- 质量、效率、成本、安全,是运维工作核心四要素。
- AIOps 技术会涉及到数据收集方面的基础监控,服务监控和业务监控,甚至会涉及到与持续交付流水线的数据和状态整合(比如在软件发布的阶段会自动关闭某些监控项。异常判断时会参考流水线目前的状态)。数据存储与人工智能技术,其中人工智能包括机器学习算法与深度学习模型(用于模式识别)。
- 引入 AIOps 之后,是否能对 AIOps 的模型或数据进行不断优化也是一个新的挑战。人工智能在一开始都不是很完美的,需要不断优化才能达到实际应用的要求。对于发现问题和问题根因分析方面的 AIOps 落地速度比较快,对于高级阶段的根据 SLA 自动调度的 AIOps 就需要比较长的优化
- AIOps 的数据,从来源上看,主要分四类:设备、系统、平台、业务,设备主要指 IDC、网络、服务器等偏硬件、数据中心层的设备信息;系统主要指操作系统等;平台主要指基础运维平台、PaaS 平台等;业务主要指产品服务的日志等。
- AIOps 的数据,从类型来看,主要也是四类:一个是时序数据,这个重要性最高,因为其结构化层次高,在百度,这个数量级能达到十亿级。第二个是运维事件数据,这个同样也非常重要,每一次异常事件、变更事件、运营事件等等,都是需要被记录并加以分析的。第三个是日志数据,相比之下日志数据的结构化偏弱一些,但同样十分重要,由于量级太过庞大,我们也只会挑选并存储较为重要的部分,来进行分析训练。当然,还有最后一类,因 AIOps 而产生的数据“标注数据”,这部分数据的完善程度将直接影响着每一个算法模型的实际效果。
- 数据来自于运维工作与服务的场景。质量、效率、成本、安全, 任何一个维度都需要将数据标准化采集,这是一切的基础。
- 自动运维是将重复出现的运维动作自动化,而需要人来判断什么情况(或是条件出发)执行那种自动化过程。
- AIOps 也就是讲的如何把人的决策也自动化起来。
AIOps应用方向
- 在百度运维,AIOps 应用的很广泛,监控异常检测、故障诊断分析、智能流量调度、SQL 入侵检测、成本优化、性能分析优化等等。
- 在自动化异常检测方向的研究非常早,早期还以传统的时序数据分析为主,现在由于机器学习等方法的兴起,已经多样化很多,在百度大多数核心时序指标的监控都是用的自动化异常检测模式。
- 在故障诊断方向,这一直是一个比较难的课题,我们研究过非常多的行业 paper,真正实现后效果出色的少之又少,当然这也可以理解,因为对于人来讲,诊断故障也一直是一个让人头疼的问题。
- 在智能流量调度、SQL 入侵检测、成本优化、性能分析优化等层面,我们应用了非常多的机器学习模型,为公司业务的可用性、成本、性能等的提升做出了巨大贡献。
- 故障识别和故障自愈,资源自动调度。
- 更高级的场景会引入全自动软件发布控制与回滚,自然语言容量管理,主动安全识别和在软件研发完成前对软件体验进行评分。
- 运维团队聚焦在基础服务与增值服务中落地。基础服务包括发布变更、故障管理、用户体验服务。增值服务包括触达到用户与产品决策的运维扩展服务。发布变更中的数据预测、故障管理中的根因分析、用户体验中的多维告警等,都是 AIOps 的落地场景。触达用户的云控策略、产品决策的舆情分析等, 也都有着很好的应用场景。
- Netflix 的 Winston,以及 Google 的 Auxon
- 主要还是解决复杂环境下问题的快速发现甚至提前预判,以及出现问题后的如何在复杂的告警、报错和日志中快速进行根因分析。
- 根因分析,在服务化的架构中,最头痛的还是出现了故障,无法快速的定位原因。大致思路是,根据全链路跟踪系统的每一次请求的依赖关系,做调用的关联度分析,当一个模块出现问题时,会同时导致依赖这个模块的所有模块都会告警,甚至还有业务层面的告警,这时就需要快速的根因分析,确定问题在哪儿。
落地
- 算法还是那些算法,不过得要有相应专业能力的团队,如果是纯应用,我觉得运维团队倒是可以自学一下,但是不管怎么样,这个还是有一定门槛,需要大量的学习和能力提升。
- 数据就是要靠线上运行的真实数据和日志,所以必须要有大量的数据积累
- 计算能力上,目前看到我们基于大数据技术的数据处理能力已经足够,因为毕竟不是像图形图像这样的复杂计算场景。
- AI 的生态体系与大数据类似,存在两种基本角色:AI 科学家和 AI 领域工程师(FE)。前者推动 AI 科学的发展,创造新的 AI 知识体系;后者是将 AI 知识运用到生产生活的某个领域,创造现实价值。AIOps 正是将 AI 技术应用到 IT 运维领域,帮助变革运维模式,提升效率和创造现实价值的“工程化”过程。
