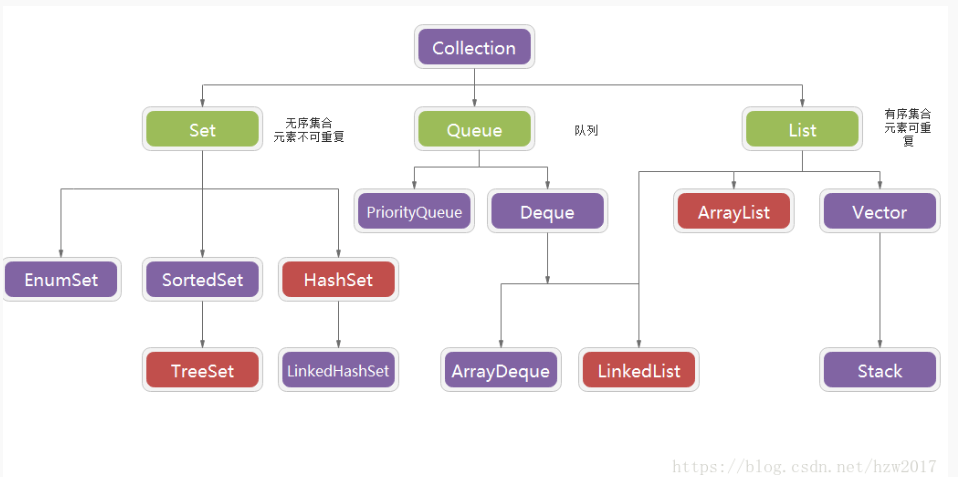
List , Set, Map都是接口,前两个继承至Collection接口,Map为独立接口
Set下有HashSet,LinkedHashSet,TreeSet
List下有ArrayList,Vector,LinkedList
Map下有Hashtable,LinkedHashMap,HashMap,TreeMap
Connection接口
List
— List 有序(这里的有序指的是存储有序,而不是会自动排序),可重复
ArrayList
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程不安全,效率高
Vector
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程安全,效率低
LinkedList
优点: 底层数据结构是链表,查询慢,增删快。
缺点: 线程不安全,效率高
List是可以添加一个或多个null的,null将作为对象添加到List里,List长度会随之增加
Set
—Set 无序,唯一
HashSet
底层数据结构是哈希表。(无序,唯一)
不能保证元素的排列顺序,顺序有可能发生变化
不是同步的
集合元素可以是null,但只能放入一个null
如何来保证元素唯一性?
1.依赖两个方法:hashCode()和equals()
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable { static final long serialVersionUID = -5024744406713321676L; private transient HashMap<E,Object> map; // Dummy value to associate with an Object in the backing Map private static final Object PRESENT = new Object(); /** * Constructs a new, empty set; the backing <tt>HashMap</tt> instance has * default initial capacity (16) and load factor (0.75). */ public HashSet() { map = new HashMap<>(); } ... }
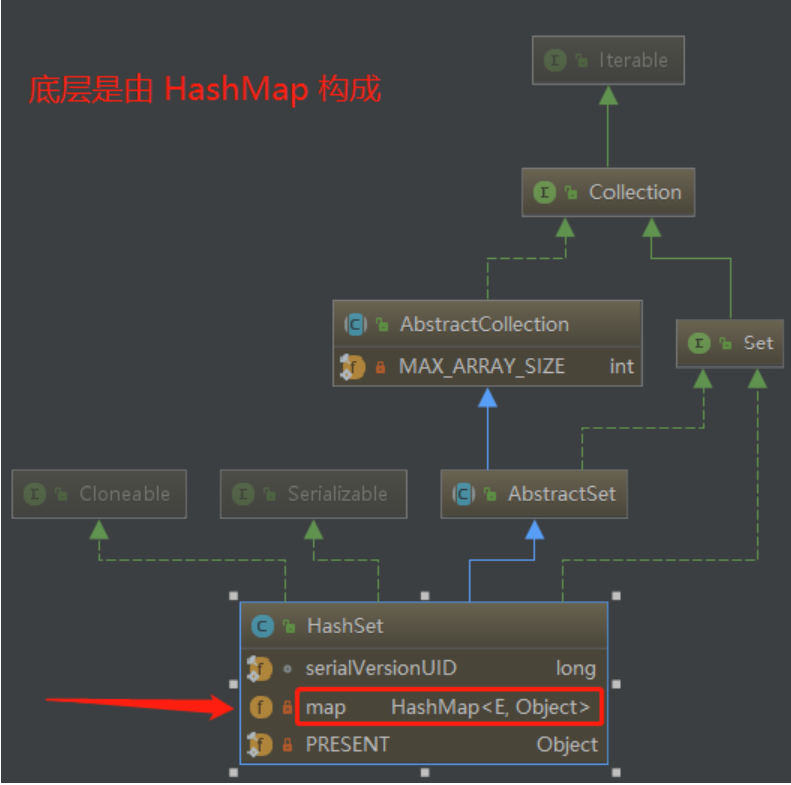
HashSet 也实现了 Cloneable 接口和 Serializable 接口,分别用来支持克隆以及支持序列化。还实现了 Set 接口,该接口定义了 Set 集合类型的一套规范.
