I've been playing with an idea of beating the market for a long while. It all started years ago during my time as a freelancer. At some point I was randomly contacted by a trader who managed to single-handedly beat the market and needed some help with the infrastructure code. I was in South America traveling as a digital nomad, but this request was too tempting to be ignored, so I took a 15-hour long flight to join him in Macau, which is as close to Las Vegas as you can get in China.
We lived in 5-star hotels, worked on trading bots and gambled in local casinos for a break. It was a surreal experience that completely changed my career. Upon leaving, I was confident that I’d take on beating the market myself, but years have passed, and I haven’t got into it.
At first I had doubts whether I was good enough for it. Then I started building a fintech company and got the right people together. But still it was hard to justify the risk of trying to beat the market and most likely fail instead of doing well-compensated client work.
What changed my mind was one of our projects, a liquidity provider. It was growing from ICO markets, got more and more clients among crypto derivative exchanges and was being used under increasingly competitive requirements. Our market making strategies hit the limits of their ability to keep the profit above zero — as our old approach was about not doing anything stupid rather than doing something particularly smart. We decided to move the goalpost from not losing money to beating the market as a way to push ourselves to the next level. Even if we failed (which was highly probable), the insights we would get during this process would most likely improve our liquidity provider.
We started building a team. We were lucky enough to have access to a mature trading infrastructure, so we could focus on data science. The core of the team were our two most experienced data scientists in time series and clustering and a data engineer who helped with data processing, backtesting and tooling. Also, I was responsible for research and management. Overall, we put together a pretty well-balanced team, and it was time to get our hands dirty.
It was intense. We treated this project as a kind of intellectual war. We did not discuss or plan it; it just naturally worked out this way. It felt like this attitude was the only way to overcome the enormous gap that was separating us from the people who can consistently beat the market. We worked at full speed; the drive was going through the roof. It was R&D in its pure form: exhausting in the most exciting way possible.
The first two months were fun. We got improvement after improvement. It seemed like we were getting so close to profitability... But then we hit a plateau, and over the next two months we made next to zero progress, and there was a growing feeling of discouragement. Psychologically it was a very tough period. Can we do this? Aren’t we wasting our time?
To explain why we got stuck we need to talk about market making. On the surface, it is a “get rich fast” strategy. Let’s take crypto derivative exchanges as an example. There you get a 0.025% rebate (negative commission) for each trade. Using the most naive market making strategy, on Bitmex alone you can make two to three thousand trades a day, which is about 50–70% a day just in rebates. Sounds good, right? But don’t hurry to buy a Lamborghini: market making is a place where dreams come to die, thanks to adverse selection (when your buy orders get executed while the market is going down and the other way around) and inventory risk (when the price jumps against your position).

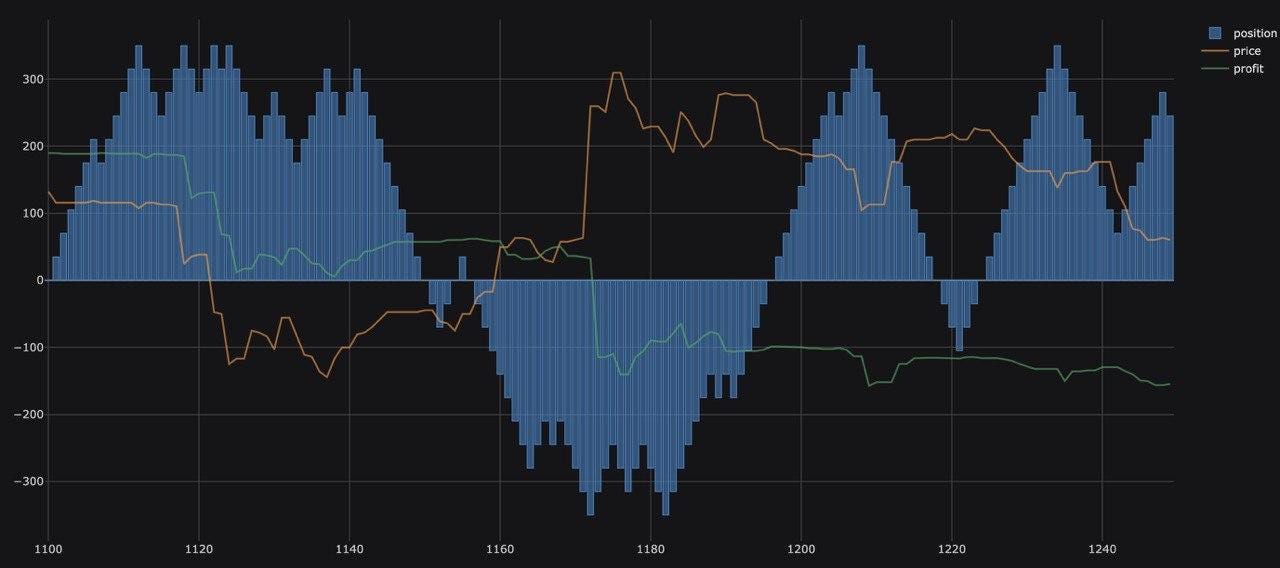
Let’s take a look at the graph that shows us the position, price and profit for a naive market making strategy in action. First, we make trades and end up with a long position, but then the price drops, and so does our profit. Consequently, our position turns short and the price jumps up, so we lose to better-informed players again. Rinse and repeat.