- AIOps 这个词本身就体现了两个关键点。其一,Ops 代表运维的场景,这是主旨,识别什么样的场景存在哪些痛点,AI 可以帮助解决;同时也要清楚认识目前的 AI 技术擅长什么,不擅长什么,有哪些限制,切忌凡事尽 AI。其二,AI 作为前缀代表技术,这是手段,AI 技术门类很多,选择合适的,正确的技术去解决真正的问题,是需要切实履行的原则。此外,要从实际出发,考虑投入与产出。
有两类痛点可以关注:
- 时效类问题:运维的本质是提供稳定可靠的服务,而达成这个目标的关键是足够好的时效。时效类的场景还是很多的,例如更短的 MTTR(平均故障恢复时间),特别在服务规模很大的情况下,监控数据的获取 / 集中 / 分析,问题的跟踪 / 定位,恢复的执行规划,如果再加上海量数据和状态频繁变化,AIOps 时效都会远高于有经验的人 + 工具。此外,人类有“工作时间”和“工作活力”的限制,自动化依然离不开人的决策,但智能化可以自主决策,当然目前是在经过检验的人类经验范围的扩展学习。“无中生有”的经验创造依然是个难题。
- 协作类问题:人类的生产离不开协作。尽管有了自动化运维平台或工具链,运维很多场景还是需要许多人工协作。一个经典的例子:业务发现了问题提交工单给 IT 服务台,IT 服务台根据经验初步判断可能与哪些系统相关,再通知相关团队,相关团队判断是否是自己的问题,如果是自己的问题则考虑的修复方案,然后修复,再反馈给 IT 服务台,通知业务。这是典型的 ITIL 流程。
落地AIOps的团队应该具备几个特征:
- 对现有 AI 技术充分了解和掌握。
- 选择较成熟的开源 AI 技术是必由之路。
- 对运维领域的技术(比如监控、容器技术、CI/CD、问题诊断等)是清楚的,最好是专家。
- 对运维领域的场景是熟悉的,明白运维的标准,逻辑,原则。
AIOps落地形态:任务机器人,相关技术也围绕它展开,涉及自然语言处理、搜索技术、知识图谱、监督学习、在线学习、深度学习等。现在处于实验落地阶段,有三个基本场景。
- DevOps 的一个典型场景:系统上线。上线的几个痛点是时机选择,上线条件判断,部署验证,功能验证。这些部分有的是需要人工判断的,有的通过工具进行,但都是人工驱动的逻辑判断。这是个时效类场景,如何上线更快,更可靠。
- 另一个场景是运维的日常工作:巡检。尽管监控系统已经可以掌握全方位的数据,比如应用性能,日志,调用链,基础设施等,还是需要有人值守;而当报警出来的时候,往往又滞后了;此外微服务架构下,人工也跟不上规模的增长和状态的快速变化。而任务机器人是可以正真全天候运行的。这也是时效类的场景,对问题的及时发现,甚至预判。特别值的一提的是,这是主动行为,而系统上线是被动触发,这两个场景正好体现了类人化智能的两面。
- 我们相信运维的价值在于更好的业务价值转化,Better ITOps for Better Business。这个场景是协作类的,涵盖运维和运营。从业务同事来看他们有两个痛点:一方面他们不懂 IT 术语,玩不转运维系统,但也想时刻掌握系统运行状况;部门以及团队在运营过程的信息不对称,不能随时快速同步,造成运营效率下降。任务机器人作为中间协调者,所有人有问题就找它,它会“不厌其烦”的,“孜孜不倦”的予以解答。
关于数据来源,诚如我提到的,深度集成 DevOps 工具链是必由之路(重要的事情说三遍),因为它们就是数据的来源。当然其中监控系统是主要的数据提供者,我们的监控系统代号 UAV(含义:无人机),它提供了几种主要数据:应用画像,服务图谱,应用性能,基础设施性能,日志,调用链,业务指标。
- 通过对应用画像的学习,提取 API 模型,让系统可以使用 API,这是一种新的系统关联方式。又比如通过对服务图谱的学习,让系统掌握应用之间的关联关系,这是自主跨应用问题跟踪和影响分析的基础。还可以通过对应用性能指标的特征提取,找出异常点等。
- 现在 AliExpress 正在做的是通过大数据驱动 SRE,把 SRE 关心的系统信息、访问信息等数据进行模型计算,通过机器学习进行问题识别和诊断,这个过程我认为就是 AI 的过程。
We have ample experience in the fields like:
- Cloud infrastructure design and implementation,
- Performance optimization
- Cloud monitoring, logging and alerting
- AI deployment and ML training
- Building complex distributed systems for Big Data analytics
What’s in the 20-minute tour?