第一个定义一个 HashMap,作为实现 HashSet 的数据结构;第二个 PRESENT 对象,因为前面讲过 HashMap 是作为键值对 key-value 进行存储的,而 HashSet 不是键值对,选择 HashMap 作为实现,其原理就是存储在 HashSet 中的数据 作为 Map 的 key,而 Map 的value 统一为 PRESENT。
https://www.cnblogs.com/ysocean/p/9809046.html
LinkedHashSet
底层数据结构是链表和哈希表。(FIFO插入有序,唯一)
1.由链表保证元素有序
2.由哈希表保证元素唯一
LinkedHashSet是HashSet的一个“扩展版本”,HashSet并不管什么顺序,不同的是LinkedHashSet会维护“插入顺序”。HashSet内部使用HashMap对象来存储它的元素,而LinkedHashSet内部使用LinkedHashMap对象来存储和处理它的元素。
TreeSet
底层数据结构是红黑树。(唯一,有序)
1. 如何保证元素排序的呢?
自然排序
比较器排序
2.如何保证元素唯一性的呢?
根据比较的返回值是否是0来决定
Treeset不仅实现了set接口还实现了java.util.sortedSet接口 从而保证在遍历集合时按照递增的顺序获得对象。
原文:https://blog.csdn.net/zhangqunshuai/article/details/80660974
Vector
1 Vector的方法都是同步的(Synchronized),是线程安全的(thread-safe),而ArrayList的方法不是,由于线程的同步必然要影响性能,因此,ArrayList的性能比Vector好。
2 当Vector或ArrayList中的元素超过它的初始大小时,Vector会将它的容量翻倍,而ArrayList只增加50%的大小,这样,ArrayList就有利于节约内存空间。
3 Arraylist 需要根据索引位置访问集合中的对象它的效率就较高,但是删除和添加操作效率低原因是之后的的所有对象都要移动
ArrayList
1 ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据
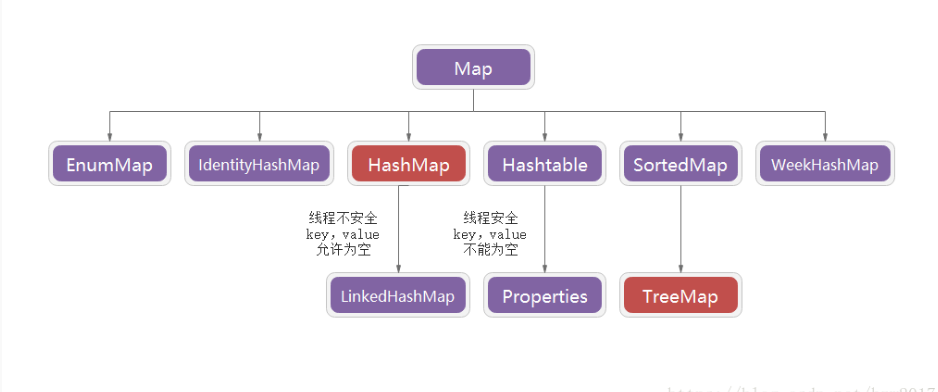
Map
Hashmap
数组链表
这是HashMap在并发环境下使用中最为典型的一个问题,就是在HashMap进行扩容重哈希时导致Entry链形成环。一旦Entry链中有环,势必会导致在同一个桶中进行插入、查询、删除等操作时陷入死循环。
ConcurrentHashMap
JDK1.5开始加入了ConcurrentHashMap
一个ConcurrentHashMap实例中包含由若干个Segment实例组成的数组,而一个Segment实例又包含由若干个桶,每个桶中都包含一条由若干个 HashEntry 对象链接起来的链表。特别地,ConcurrentHashMap 在默认并发级别下会创建16个Segment对象的数组,如果键能均匀散列,每个 Segment 大约守护整个散列表中桶总数的 1/16
(通俗:内存直接分为了16个segment,每个segment实际上还是存储的哈希表,写入的时候,先找到对应的segment,然后锁这个segment,写完,解锁,)
ConcurrentHashMap具体是怎么实现线程安全的呢,肯定不可能是每个方法加synchronized,那样就变成了HashTable。
从ConcurrentHashMap代码中可以看出,它引入了一个“分段锁”的概念,具体可以理解为把一个大的Map拆分成N个小的HashTable,根据key.hashCode()来决定把key放到哪个HashTable中。
在ConcurrentHashMap中,就是把Map分成了N个Segment,put和get的时候,都是现根据key.hashCode()算出放到哪个Segment中:
ConcurrentHashMap就是一个分段的hashtable ,根据自定的hashcode算法生成的对象来获取对应hashcode的分段块进行加锁,不用整体加锁,提高了效率
concurrentHashMap 读加锁吗?读是怎么实现不加锁的
2.Hashmap 和hashtable的区别
1 HashMap不是线程安全的 2 HashTable是线程安全的