There are dozens of recent white papers mostly derived from the classic Avellaneda and Stoikov (2008) which put together most of the moving parts of market making under a solid mathematical framework. Those articles are a great source of highly relevant ideas but they have nuances: some assume you have unlimited inventory, others ignore price ticks, use outdated order book modeling, are not compatible with fee structure in crypto, ignore market direction, etc.
Initially, we believed a key to profitability was the ability to predict the market for relatively long periods. This way in the example above we would be able to predict whether the market considerably drops or it’s a small fluctuation, so we act appropriately. We've been building more and more complex predictive models, working on more and more ridiculous features, but no matter what we tried, our results were mediocre. It was definitely my biggest mistake from the management perspective as it took me way longer than it should have to understand we were stuck and close to agony.
At some point, we had to accept the fact that we could not predict the market as far and as well as we supposedly needed, so we tried to reduce the prediction horizon. We worked on every single thing in the range between market microstructure and market regimes. Eventually it allowed us to get a pretty good idea of what was going on with the market, and within that context, we could use our predictive engine more efficiently. This seemingly apparent sweet spot brought us the first profitable version after six and a half months of hard work.
Last week, almost three months later, this strategy had reached its first $100k in profit and our liquidity provider blew up. It was so close to being a failure but ended up being the most successful project we've had so far. Coronavirus was growing, everything was collapsing and our company was growing like never before. It almost felt immoral.
It feels like we've finished the first milestone, so I wanted to sit down and put all the thoughts together. Below, I will cover some ideas/topics that I did not manage to include into the main story.
Machine learning models
We're guilty of trying to find a silver bullet machine learning method. We’ve started with decision tree ensembles (random forest, gradient boosting) mostly because we had good experience with them in the past and they are quite forgiving in regard to data preprocessing. Later we added SVM under the influence of many white papers praising it. Also Garch and Hidden Markov Models have some application in our system.
Then we've spent quite a lot of time working on neural networks but we did not get outstanding results. I believe we would be better off if we kept it simple at first and stick to traditional machine learning models, which are very under-appreciated, and got to neural networks when all other elements of the system were more or less mature (we've been giving them a second, more thorough look recently).
Hacks
While I find our overall architecture quite beautiful, we do have hacks here and there and a perfectionist inside me has been consistently unhappy about it. The argument that I used to convince myself that it was okay was that if we compared this level of data science to software development, it would not be a beautiful code with solid architecture written in a high-level language. It would be an ugly, highly-optimized code in C that gave up the last bit of architecture for the sake of performance.
Backtesting
We've made two mistakes with backtesting.
At first we did not put enough effort into it and our backtesting results were quite different from live trading, so we did not use backtesting at its full potential. Later it became an obvious bottleneck, so we tried to make our backtesting more realistic.