- Full stack visibility across teams and tools
- Fast Root Cause Analysis
- Impact Analysis
- Anomaly detection
- Proactively prevent issues from impacting your business.
5 Ways AIOps Will Influence Enterprise IT Operations
- Capacity Planning
- Resource Utilization
- Storage Management
- Anomaly Detection
- Threat Detection & Analysis
“Artificial intelligence for IT operations (AIOps) platforms are software systems that combine big data and AI or machine learning functionality to enhance and partially replace a broad range of IT operations processes and tasks, including availability and performance monitoring, event correlation and analysis, IT service management, and automation.”
(Gartner – “Market Guide for AIOps Platforms” – Will Cappelli, Colin Fletcher, Pankaj Prasad. Published: 3 August 2017)
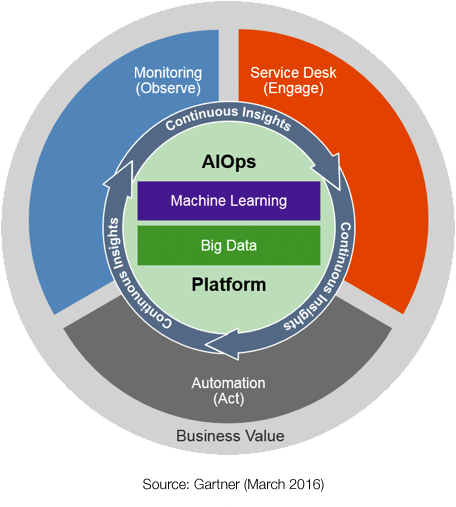

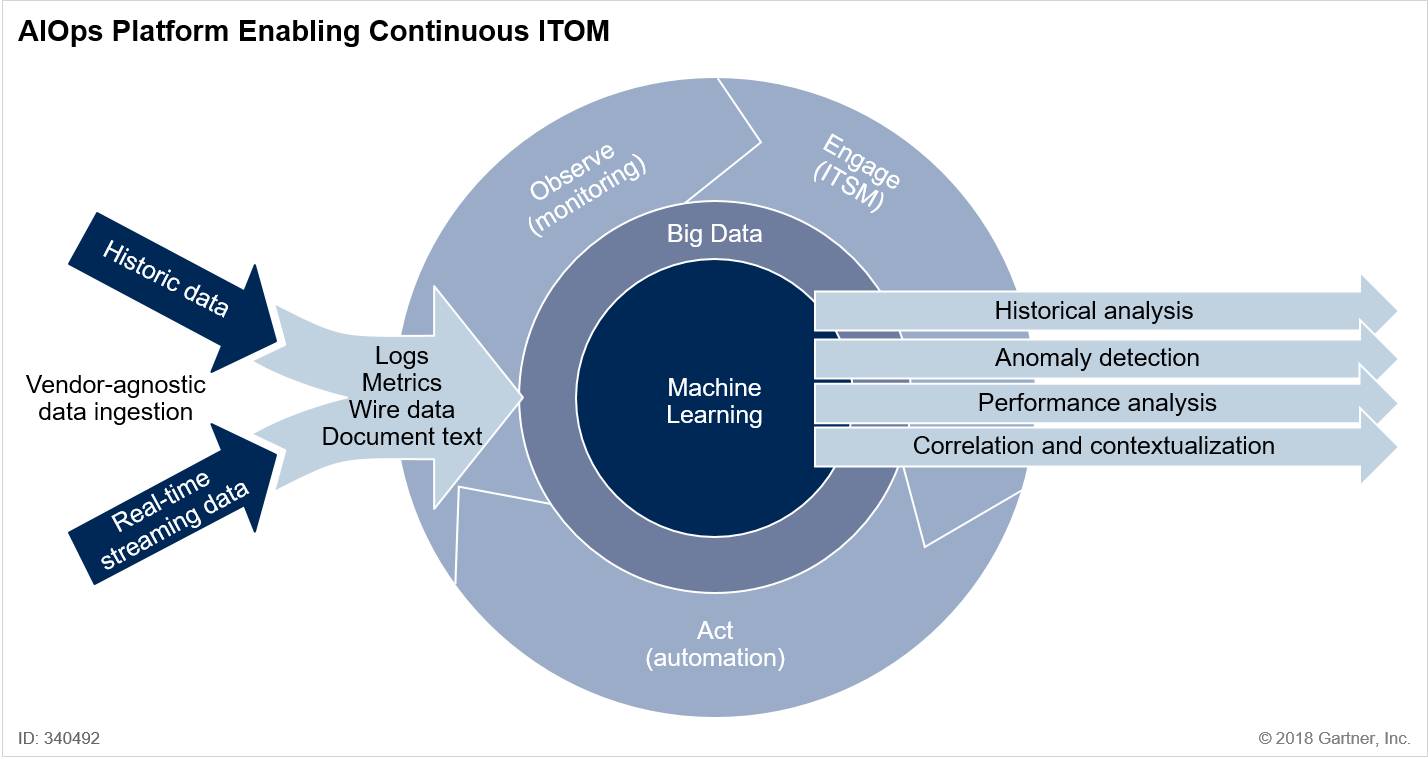
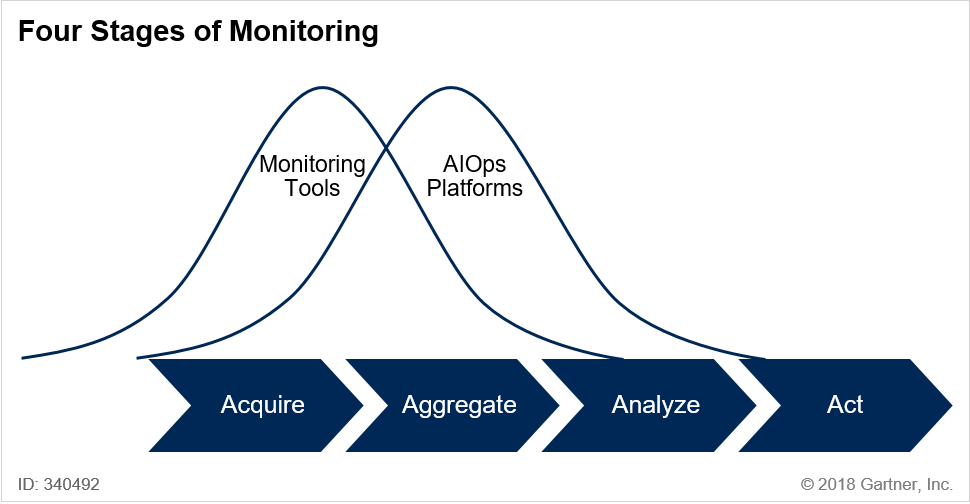