HashMap完成了Map接口,主要区别在于HashMap允许空(null)键值(key),由于非线程安全,效率上可能高于Hashtable。
HashMap允许将null作为一个entry的key或者value,而Hashtable不允许。
HashMap把Hashtable的contains方法去掉了,改成containsvalue和containsKey。因为contains方法容易让人引起误解。
Hashtable继承自Dictionary类,而HashMap是Java1.2引进的Map interface的一个实现。
最大的不同是,Hashtable的方法是Synchronize的,而HashMap不是,在多个线程访问Hashtable时,不需要自己为它的方法实现同步,而HashMap 就必须为之提供外同步。
2.Hashtable中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。即是说,在多线程应用程序中,不用专门的操作就安全地可以使用Hashtable了;而对于HashMap,则需要额外的同步机制。但HashMap的同步问题可通过Collections的一个静态方法得到解决:
Map Collections.synchronizedMap(Map m)
这个方法返回一个同步的Map,这个Map封装了底层的HashMap的所有方法,使得底层的HashMap即使是在多线程的环境中也是安全的。
在HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键,而应该用containsKey()方法来判断。
TreeMap
TreeMap 是一个有序的key-value集合,它是通过红黑树实现的。
TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合。
TreeMap 实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。
TreeMap 实现了Cloneable接口,意味着它能被克隆。
TreeMap 实现了java.io.Serializable接口,意味着它支持序列化。
TreeMap基于红黑树(Red-Black tree)实现。该映射根据其键的自然顺序进行排序(对Integer来说,其自然排序就是数字的升序;对String来说,其自然排序就是按照字母表排序),或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。
另外,TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fastl的。
List、Set、Map的区别
List:1.可以允许重复的对象。
2.可以插入多个null元素。
3.是一个有序容器,保持了每个元素的插入顺序,输出的顺序就是插入的顺序。
4.常用的实现类有 ArrayList、LinkedList 和 Vector。ArrayList 最为流行,它提供了使用索引的随意访问,而 LinkedList 则对于经常需要从 List 中添加或删除元素的场合更为合适。
Set:1.不允许重复对象
2. 无序容器,你无法保证每个元素的存储顺序,TreeSet通过 Comparator 或者 Comparable 维护了一个排序顺序。
3. 只允许一个 null 元素
4.Set 接口最流行的几个实现类是 HashSet、LinkedHashSet 以及 TreeSet。最流行的是基于 HashMap 实现的 HashSet;TreeSet 还实现了 SortedSet 接口,因此 TreeSet 是一个根据其 compare() 和 compareTo() 的定义进行排序的有序容器。
Map
1Map不是collection的子接口或者实现类。Map是一个接口。
2.Map 的 每个 Entry 都持有两个对象,也就是一个键一个值,Map 可能会持有相同的值对象但键对象必须是唯一的。
3. TreeMap 也通过 Comparator 或者 Comparable 维护了一个排序顺序。
4. Map 里你可以拥有随意个 null 值但最多只能有一个 null 键。
5.Map 接口最流行的几个实现类是 HashMap、LinkedHashMap、Hashtable 和 TreeMap。(HashMap、TreeMap最常用)