = True # Consistent with model training mode def _get_state(self): state = cv2.resize(self.ale.getScreenGrayscale(), (84, 84), interpolation=cv2.INTER_LINEAR) return torch.tensor(state, dtype=torch.float32, device=self.device).div_(255) def _reset_buffer(self): for _ in range(self.window): self.state_buffer.append(torch.zeros(84, 84, device=self.device)) def reset(self): if self.life_termination: self.life_termination = False # Reset flag self.ale.act(0) # Use a no-op after loss of life else: # Reset internals self._reset_buffer() self.ale.reset_game() # Perform up to 30 random no-ops before starting for _ in range(random.randrange(30)): self.ale.act(0) # Assumes raw action 0 is always no-op if self.ale.game_over(): self.ale.reset_game() # Process and return "initial" state observation = self._get_state() self.state_buffer.append(observation) self.lives = self.ale.lives() return torch.stack(list(self.state_buffer), 0) def step(self, action): # Repeat action 4 times, max pool over last 2 frames frame_buffer = torch.zeros(2, 84, 84, device=self.device) reward, done = 0, False for t in range(4): reward += self.ale.act(self.actions.get(action)) if t == 2: frame_buffer[0] = self._get_state() elif t == 3: frame_buffer[1] = self._get_state() done = self.ale.game_over() if done: break observation = frame_buffer.max(0)[0] self.state_buffer.append(observation) # Detect loss of life as terminal in training mode if self.training: lives = self.ale.lives() if lives < self.lives and lives > 0: # Lives > 0 for Q*bert self.life_termination = not done # Only set flag when not truly done done = True self.lives = lives # Return state, reward, done return torch.stack(list(self.state_buffer), 0), reward, done # Uses loss of life as terminal signal def train(self): self.training = True # Uses standard terminal signal def eval(self): self.training = False def action_space(self): return len(self.actions) def render(self): cv2.imshow('screen', self.ale.getScreenRGB()[:, :, ::-1]) cv2.waitKey(1) def close(self): cv2.destroyAllWindows()
该代码主要使用 atari_py 库实现游戏环境运行及图像的采集。
上面的代码为pytorch深度学习计算框架提供支持,同时可以经过适当的更改同样可以为TensorFlow等其他深度计算框架提供支持。
### 创建atari游戏环境的连接对象

### 为连接对象ale设置属性, 设置随机种子:random_seed ,每一个回合最多的帧个数(最多step数):max_num_frames_per_episode
### 执行动作传递给游戏环境时是否对上一个动作进行重复(迟滞动作):repeat_action_probability , frame_skip:是否跳帧(中间帧使用重复动作)

打印游戏路径:
atari_py.get_game_path(args.game)


为ale游戏连接对象加载游戏仿真环境的二进制文件:
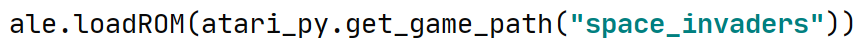
获得ale的灰度值图像:

将ale的RGB图像更改为BGR图像以使cv2进行显示:
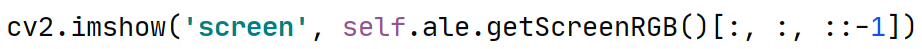
手动编写跳帧操作:
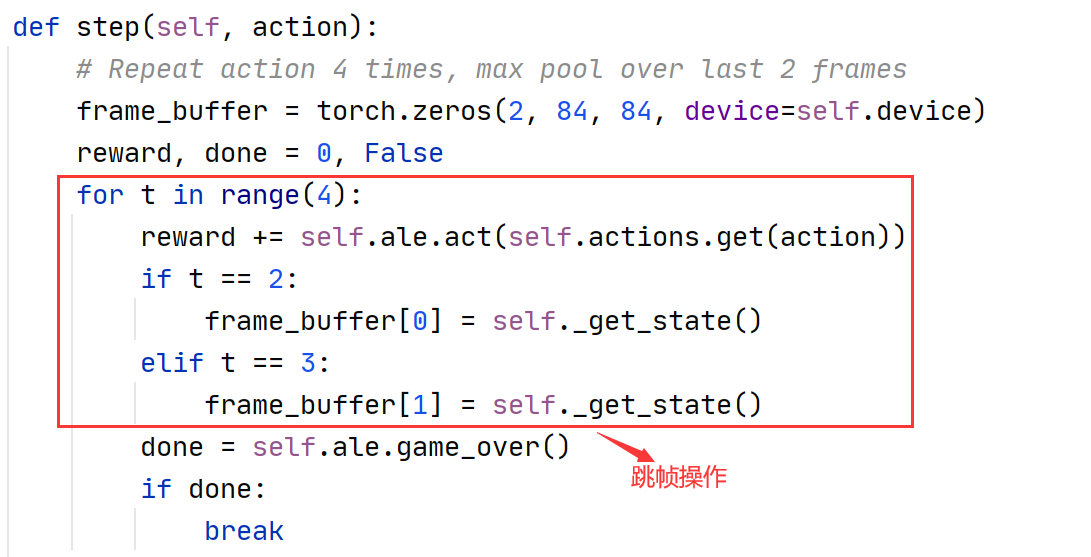
相邻两帧图像取最大值,避免图像闪烁问题:

对特殊游戏(一回合游戏有多条游戏生命数)设置 training 和 eval 两种模式, training模式下将每个生命数内的游戏帧提取为一个回合。

整体回合没有结束,但是部分回合结束(游戏生命数减少),使结束画面和开始画面连接:

游戏回合开始时进行一定步数的随机操作:

游戏回合内新生命数下游戏开始时进行随机操作,否则游戏游戏无法进行下一步操作:

扩展:
gym atari游戏的环境设置问题:Breakout-v0, Breakout-v4, BreakoutNoFrameskip-v4和BreakoutDeterministic-v4的区别
(https://www.cnblogs.com/devilmaycry812839668/p/14665402.html)