learning to link with wikipedia
一、本文目标:
如何自动识别非结构化文本中提到的主题,并将其链接到适当的Wikipedia文章中进行解释。
二、主要借鉴论文:
Mihalcea and Csomai----Wikify!: linking documents to encyclopedic knowledge
第一步:detection(identifying the terms and phrases from which links should be made):
link probabilities:它作为锚的维基百科文章数量,除以提及它的文章数量。
第二步:disambiguation:从短语和上下文的单词中提取特征。
Medelyan et al.---- Topic Indexing with Wikipedia.
Disambiguation:
Balancing the commonness (or prior probability) of each sense and how the sense relates to its surrounding context.

三、两大步骤:link disambiguation and link detection
Link disambiguation:
Commonness and Relatedness
1.The commonness of a sense is defined by the number of times it is used as a destination in Wikipedia.
2.Our algorithm identifies these cases by comparing each possible sense with its surrounding context. This is a cyclic problem because these terms may also be ambiguous
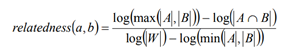
where a and b are the two articles of interest, A and B are the sets of all articles that link to a and b respectively, and W is set of all articles in Wikipedia.
Some context terms are better than others
1.单词The是明确的,因为它只用于链接到文章的语法概念,但是对于消除其他概念的歧义,它没有任何价值。
link probability 可以解决这个问题。很多文章提到the,但没有把它作为链接使用。
2. 许多上下文术语都是与文档的中心无关的. 我们可以使用Relatedness的度量方法,通过计算一个术语与所有其他上下文术语的平均语义关联,来确定该术语与这个中心线程的关系有多密切。
These two variables—link probability and relatedness—are averaged to provide a weight for each context term.
Combining the features
图中,大多关于“树”是与本文是不相关的,因为该文档显然是关于计算机科学的。如果在上下文不明确或混淆的情况下,则应选择最常用。这在大多数情况下都是正确的。
引入最后一个feature: context quality
This takes into account the number of terms involved, the extent they relate to each other, and how often they are used as Wikipedia links.
the commonness of each sense,its relatedness to the surrounding context,context quality
这三个feature来训练一个分类器。
注:这个分类器并不是为每一项选择最好的词义,而是独立考虑每一种候选,并产生它的概率。
训练阶段需要考虑的问题:参数,分类器。
参数:specifies the minimum probability of senses that are considered by the algorithm.
---- 2%
分类器:C4.5
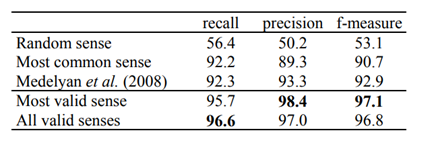
link detection:
link detection首先收集文档中的所有n-grams,并保留那些概率超过非常低的阈值(这用于丢弃无意义的短语和停止词)。使用分类器消除所有剩余短语的歧义。

1.会有几个链接与之相关的情况。就像Democrats and Democratic Party的情况一样。
2.如果分类器发现多个可能的情况,术语可能指向多个候选。例如,民主党人可以指该党或任何民主的支持者。
Features of these articles are used to inform the classifier about which topics should and should not be linked:
Link Probability
Mihalcea and Csomai’s link probability to recognize the majority of links
引入两个feature: the average and the maximum
the average: expected to be more consistent
the maxinum: be more indicative of links
比如:Democratic Party 比 the party 有更高的链接可能性。
Relatedness
此文中,读者更可能对克林顿、奥巴马和民主党感兴趣,而不是佛罗里达州或密歇根州。
希望与文档中心线相关的主题更有可能被链接。
引入feature: the average relatedness
between each topic and all of the other candidates.
Disambiguation Confidence
使用分类器的结果作为置信度。
引入两个feature: average and maximum values
Generality
对于读者来说,为他们不知道的主题提供链接要比为那些不需要解释的主题提供链接更有用。
为一个链接定义一个generality表示它位于Wikipedia类别树中的最小深度。
通过从构成Wikipedia组织层次结构根的基本类别开始执行广度优先搜索来计算。
Location and Spread
三个feature: Frequency first occurrence last occurrence
第一次和最后一次出现的距离用于体现文档讨论主题的一致性。
训练阶段唯一要配置的变量是初始链接概率阈值,用于丢弃无意义的短语和停止单词。
--6.5%
四.WIKIFICATION IN THE WILD
Data: Xinhua News Service, the New York Times, and the Associated Press.
