https://zhuanlan.zhihu.com/p/56102593
DolphinDB和Druid都是分布式的分析型时序数据库。尽管前者使用c++开发,后者使用java开发,两者在架构、功能、应用场景等方面有很多共同点。本报告在SQL查询、数据导入、磁盘占用空间等方面对两者进行性能的对比测试。
测试数据集使用约300GB的美国股票市场交易与报价数据。通过测试我们发现:
- DolphinDB的数据写入速度大约是Druid的30倍。
- DolphinDB的查询速度是Druid的10倍左右。
- DolphinDB数据库的静态空间占用比Druid高80%,运行时使用的总磁盘空间略低于Druid。
1. 系统介绍
DolphinDB是一款分析型的分布式时序数据库,由C++编写,内置流数据处理引擎,并行计算引擎和分布式计算的功能。DolphinDB database 内置分布式文件系统,支持集群水平和垂直扩展。提供类SQL和Python的脚本语言,不仅可以用SQL进行对数据进行操作,也可以完成更为复杂的内存计算。提供其它常用编程语言的API,方便与已有应用程序集成。DolphinDB能对万亿级数据快速处理,在金融领域中的历史数据分析建模与实时流数据处理,以及物联网领域中的海量传感器数据处理与实时分析等场景中均有非常出色的表现。
Druid是一个由Java语言实现的OLAP数据仓库,适用于万亿级别数据量上的低延时查询和插入以及实时流数据分析。Druid采用分布式、SN架构和列式存储、倒排索引、位图索引等关键技术,具有高可用性和高扩展性的特点。同时,Druid提供了多种语言接口,支持部分SQL。
2. 系统配置
2.1 硬件配置
本次测试的硬件配置如下:
设备:DELL OptiPlex 7060
CPU:Inter(R) Core™ i7-8700 CPU @ 3.20GHz,6核心12线程
内存:32GB
硬盘:256GB SSD,1.8TB希捷ST2000DM008-2FR102机械硬盘
操作系统:Ubuntu 16.04 x64
2.2 环境配置
本次的测试环境为单服务器下的多节点集群。设置DolphinDB的数据节点的个数为4个,单个数据节点最大可用内存设置为4GB。设置Druid的节点个数为5个,分别为overload,broker,historical,coordinator和middleManager。Druid默认对查询结果进行缓存,影响测试时通过多次查询求平均值这个方法的正确性,故关闭query cache的功能。为不影响Druid的写入性能测试, 关闭了Druid的roll up功能。其他配置均服从默认配置。
原始csv文件存储在HDD上。数据库存储在SSD上。
3. 测试数据集
本次测试采用了2007年8月美国股票市场level1的TAQ数据集。TAQ数据集按日分为23个csv文件,单个文件大小在7.8G到19.1G不等,整个数据集大小约290G,共有6,561,693,704条数据。
测试数据集TAQ在DolphinDB和Druid中各个字段的数据类型如下所示:
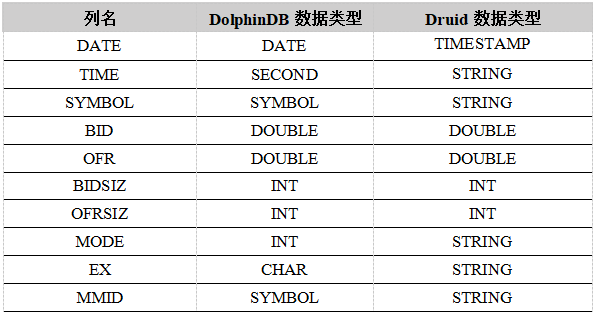
在Druid中,DATE字段指定为timestamp列。其它字段均用作dimension字段。
4. 数据分区方案
在DolphinDB中,采用股票代码+日期组合分区,其中按照股票代码范围分为128个分区,按照日期分为23个分区。
Druid仅支持时间范围分区,因此我们把DATE列指定为timestamp类型,以日为单位,共划分为23个分区。
5. 对比测试
我们从数据库查询性能、I/O性能以及磁盘占用空间三方面对DolphinDB和Druid进行了对比测试。
5.1 数据库查询性能
DolphinDB脚本语言支持SQL语法,同时针对时序数据进行了功能扩展。Druid提供了基于Json数据格式的语言进行查询,同时也提供了dsql来进行SQL查询。本次测试使用Druid自带的dsql。
我们对TAQ数据集进行了若干种常用的SQL查询。为了减少偶然因素对结果的影响,本次查询性能测试对每种查询操作均进行了10次,对总时间取平均值,时间以毫秒为单位。测试DolphinDB时,我们使用了timer语句来评估SQL语句在服务端的执行时间。由于Druid中没有提供输出查询时间的工具或函数,采用了客户端命令行工具dsql打印的执行时间。Druid返回的执行时间相比DolphinDB,多了查询结果的传输和显示时间。由于查询返回的数据量都很小,dsql与Druid服务器又在同一个节点上,影响的时间在1ms左右。1ms左右的时间不影响我们的测试结论,因此没有做特殊处理。
7个查询的SQL表示如下表所示。