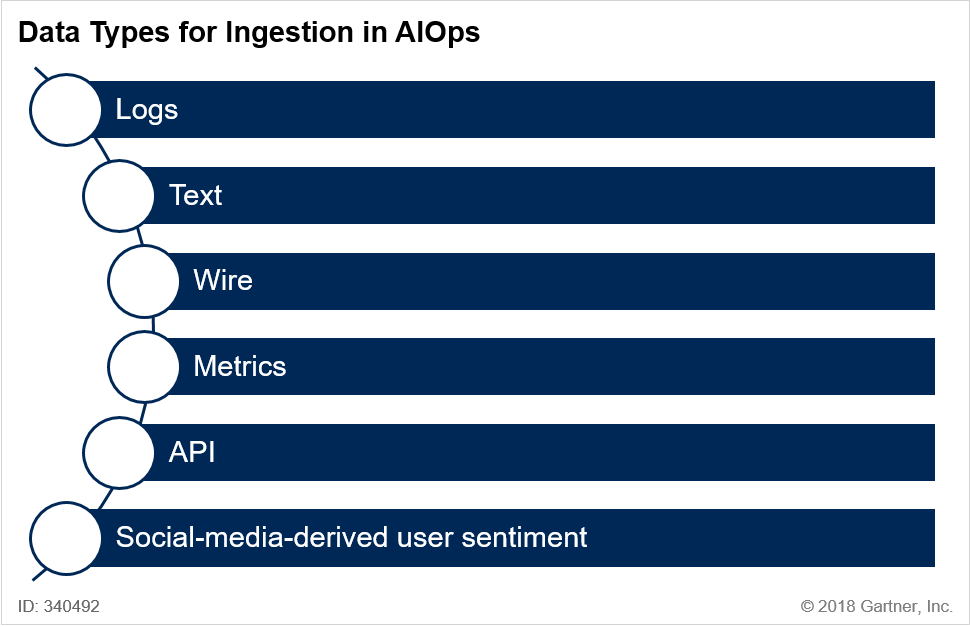
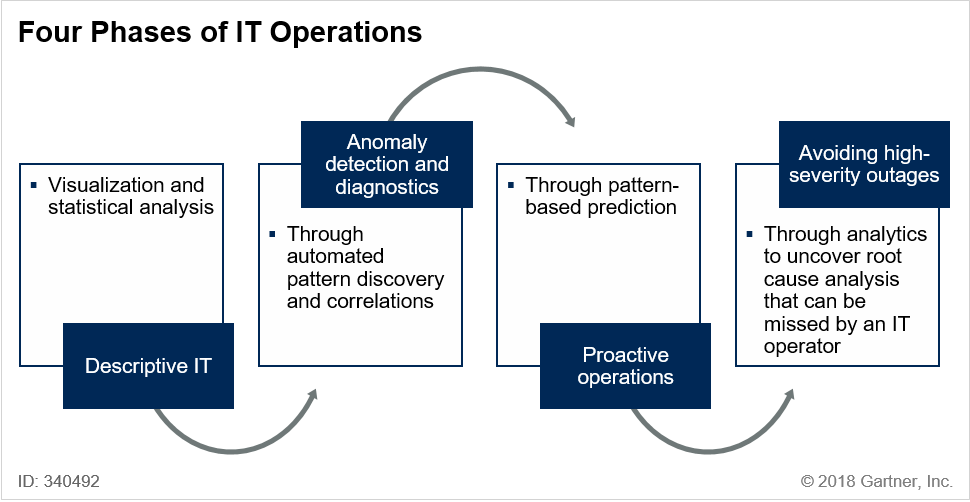
AIOps Key Features
Gartner’s Market Guide for AIOps Platforms lists eleven key requirements for AIOps platforms. To be truly valuable, an AIOps platform should have strong capabilities in all of these areas. Single-purpose tools will only be useful for very narrowly defined use cases.
- Stored: ingestion and indexing of historical data
- Streaming: capture, normalization, and analysis of real-time data
Logs: capture and preparation of text data from log files generated by software or hardware - Metrics: data to which time series and more general mathematical operations can be immediately applied
- Wire Data: packet data, including protocol and flow information, captured and made available for access and analysis
- Document Text Data: ingestion, parsing, and syntactical and semantic indexing of human readable documents
- Automated Pattern Discovery and Detection: the ability to identify mathematical or structural patterns within data streams that describe correlations, which can then be used to identify future incidents
- Anomaly Detection: the use of patterns to first determine what constitutes normal system behavior, and then to identify departures from that normal system behavior
- Causal Analysis: root cause determination, using automated pattern discovery to isolate genuine causal relationships and guide operator intervention
- On Premises: capabilities defined above can be delivered on customers’ premises, without requiring access to any remote components
- Cloud: capabilities defined above can be delivered in the cloud, without requiring on-premises installation of any components
LiveAction Capabilities
Analytics Node
An analytics node is a software that collects data to be sent to LiveNX Insight for analysis. It is deployed as an OVA typically co-located with the distributed LiveNX Nodes.
