一、进程
UNIX系统 init进程PID为1
1.进程的内存布局
(1)Text Section: 文本区, 存储执行的代码
(2)Data Secrion: 全局和静态变量
(3)Heap:程序运行中动态分配的内存
(4)Stack:临时存储的数据(例如:函数参数,函数返回值, 局部变量)
文本区和数据区大小固定,有编译时确定,在程序运行过程中不会改变;堆和栈在程序运行中动态变化。

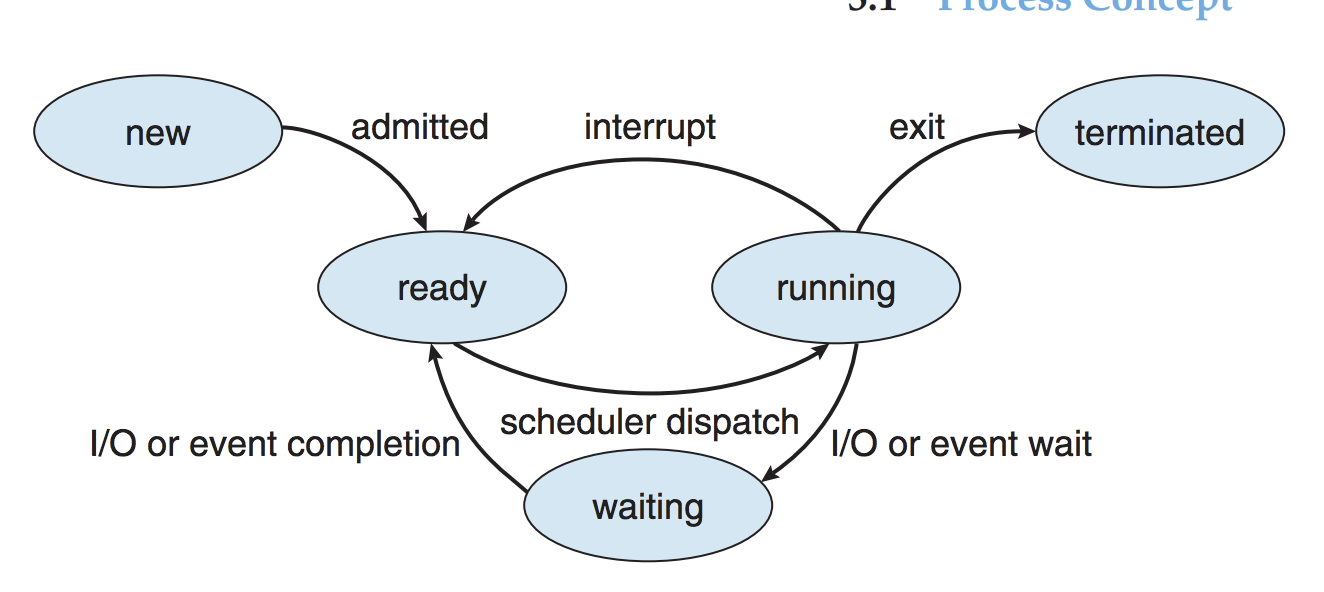
2.进程状态
(1)New创建:进程被创建
(2)Run运行:Instructions are being executed。
(3)Wait阻塞或等待:进程等待某些事件(IO完成或信号)
(4)Ready就绪:进程等待被分给处理器。
(5)Terminated中止: The process has finished execution.