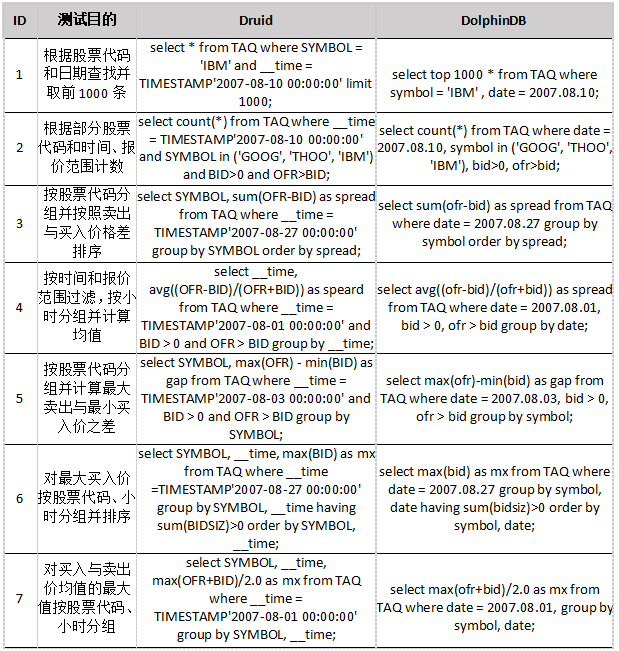
测试结果如下表所示。
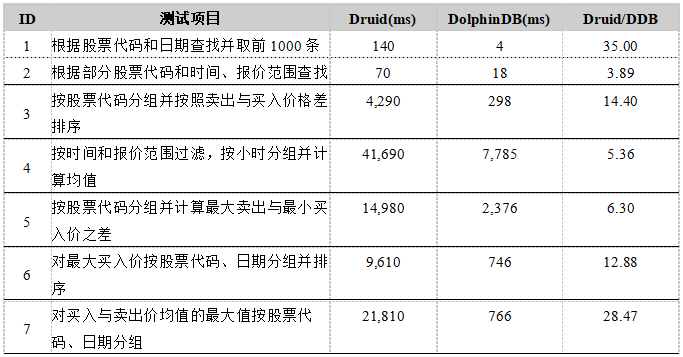
从结果可以看出,对于几乎所有查询,DolphinDB的性能都优于Druid,速度大约是Druid的3到30倍。
由于Druid只允许根据时间戳进行segment的划分,而DolphinDB允许从多个维度上对数据进行划分,在TAQ分区时用了时间和股票代码两个维度,因此在查询中需要根据股票代码过滤或分组的测试(如第1、3、6、7项测试)中,DolphinDB的优势更明显。
5.2 I/O性能测试
我们测试了DolphinDB和Druid在导入单个文件(7.8G)和多个文件(290.8G)时的性能。公平起见,我们关闭了Druid的Roll up功能。测试结果如下表所示,时间以秒为单位。

相同情况下导入单个文件,Druid的导入时间是DolphinDB的16倍以上,导入多个文件时,由于DolphinDB支持并行导入,速度相比Druid更快。数据导入脚本见附录2。
5.3 磁盘占用空间测试
数据导入到DolphinDB和Druid后,我们比较了两者的数据压缩率。测试结果如下表所示。

DolphinDB采用LZ4压缩算法,对列式储存的数据进行快速压缩。DolphinDB的SYMBOL类型在压缩之前,会使用字典编码,将字符串转化成整型。Druid在数据储存过程中,对timestamp和metrics采用LZ4算法直接压缩,对dimensions字段使用字典编码、位图索引以及roaring bitmap进行压缩。使用字典编码可以减少字符串存储的空间,位图索引可快速地进行按位逻辑操作,位图索引压缩进一步节约了储存空间。
本次测试中,DolphinDB数据库占用的磁盘空间比Druid高出约80%。造成这个差异的主要因素是BID和OFR两个浮点型字段在DolphinDB和Druid上的压缩比有很大的差异。在DolphinDB上,这个两个字段的压缩比是20%,而在Druid上高达5%。原因是测试数据集是一个历史数据集,数据已经按照日期和股票两个字段排序。一个股票在短时间内的报价变化很小,unique的报价个数非常有限,Druid使用位图压缩的效果非常好。
虽然Druid数据库的压缩比更高,静态的磁盘空间占用较小,但是Druid运行时会产生segment cache目录,总的磁盘空间占用达到65 GB。而DolphinDB运行时不需要额外的空间,总的磁盘空间反而比Druid略小。
6. 小结
DolphinDB对于Druid的性能优势来自于多个方面,包括(1)存储机制和分区机制上的差别,(2)开发语言(c++ vs java)上的差别,(3)内存管理上的差别,以及(4)算法(如排序和哈希)实现上的差别。
在分区上,Druid只支持时间类型的范围分区,相对于支持值分区、范围分区、散列分区和列表分区且每张表可根据多个字段进行组合分区的DolphinDB而言缺乏灵活性。DolphinDB的分区粒度更细,不易出现数据或查询集中到某个节点的情况,在查询时DolphinDB所需要扫描的数据块也更少,响应时间更短,性能也更加出色。
除去性能,DolphinDB在功能上比Druid也更为完善。在SQL的支持方面,DolphinDB支持非常强大的window function机制,对SQL join的支持也更为全面。对时序数据特有的sliding function,asof join, window join,DolphinDB都有很好的支持。DolphinDB集数据库、编程语言和分布式计算于一体,除了常规的数据库查询功能,DolphinDB也支持更为复杂的内存计算,分布式计算以及流计算。
DolphinDB和Druid在运行方式上也略有区别。在Druid崩溃后或是将segment-cache清空后重启时,需要花大量的时间重新加载数据,将每一个segment解压到segment-cache中再进行查询,效率较低,cache也会占用较大的空间,因此Druid在重新启动时需要等待较长的时间,并且要求更大的空间。
附录
附录1. 环境配置
(1) DolphinDB配置
controller.cfg
localSite=localhost:9919:ctl9919
localExecutors=3
maxConnections=128
maxMemSize=4
webWorkerNum=4
workerNum=4
dfsReplicationFactor=1
dfsReplicaReliabilityLevel=0
enableDFS=1
enableHTTPS=0
cluster.nodes
localSite,mode