The first step is rather straightforward. You assume your order gets to the end of the queue at a specific price level, then with every matching trade your position in the queue gets closer. Then you need to dig deeper by trying to emulate latency, handle cancellations (canceled orders could've been before or after you in the queue), take into account hidden orders (you can get an idea of the amount of hidden orders based on how much more volume it takes to take a level in comparison to what you see in the order book), etc.
It worked surprisingly well and we've got a pretty reliable tool to verify our ideas. It helped us make multiple improvements but also led to the second mistake — we started overusing it.
When you're stuck, the thought of finding the magical values of parameters that will fix everything for you is very comforting. Nine out of ten times it’s a bad idea. It takes a lot of computational resources and even if you get optimal values this way, they will likely get overfit to historical data.
Strategy choice
Market making is very subtle, nuanced, and insidious. There’re reasons why it’s usually done by hedge funds or banks and even they occasionally lose a lot of money. If I could go back and change one thing, I would start with a simpler strategy, hopefully, bring it to profitability and only after that — take on market making. There were just way too many things going on, it was overwhelming, and it negatively influenced our chances.
Luck
I remember at least three occasions when we got lucky by getting a breakthrough we did not “deserve”.
For example, at some point, we struggled with detecting trends under specific market conditions. Among other things, we were playing with an idea that was mentioned between the lines in a hardly relevant white paper. It turned out to be a game changer. We haven’t seen that idea anywhere else, so the chances of finding it were slim to none. We would probably have eventually discovered it ourselves, but it would have taken longer, and we may have needed to cancel the project by that time. When margins are that thin, luck becomes crucial.
And it is exactly what makes me slightly paranoid about whether we can consistently bring this kind of results. What keeps me reasonably optimistic is that the luck we’ve got so far was quite healthy and in a way logical. My gut feeling tells me we've got enough insights to pull off one or two more profitable projects of even larger scale but then we’ll hit a long and painful plateau.
Sources of insights
Machine learning application in finance is an extremely secretive field, so when you’re starting from scratch, getting insights is very problematic. Here are the sources of information that helped us:
- Advances in Financial Machine Learning
It’s the best book to get an overview of how to use machine learning in finance. It helped us build the first remotely decent model within a reasonable timeline.
2. White papers
We’ve gone through hundreds of white papers on the way, and they certainly are a great source of insights. Though it can take weeks or even months to thoroughly process a large white paper while the ideas in many of them were at best validated with basic backtesting, so you have to choose your fights.
3. Fundamental literature
There’s a lot of useful information in the fundamental literature on time-series, statistics and econometrics that is hidden from the public eye. It’s not literally hidden, it’s out there, but there’s just no hype around it as it’s frankly quite boring stuff. But the deeper we go, the more we find ourselves leaning towards this kind of resource.
4. Medium
At first, I was a little skeptical of Medium, as, let's face it, there are some questionable articles over here. But with time, I warmed up towards Medium as it has a great recommendation engine, and it’s refreshing to receive a new set of relevant articles every morning. Due to the sheer volume of the articles on Medium, you get exposed to a diverse set of ideas; and it complements deeper but narrower insights from the sources above.
Computational resources
The only thing that really matters in regard to a data scientist’s hardware is the feedback loop. If you worked on something today and ran an experiment overnight, ideally, you need to get at least some kind of feedback the next morning so that you could find out whether you’re moving in the right direction or not.
If you need to train models all the time, cloud GPU is either too expensive or free but not powerful enough, so for R&D we mostly stick to our own hardware. For desktops, we use 6-cores AMD Ryzen 3600 and Nvidia RTX 2060, and for workstations that are shared among data scientists, we prefer 32-core AMD Threadripper 3970x and Nvidia RTX 2080 TIs.
Technically Nvidia RTX 20xx GPUs are outdated as Nvidia was rumoured to release 7nm GPUs in March with an expected 30–50% increase in performance and memory for the same price. Like most of the releases recently, it was delayed, but as China gets back on track, it’s probably a good idea to wait if you are going to buy an expensive GPU.
P.S.
I tried to keep this post as substantive as possible but as you understand, there're limits to what I can share. Hopefully you found at least some of the aspects of our experience relevant or at least entertaining.