1.String类型“==”比较
样例代码如下:
package com.luna.test; public class StringTest { public static void main(String[] args) { String str1 = "todo"; String str2 = "todo"; String str3 = "to"; String str4 = "do"; String str5 = str3 + str4; String str6 = new String(str1); System.out.println("------普通String测试结果------"); System.out.print("str1 == str2 ? "); System.out.println( str1 == str2); System.out.print("str1 == str5 ? "); System.out.println(str1 == str5); System.out.print("str1 == str6 ? "); System.out.print(str1 == str6); System.out.println(); System.out.println("---------intern测试结果---------"); System.out.print("str1.intern() == str2.intern() ? "); System.out.println(str1.intern() == str2.intern()); System.out.print("str1.intern() == str5.intern() ? "); System.out.println(str1.intern() == str5.intern()); System.out.print("str1.intern() == str6.intern() ? "); System.out.println(str1.intern() == str6.intern()); System.out.print("str1 == str6.intern() ? "); System.out.println(str1 == str6.intern()); } }
代码运行结果如下所示:
------普通String测试结果------ str1 == str2 ? true str1 == str5 ? false str1 == str6 ? false ---------intern测试结果--------- str1.intern() == str2.intern() ? true str1.intern() == str5.intern() ? true str1.intern() == str6.intern() ? true str1 == str6.intern() ? true
普通String代码结果分析:Java语言会使用常量池保存那些在编译期就已确定的已编译的class文件中的一份数据。主要有类、接口、方法中的常量,以及一些以文本形式出现的符号引用,如类和接口的全限定名、字段的名称和描述符、方法和名称和描述符等。因此在编译完Intern类后,生成的class文件中会在常量池中保存“todo”、“to”和“do”三个String常量。变量str1和str2均保存的是常量池中“todo”的引用,所以str1==str2成立;在执行 str5 = str3 + str4这句时,JVM会先创建一个StringBuilder对象,通过StringBuilder.append()方法将str3与str4的值拼接,然后通过StringBuilder.toString()返回一个堆中的String对象的引用,赋值给str5,因此str1和str5指向的不是同一个String对象,str1 == str5不成立;String str6 = new String(str1)一句显式创建了一个新的String对象,因此str1 == str6不成立便是显而易见的事了。
2.String.intern()使用原理
String.intern()是一个Native方法,底层调用C++的 StringTable::intern方法实现。当通过语句str.intern()调用intern()方法后,JVM 就会在当前类的常量池中查找是否存在与str等值的String,若存在则直接返回常量池中相应Strnig的引用;若不存在,则会在常量池中创建一个等值的String,然后返回这个String在常量池中的引用。因此,只要是等值的String对象,使用intern()方法返回的都是常量池中同一个String引用,所以,这些等值的String对象通过intern()后使用==是可以匹配的。由此就可以理解上面代码中------intern------部分的结果了。因为str1、str5和str6是三个等值的String,所以通过intern()方法,他们均会指向常量池中的同一个String引用,因此str1.intern() == str5.intern() == str6.intern()均为true。