localhost:9910:agent,agent
localhost:9921:DFS_NODE1,datanode
localhost:9922:DFS_NODE2,datanode
localhost:9923:DFS_NODE3,datanode
localhost:9924:DFS_NODE4,datanode
cluster.cfg
maxConnection=128
workerNum=8
localExecutors=7
webWorkerNum=2
maxMemSize=4
agent.cfg
workerNum=3
localExecutors=2
maxMemSize=4
localSite=localhost:9910:agent
controllerSite=localhost:9919:ctl9919
(2) Druid配置
_common
# Zookeeper
druid.zk.service.host=zk.host.ip
druid.zk.paths.base=/druid
# Metadata storage
druid.metadata.storage.type=mysql
druid.metadata.storage.connector.connectURI=jdbc:mysql://db.example.com:3306/druid
# Deep storage
druid.storage.type=local
druid.storage.storageDirectory=var/druid/segments
# Indexing service logs
druid.indexer.logs.type=file
druid.indexer.logs.directory=var/druid/indexing-logs
broker:
Xms24g
Xmx24g
XX:MaxDirectMemorySize=4096m
# HTTP server threads
druid.broker.http.numConnections=5
druid.server.http.numThreads=25
# Processing threads and buffers
druid.processing.buffer.sizeBytes=2147483648
druid.processing.numThreads=7
# Query cache
druid.broker.cache.useCache=false
druid.broker.cache.populateCache=false
coordinator:
Xms3g
Xmx3g
historical:
Xms8g
Xmx8g
# HTTP server threads
druid.server.http.numThreads=25
# Processing threads and buffers
druid.processing.buffer.sizeBytes=2147483648
druid.processing.numThreads=7
# Segment storage
druid.segmentCache.locations=[{"path":"var/druid/segment-cache","maxSize":0}]
druid.server.maxSize=130000000000
druid.historical.cache.useCache=false
druid.historical.cache.populateCache=false
middleManager:
Xms64m
Xmx64m
# Number of tasks per middleManager
druid.worker.capacity=3
# HTTP server threads
druid.server.http.numThreads=25
# Processing threads and buffers on Peons
druid.indexer.fork.property.druid.processing.buffer.sizeBytes=4147483648
druid.indexer.fork.property.druid.processing.numThreads=2
overload:
Xms3g
Xmx3g
附录2. 数据导入脚本
DolphinDB database 脚本:
if (existsDatabase("dfs://TAQ"))
dropDatabase("dfs://TAQ")
db = database("/Druid/table", SEQ, 4)
