Entity Linking with Effective Acronym Expansion, Instance Selection and Topic Modeling
一.主要贡献
1. propose a supervised learning algorithm to expand more complicated acronyms
2. propose an instance selection strategy to effectively utilize the automatically generated annotation
3. effectively capturing the semantic information between document and KB entry by a topic model.
二.相关介绍
实体链接主要包括查找名称变体和消歧。
名称变体查找阶段
从上下文展开一个缩略词,可以有效地减少缩略词提到的歧义。例如,TSE在Wikipedia中引用33个条目,但其全名Tokyo Stock Exchange,这是明确的,我们可以直接链接到正确的条目,而不需要消除歧义。
本文采用字符串匹配的方式生成候选实体。
名称消歧阶段
通过在向量空间模型中对KB中的条目进行排序。
本文通过ranking SVM对每个候选实体打分,选出最高的分数的实体,再通过二分类器,决定这个分数最高的应不应该被链接。
三.Acronym Expansion
1. 首先,将模式A中找到的所有字符串添加到候选集合C中。接下来,我们找到“(A)”的模式,并提取“(A)”之前的最长连续令牌序列E,该序列不包含标点或不超过2个停止字。
Eg: John received an award from the Association for Computing Machinery (ACM).
E = the Association for Computing Machinery.
我们将E和它的所有子字符串(结尾和E一致)到C。
the Association for Computing Machinery, Association for Computing Machinery, for Computing Machinery, Computing Machinery and Machinery.
2. 在文档中搜索其首字母与首字母缩写词匹配的所有标记。
Eg: the Association for Computing Machinery has granted the….
对于ACM, E = Association for Computing Machinery has
同时把和开头一致的子字符串加入C.
Assoc… Machinery has, Assoc… Machinery, Assoc… Computing, Association
3. 交换缩略语字母和完全小写的展开
Eg: Communist Party of China (CCP)
四.Instance Selection Strategy
《Entity Linking Leveraging Automatically Generated Annotation》之前为实体链接生成大型训练实例。
基本思想: take a document with an unambiguous mention referring to an entity e1 in KB and replace it with its variation which may refer to e1, e2 or others。
the distribution of the auto-generated data is not consistent with the real data set
↓
提出一种instance selection strategy。
本文使用SVM分类器从自动生成的数据集中进行选择,实例到超平面的距离作为指标。
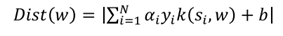

五.Incorporating Semantic Feature
以前的方法将提及的上下文视为bow、n-gram、名词短语或命名实体组成,并通过加权的文字术语向量的比较来度量上下文相似性.
缺点:缺乏语义信息和稀疏性问题。
↓
引入一个topic model,通过使用LDA实体链接,以发现文档和KB的基础主题。

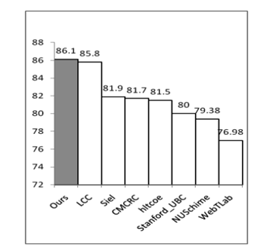
六.Experiments