3.进程控制块(Process Control Block,PCB 或 Task Control Block)
进程在操作系统中由进程控制块表示,进程控制块包含了一个特定线程的许多信息
(1)Process State进程状态:New, Ready,Running,Waiting等
(2)Program Counter 程序计数器:计数器指示进程下一个执行指令的地址
(3)CPU Registers CPU寄存器:包含加法器、索引寄存器、栈指针、通用寄存器等任何状态信息,这些状态信息和程序计数器在进程被中断时要被保存下来
(4)CPU-scheduling information:进程优先级、指向调度队列的指针和其他调度指针。
(5)Memory-management information内存管理信息
(6)Accounting information:此信息包括CPU的数量和使用时间、时间限制、帐号、作业或进程号等。
(7)I/O status information IO状态信息:包含分配给进程IO的列表

4.进程的调度(Scheduling)
(1)进程的调度机制
(2)进程创建和中止
(3)进程间通信
二、线程
三、CPU调度
进程选择由短期调度程序(short-term scheduler) 或CPU调度程序执行
1. CPU调度策略发生环境:
(1)当一个进程有运行态切换到等待状态(I/O请求等)
(2)当一个进程由运行态切换到就绪态(中断)
(3)当一个进程由等待态切换到就绪态(I/O完成)
(4)当一个进程终止时。
非抢占调度只发生在(1)和(4)环境,否则为抢占调度。
2.分派程序:切换上下文;切换用户模式;跳转到用户程序到合适位置,以重新启动程序
3.调度准则:
(1)CPU使用率
(2)吞吐量:一个时间单元完成进程的数量
(3)周转时间:从进程提交到进程完成时间,包过等待时间和CPU执行、I/O执行时间,所有时间段之和
(4)等待时间:在就绪队列中等待所花费时间之和
(5)响应时间:从提交到在就绪队列第一次被响应所需要的时间
4.调度算法
(1)先到先服务调度(FCFS):先请求CPU的进程先分配到CPU,平均等待时间较长。非抢占式
(2)最短作业优先调度(SJF):CPU区间时间短的最先调度,理论上调度最佳,但由于很难知道下一个CPU区间的长度,需要预测。抢占或非抢占式都可能
抢占式SJF称为最短剩余时间优先调度:新进程与当前进程剩余时间比较。 SJF会产生饥饿。
(3)优先级调度:可以是抢占式或非抢占式,优先级调度会造成无穷阻塞或饥饿(低优先级进程无穷等待CPU)。解决方法是老化:逐渐增加在系统等待很长时间的进程的优先级
(4)轮转法调度:为分时系统设计,在FCFS基础上增加抢占,按时间片段运行,在时间片段运行完,不管该进程还有没有释放CPU,都要被抢占。时间片段大小选择是重要问题:
时间太长变为FCFS算法,时间太短上下文切换开销大。
Linux调度程序时抢占的,基于优先级的算法
四、进程同步:信号量和锁
锁:
1. 自旋锁:当一个进程位于其临界区时,其他试图进入临界区的进程必须在进入代码中连续地循环(忙等待)。自旋锁对于单处理器,忙等待浪费CPU时间,但优势在于自旋锁不用上下文切换(有时候上下文切换花费更多时间),自旋锁经常用在多处理器(一个线程在处理自旋锁时,另一个线程在另一个处理器上在其临界区内执行)
2.互斥锁:进程在等待进入临界区时是阻塞,将进程放入与互斥锁相关的等待队列中,并将进程的状态切换成等待状态,控制转到CPU调度程序,以选择另一个进程来执行。
五、 物理内存和虚拟内存
CPU能直接访问的存储器只有内存和处理器内的寄存器。
六、协程
协程,又称微线程,既不是进程,也不是线程,而是函数调用,
优势:1、协程都是在一个线程中执行,与多线程比较,协程不需要上下文切换;2、不需要锁机制,同一时刻只有一个协程运行,不存在同时写冲突,协程由程序自身控制执行顺序
对于多核,多进程+多线程
六、缓存和缓冲个人理解
缓存和缓冲作用是想相同的,弥补两边处理速度的差异
