网站的伸缩性架构中,分布式的设计是现在的基本应用。
在memcached的分布式架构中,key-value缓存的命中通常采用分布式的算法
一、余数Hash
简单的路由算法可以使用余数Hash:
node编号=HashCode(key)%服务器数目
例如: key=‘BEIJING'的hash值为490806430,服务器数目=3。那么余数为1。所以这个key-value就落在第一台缓存服务器上。
优点:计算简单。
缺点:不利于扩展。如果扩展的话,由3太服务器扩展为4台服务器,那么通过一个key='BEIJING',再除以服务器数码,余数为2。那么将不能命中,计算可知,增加一台服务器不能命中的数据将达到:N/(N+1)。那也太高了。
二、一致性Hash算法
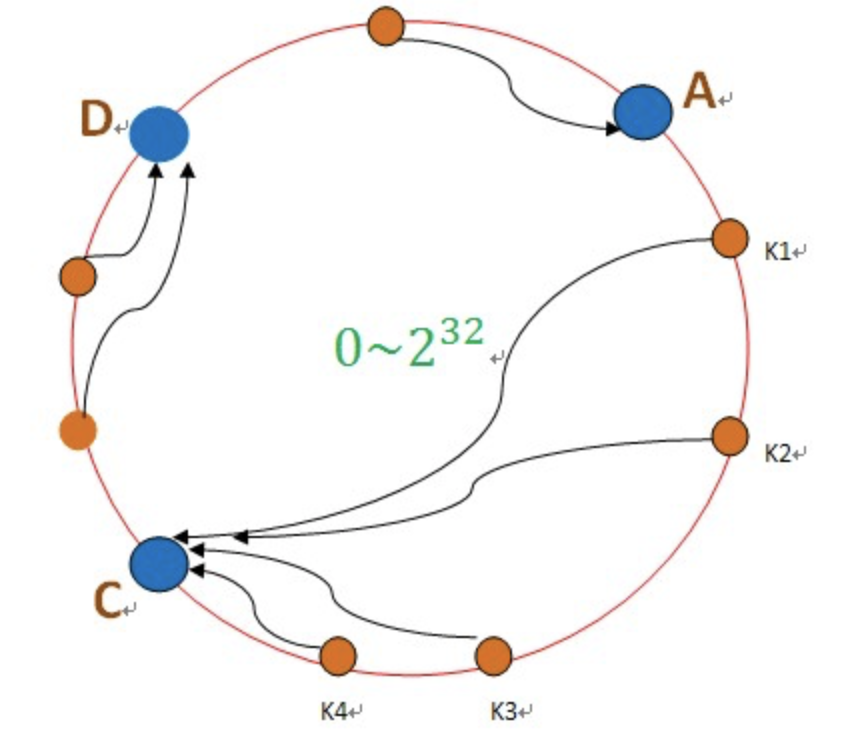
数据结构:一致性哈希环(图片来自网络)

算法过程:
数据存放;先构造一个长度为2^32的整数环,根据节点名称的Hash值[0,2^32-1],将缓存服务器节点放置在这个Hash环上。也就是说,每个节点,都根据起Hash值,放在对应的Hash环的位置中。。。如上图,假设有4个节点node1 - node4。当数据来临时候,根据数据KEY计算得到的Hash值,顺时针找到最近的node,然后将数据放入此节点。
增加节点:如果当node5节点增加进入系统时,只有node5之前的数据受到影响,由原来的放在node4上,转移到新节点node5上。