Anomaly Detection
Anomaly detection—identifying events or observations which do not conform to an expected pattern or other items in a dataset—is one example of LiveNX Insight use case.
Big Data Management
See Node below.
Insights
Insights has two references within LiveAction. First, LiveNX Insight is a machine learning, analytics software licensed module. Second, LiveNX Insight produces insights, which are analytic based summary observation made because of machine learning. The network engineer or IT operations person can self-select which insight is valuable to the environment, which directs the machine learning to dive deeper into these topical areas for further insights.
Epic Store
See ‘Data Store’.
Data Store
The Flow Data Store is a repository within the LiveNX Server that allows for raw flow (eg. NetFlow, IPFIX etc) and SNMP data to be kept indefinitely as configured by the customer, in the big data backend. The Data Store is optimized for distributed high-performance collection, storage and analysis for flow and machine data using a time series database. The receive rate for flow on a per-node basis is 1 million flows per second.
Node
The LiveNX performance analytics platform is deployed in a scalable three-tiered distributed architecture. The LiveNX architecture consists of:
- Applications – Web interface and Java application client (Operations Dashboard, Engineering Console, …)
- Server – Central Manager for visualization, machine learning, reporting and integration.
- Node – Multiple nodes for SNMP polling, flow collection, and data store. Data is stored in the node. The node collects flow, SNMP, etc. data for storage, analysis and visual presentation.
Within the LiveNX architecture, there are two node types: an analytic node for LiveNX Insight inspection and LiveNX node for all other processing and storage.
Samplicator
A samplicator is a software process that is packaged within LiveNX Node OVA. It allows the ingestion and replication of NetFlow and Sflow instances in order to efficiently send them to multiple LiveNX servers and applications.
aiops文章
算法
- Twitter: Seasonal Hybrid ESD (S-H-ESD)
- Netflix: Robust PCA
- LinkedIn: exponential smoothing
- Uber: multivariate non-linear model
社区文章
- 虚拟座谈会:聊聊 AIOps 的终极价值
- 赵成:回顾运维的发展历史,我相信 AIOps 是必然趋势
- 阿里巴巴国际环境下的 SRE 体系实践
- 到底应该如何理解 AIOps?又如何落地 AIOps?
- Market Guide for AIOps Platforms
- What is AIOps? Artificial Intelligence for IT Operations Explained
- Gartner:AIOps「智能运维」真的来了,并且是趋势
- AIOps 是什么?它与 AI 有什么关系?
- AIOps-一位研发工程师的学习笔记
- AIOps 平台的误解,挑战及建议
- AIOps指导
- AIOps落地路线图
- Even Smarter: Achieving AIOps in the Age of Big Data
- AIOps: Building the Next Generation of Intelligent Infrastructure
- AIOps for Big Data Series
- From DevOps to AIOps — Making Your Search Operations Smarter
- AIOps Platforms@Garnter
- AIOps背景/所应具备技术能力分析(上)
- AIOps 平台的误解,挑战及建议(中)— AIOps常见的误解
- AIOps 平台的误解,挑战及建议(下)— AIOps 挑战及建议
- AIOPS在360的实践和探索
- AIOps探索:基于VAE模型的周期性KPI异常检测方法
- Next Generation of DevOpsAIOpsin Practice @Baidu
- Automated AIOps for the Digital Enterprise
- The Rise of AIOps: How Data, Machine Learning, and AI Will Transform Performance Monitoring
- 基于 AIOps 的无人运维
- AIOps | 运维新姿势
- AIOps中的四大金刚
- 基于机器学习的智能运维
- 从百度运维实践谈“基于机器学习的智能运维”
- 首届AIOps挑战赛——冠军LogicMonitor-AI团队方案分享
- 赵建春-AIOps 在腾讯的思考和实践
- AIOps百度架构实践