缓存是数据流向是从低速到高速,例如内存到CPU有高速缓存,磁盘到内存有缓存,是防止处理速度快的一方等待,操作系统从低速的一方先预读一部分数据,这里要求缓存的速度与高速的一方接近才有意义。
缓冲是数据流向是从高速到低速,防止低速一方处理不过来而造成数据丢失,现将数据缓冲起来。
七、系统调用
系统调用就是用户在程序中调用操作系统所提供的一个子功能,也就是系统API,系统调用可以被看做特殊的公共子程序。系统中的各种共享资源都由操作系统统一掌管,因此在用户程序中,凡是与资源有关的操作(如存储分配、进行I/O传输及管理文件等),都必须通过系统调用方式向操作系统提出服务请求,并由操作系统代为完成。通常,一个操作系统提供的系统调用命令有几十个乃至上百个之多。这些系统调用按照功能大致可以分为以下几类:
- 设备管理:完成设备的请求或释放,以及设备启动等功能。
- 文件管理:完成文件的读、写、创建及删除等功能
- 进程控制:完成进程的创建、撤销、阻塞、及唤醒的功能
- 进程通信:完成进程之间的消息传递或信号的传递
- 内存管理:完成内存的分配、回收以及获取作业占用内存区大小及始址等功能。
系统调用和库函数区别
系统调用:是操作系统为用户态运行的进程和硬件设备(如CPU、磁盘、打印机等)进行交互提供的一组接口,即就是设置在应用程序和硬件设备之间的一个接口层。可以说是操作系统留给用户程序的一个接口。再来说一下,linux内核是单内核,结构紧凑,执行速度快,各个模块之间是直接调用的关系。放眼望整个linux系统,从上到下依次是用户进程->linux内核->硬件。其中系统调用接口是位于Linux内核中的,如果再稍微细分一下的话,整个linux系统从上到下可以是:用户进程->系统调用接口->linux内核子系统->硬件,也就是说Linux内核包括了系统调用接口和内核子系统两部分;或者从下到上可以是:物理硬件->OS内核->OS服务->应用程序,其中操作系统起到“承上启下”的关键作用,向下管理物理硬件,向上为操作系服务和应用程序提供接口,这里的接口就是系统调用了。
一般地,操作系统为了考虑实现的难度和管理的方便,它只提供一少部分的系统调用,这些系统调用一般都是由C和汇编混合编写实现的,其接口用C来定义,而具体的实现则是汇编,这样的好处就是执行效率高,而且,极大的方便了上层调用。
库函数:顾名思义是把函数放到库里。是把一些常用到的函数编完放到一个文件里,供别人用。别人用的时候把它所在的文件名用#include<>加到里面就可以了。一般是放到lib文件里的。一般是指编译器提供的可在c源程序中调用的函数。可分为两类,一类是c语言标准规定的库函数,一类是编译器特定的库函数。(由于版权原因,库函数的源代码一般是不可见的,但在头文件中你可以看到它对外的接口)
libc中就是一个C标准库,里面存放一些基本函数,这些基本函数都是被标准化了的,而且这些函数通常都是用汇编直接实现的。
库函数一般可以概括的分为两类,一类是随着操作系统提供的,另一类是由第三方提供的。随着系统提供的这些库函数把系统调用进行封装或者组合,可以实现更多的功能,这样的库函数能够实现一些对内核来说比较复杂的操作。比如,read()函数根据参数,直接就能读文件,而背后隐藏的比如文件在硬盘的哪个磁道,哪个扇区,加载到内存的哪个位置等等这些操作,程序员是不必关心的,这些操作里面自然也包含了系统调用。而对于第三方的库,它其实和系统库一样,只是它直接利用系统调用的可能性要小一些,而是利用系统提供的API接口来实现功能(API的接口是开放的)。部分Libc库中的函数的功能的实现还是借助了系统掉调用,比如printf的实现最终还是调用了write这样的系统调用;而另一些则不会使用系统调用,比如strlen, strcat, memcpy等。
实时上,系统调用所提供给用户的是直接而纯粹的高级服务,如果想要更人性化,具有更符合特定情况的功能,那么就要我们用户自己来定义,因此就衍生了库函数,它把部分系统调用包装起来,一方面把系统调用抽象了,一方面方便了用户级的调用。系统调用和库函数在执行的效果上很相似(当然库函数会更符合需求),但是系统调用是运行于内核状态;而库函数由用户调用,运行于用户态。
系统调用是为了方便使用操作系统的接口,而库函数则是为了人们编程的方便。