查找算法:Hash查找的过程实际上是在二叉查找树中查找不小于查找树的最小数值。当然这个二叉树的最右边子节点和最左边子节点相连接,构成环。
缺陷:
新加入的node5节点只影响到了node4上面的部分数据。原来节点node1,node2,node3都不受影响。这就意味着,node1 - node3 将承受着node4、5的两倍数据压力。如果5台服务器的性能是一样的,那么这种结果显然不是最好 的。
虚拟节点:
如图:(图片来自网络)
 --
--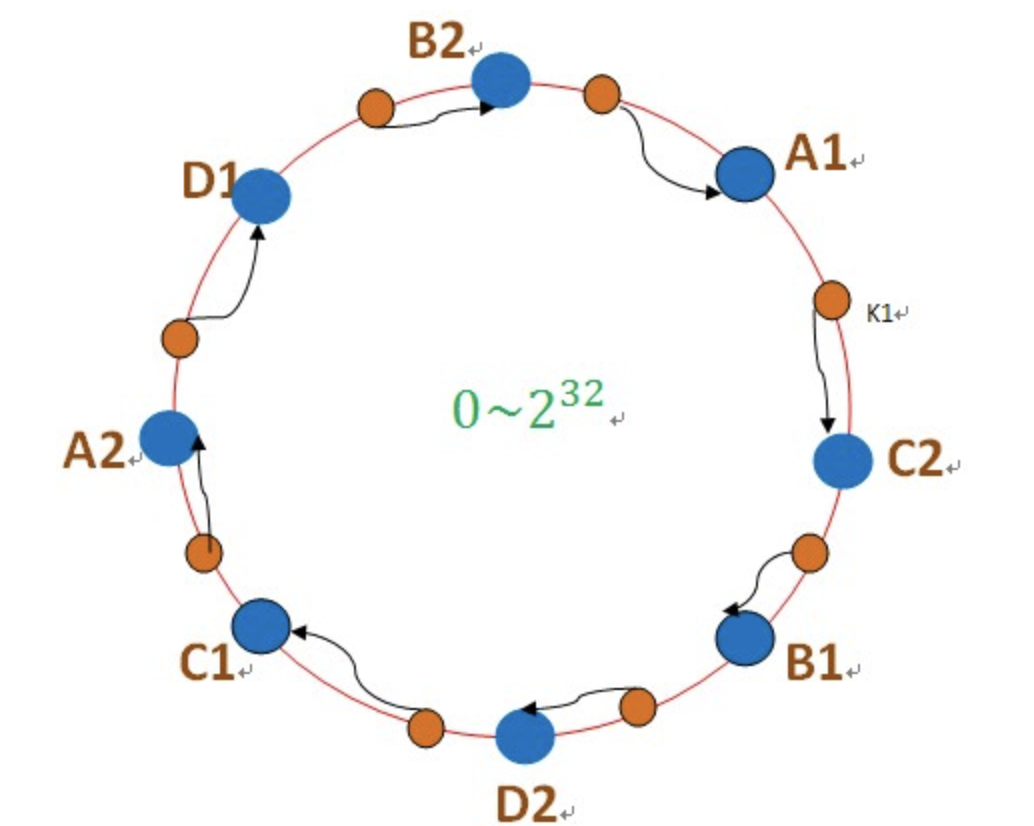
将每个物理节点映射为3个虚拟节点A1,A2,A3。这样,当增加一个物理机时,也将该虚拟机地址映射为3个或多个虚拟节点,将这新的3个虚拟节点分摊到环的不同位置,那么受到影响的节点也分不到不同的位置。整个环节点的均匀性将会大大增加!
三、系统的扩展性和伸缩性区别
扩展性和伸缩性不要搞混了。
扩展性:对现有系统影响最小的情况下,系统功能可持续扩展或提升的能力。
表现在基础设施稳定不需要经常变更,应用之间较少以来和耦合,对需求变更可以敏捷响应。是系统架构设计层面的“开闭原则(对扩展开放,对修改闭合)”,架构设计考虑未来功能扩展,当系统新增功能时,不需要对现有系统的结构和代码进行修改。
伸缩性:系统能够通过增加(减少)自身资源规模的方式增强(减少)自己计算处理事物的能力,如果这种增减是成比例的,就被称作线性伸缩性。在网站架构中,通常指利用集群的方式增加服务器数量、提高系统的整体事物吞吐能力。