t=loadTextEx(db, 'table', ,"/data/data/TAQ/TAQ20070801.csv")
t=select count(*) as ct from t group by symbol
buckets = cutPoints(exec symbol from t, 128)
buckets[size(buckets)-1]=`ZZZZZ
t1=table(buckets as bucket)
t1.saveText("/data/data/TAQ/buckets.txt")
db1 = database("", VALUE, 2007.08.01..2007.09.01)
partition = loadText("/data/data/buckets.txt")
partitions = exec * from partition
db2 = database("", RANGE, partitions)
db = database("dfs://TAQ", HIER, [db1, db2])
db.createPartitionedTable(table(100:0, `symbol`date`time`bid`ofr`bidsiz`ofrsiz`mode`ex`mmid, [SYMBOL, DATE, SECOND, DOUBLE, DOUBLE, INT, INT, INT, CHAR, SYMBOL]), `quotes, `date`symbol)
def loadJob() {
filenames = exec filename from files('/data/data/TAQ')
db = database("dfs://TAQ")
filedir = '/data/data/TAQ'
for(fname in filenames){
jobId = fname.strReplace(".csv", "")
jobName = jobId
submitJob(jobId,jobName, loadTextEx{db, "quotes", `date`symbol,filedir+'/'+fname})
}
}
loadJob()
select * from getRecentJobs()
TAQ = loadTable("dfs://TAQ","quotes");
Druid脚本:
{
"type" : "index",
"spec" : {
"dataSchema" : {
"dataSource" : "TAQ",
"parser" : {
"type" : "string",
"parseSpec" : {
"format" : "csv",
"dimensionsSpec" : {
"dimensions" : [
"TIME",
"SYMBOL",
{"name":"BID", "type" : "double"},
{"name":"OFR", "type" : "double"},
{"name":"BIDSIZ", "type" : "int"},
{"name":"OFRSIZ", "type" : "int"},
"MODE",
"EX",
"MMID"
]
},
"timestampSpec": {
"column": "DATE",
"format": "yyyyMMdd"
},
"columns" : ["SYMBOL",
"DATE",
"TIME",
"BID",
"OFR",
"BIDSIZ",
"OFRSIZ",
"MODE",
"EX",
"MMID"]
}
},
"metricsSpec" : [],
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "day",
"queryGranularity" : "none",
"intervals" : ["2007-08-01/2007-09-01"],
"rollup" : false
}
},
"ioConfig" : {
"type" : "index",
"firehose" : {
"type" : "local",
"baseDir" : "/data/data/",
"filter" : "TAQ.csv"
},
"appendToExisting" : false
},
"tuningConfig" : {
"type" : "index",
"targetPartitionSize" : 5000000,
"maxRowsInMemory" : 25000,
"forceExtendableShardSpecs" : true
}
}
}