3.String.intern() in JDK6
Jdk6中常量池位于PermGen(永久代)中,PermGen是一块主要用于存放已加载的类信息和字符串池的大小固定的区域。执行intern()方法时,若常量池中不存在等值的字符串,JVM就会在常量池中创建一个等值的字符串,然后返回该字符串的引用。除此以外,JVM 会自动在常量池中保存一份之前已使用过的字符串集合。Jdk6中使用intern()方法的主要问题就在于常量池被保存在PermGen中:首先,PermGen是一块大小固定的区域,一般不同的平台PermGen的默认大小也不相同,大致在32M到96M之间。所以不能对不受控制的运行时字符串(如用户输入信息等)使用intern()方法,否则很有可能会引发PermGen内存溢出;其次String对象保存在Java堆区,Java堆区与PermGen是物理隔离的,因此如果对多个不等值的字符串对象执行intern操作,则会导致内存中存在许多重复的字符串,会造成性能损失。
4.String.intern() in JDK7
Jdk7将常量池从PermGen区移到了Java堆区,执行intern操作时,如果常量池已经存在该字符串,则直接返回字符串引用,否则复制该字符串对象的引用到常量池中并返回。堆区的大小一般不受限,所以将常量池从PremGen区移到堆区使得常量池的使用不再受限于固定大小。除此之外,位于堆区的常量池中的对象可以被垃圾回收。当常量池中的字符串不再存在指向它的引用时,JVM就会回收该字符串。可以使用 -XX:StringTableSize 虚拟机参数设置字符串池的map大小。字符串池内部实现为一个HashMap,所以当能够确定程序中需要intern的字符串数目时,可以将该map的size设置为所需数目*2(减少hash冲突),这样就可以使得String.intern()每次都只需要常量时间和相当小的内存就能够将一个String存入字符串池中。
5.intern()适用场景
Jdk6中常量池位于PermGen区,大小受限,所以不建议适用intern()方法,当需要字符串池时,需要自己使用HashMap实现。Jdk7、8中,常量池由PermGen区移到了堆区,还可以通过-XX:StringTableSize参数设置StringTable的大小,常量池的使用不再受限,由此可以重新考虑使用intern()方法。intern()方法优点:执行速度非常快,直接使用==进行比较要比使用equals()方法快很多;内存占用少。虽然intern()方法的优点看上去很诱人,但若不是在恰当的场合中使用该方法的话,便非但不能获得如此好处,反而还可能会有性能损失。下面程序对比了使用intern()方法和未使用intern()方法存储100万个String时的性能,从输出结果可以看出,若是单纯使用intern()方法进行数据存储的话,程序运行时间要远高于未使用intern()方法时:
public class InternTest { public static void main(String[] args) { print("noIntern: " + noIntern()); print("intern: " + intern()); } private static long noIntern(){ long start = System.currentTimeMillis(); for (int i = 0; i < 1000000; i++) { int j = i % 100; String str = String.valueOf(j); } return System.currentTimeMillis() - start; } private static long intern(){ long start = System.currentTimeMillis(); for (int i = 0; i < 1000000; i++) { int j = i % 100; String str = String.valueOf(j).intern(); } return System.currentTimeMillis() - start; } }
程序运行结果:
noIntern: 48 // 未使用intern方法时,存储100万个String所需时间 intern: 99 // 使用intern方法时,存储100万个String所需时间
由于intern()操作每次都需要与常量池中的数据进行比较以查看常量池中是否存在等值数据,同时JVM需要确保常量池中的数据的唯一性,这就涉及到加锁机制,这些操作都是有需要占用CPU时间的,所以如果进行intern操作的是大量不会被重复利用的String的话,则有点得不偿失。由此可见,String.intern()主要 适用于只有有限值,并且这些有限值会被重复利用的场景,如数据库表中的列名、人的姓氏、编码类型等。
6.总结:
String.intern()方法是一种手动将字符串加入常量池中的方法,原理如下:如果在常量池中存在与调用intern()方法的字符串等值的字符串,就直接返回常量池中相应字符串的引用,否则在常量池中复制一份该字符串,并将其引用返回(Jdk7中会直接在常量池中保存当前字符串的引用);Jdk6 中常量池位于PremGen区,大小受限,不建议使用String.intern()方法,不过Jdk7 将常量池移到了Java堆区,大小可控,可以重新考虑使用String.intern()方法,但是由对比测试可知,使用该方法的耗时不容忽视,所以需要慎重考虑该方法的使用;String.intern()方法主要适用于程序中需要保存有限个会被反复使用的值的场景,这样可以减少内存消耗,同时在进行比较操作时减少时耗,提高程序性能。
========================分割线================================
2.深入认识intern()方法
JDK1.7后,常量池被放入到堆空间中,这导致intern()函数的功能不同,具体怎么个不同法,且看看下面代码,这个例子是网上流传较广的一个例子,分析图也是直接粘贴过来的,这里我会用自己的理解去解释这个例子:
String s = new String("1"); s.intern(); String s2 = "1"; System.out.println(s == s2); String s3 = new String("1") + new String("1"); s3.intern(); String s4 = "11"; System.out.println(s3 == s4); 输出结果为: JDK1.6以及以下:false false JDK1.7以及以上:false true 再分别调整上面代码2.3行、7.8行的顺序: String s = new String("1"); String s2 = "1"; s.intern(); System.out.println(s == s2);
String s3 = new String("1") + new String("1"); String s4 = "11"; s3.intern(); System.out.println(s3 == s4); 输出结果为: JDK1.6以及以下:false false JDK1.7以及以上:false false
下面依据上面代码对intern()方法进行分析:
2.1 JDK1.6
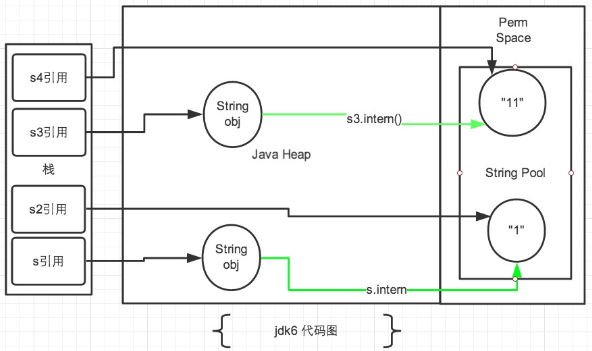
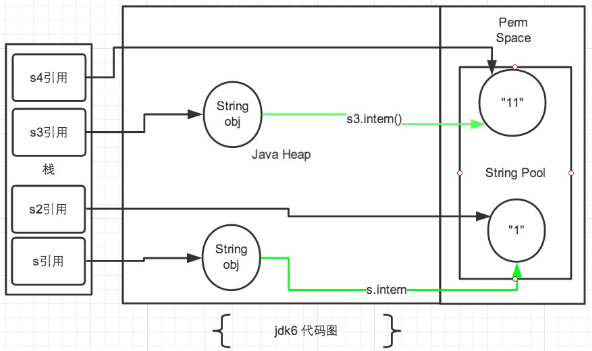
在JDK1.6中所有的输出结果都是 false,因为JDK1.6以及以前版本中,常量池是放在 Perm 区(属于方法区)中的,熟悉JVM的话应该知道这是和堆区完全分开的。
使用引号声明的字符串都是会直接在字符串常量池中生成的,而 new 出来的 String 对象是放在堆空间中的。所以两者的内存地址肯定是不相同的,即使调用了intern()方法也是不影响的。
intern()方法在JDK1.6中的作用是:比如String s = new String("SEU_Calvin"),再调用s.intern(),此时返回值还是字符串"SEU_Calvin",表面上看起来好像这个方法没什么用处。但实际上,在JDK1.6中它做了个小动作:检查字符串池里是否存在"SEU_Calvin"这么一个字符串,如果存在,就返回池里的字符串;如果不存在,该方法会把"SEU_Calvin"添加到字符串池中,然后再返回它的引用。然而在JDK1.7中却不是这样的,后面会讨论。
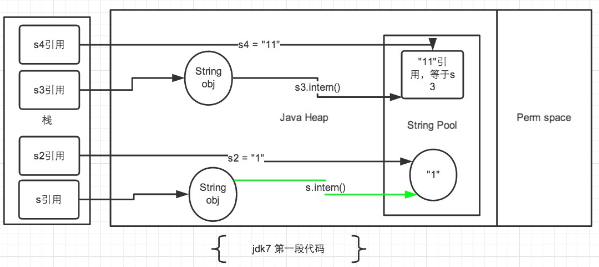
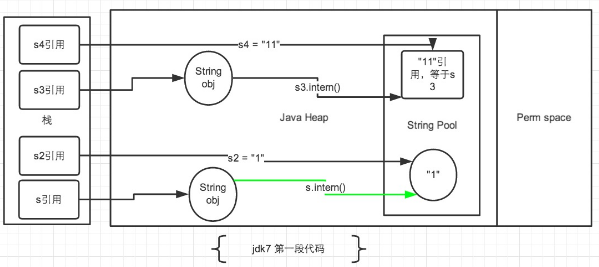
2.2 JDK1.7
针对JDK1.7以及以上的版本,我们将上面两段代码分开讨论。先看第一段代码的情况:
再把第一段代码贴一下便于查看:
String s = new String("1"); s.intern(); String s2 = "1"; System.out.println(s == s2); String s3 = new String("1") + new String("1"); s3.intern(); String s4 = "11"; System.out.println(s3 == s4);
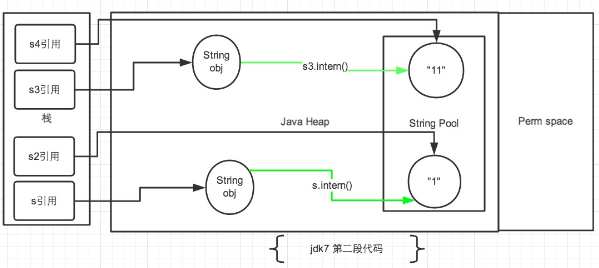
String s = newString("1"),生成了常量池中的“1” 和堆空间中的字符串对象。s.intern(),这一行的作用是s对象去常量池中寻找后发现"1"已经存在于常量池中了。String s2 = "1",这行代码是生成一个s2的引用指向常量池中的“1”对象。结果就是 s 和 s2 的引用地址明显不同。因此返回了false。
String s3 = new String("1") + newString("1"),这行代码在字符串常量池中生成“1” ,并在堆空间中生成s3引用指向的对象(内容为"11")。注意此时常量池中是没有 “11”对象的。s3.intern(),这一行代码,是将 s3中的“11”字符串放入 String 常量池中,此时常量池中不存在“11”字符串,JDK1.6的做法是直接在常量池中生成一个 "11" 的对象。但是在JDK1.7中,常量池中不需要再存储一份对象了,可以直接存储堆中的引用。这份引用直接指向 s3 引用的对象,也就是说s3.intern() ==s3会返回true。String s4 = "11", 这一行代码会直接去常量池中创建,但是发现已经有这个对象了,此时也就是指向 s3 引用对象的一个引用。因此s3 == s4返回了true。
下面继续分析第二段代码:
再把第二段代码贴一下便于查看:
String s = new String("1"); String s2 = "1"; s.intern(); System.out.println(s == s2); String s3 = new String("1") + new String("1"); String s4 = "11"; s3.intern(); System.out.println(s3 == s4);
String s = newString("1"),生成了常量池中的“1” 和堆空间中的字符串对象。String s2 = "1",这行代码是生成一个s2的引用指向常量池中的“1”对象,但是发现已经存在了,那么就直接指向了它。s.intern(),这一行在这里就没什么实际作用了。因为"1"已经存在了。结果就是 s 和 s2 的引用地址明显不同。因此返回了false。
String s3 = new String("1") + newString("1"),这行代码在字符串常量池中生成“1” ,并在堆空间中生成s3引用指向的对象(内容为"11")。注意此时常量池中是没有 “11”对象的。String s4 = "11", 这一行代码会直接去生成常量池中的"11"。s3.intern(),这一行在这里就没什么实际作用了。因为"11"已经存在了。结果就是 s3 和 s4 的引用地址明显不同。因此返回了false。
3 总结
终于要做Ending了。现在再来看一下开篇给的引入例子,是不是就很清晰了呢。
String str1 = new String("SEU") + new String("Calvin"); System.out.println(str1.intern() == str1); System.out.println(str1 == "SEUCalvin");
str1.intern() == str1就是上面例子中的情况,str1.intern()发现常量池中不存在“SEUCalvin”,因此指向了str1。 "SEUCalvin"在常量池中创建时,也就直接指向了str1了。两个都返回true就理所当然啦。
那么第二段代码呢:
String str2 = "SEUCalvin";//新加的一行代码,其余不变 String str1 = new String("SEU")+ new String("Calvin"); System.out.println(str1.intern() == str1); System.out.println(str1 == "SEUCalvin");
也很简单啦,str2先在常量池中创建了“SEUCalvin”,那么str1.intern()当然就直接指向了str2,你可以去验证它们两个是返回的true。后面的"SEUCalvin"也一样指向str2。所以谁都不搭理在堆空间中的str1了,所以都返回了false。
ending.......................