今天我们说说动态页面的抓取,动态页面的概念不是说网页上的内容是活动的,而是刷新的内容由Ajax加载,页面的URL没有变化,具体概念问度娘。
就以男人都喜欢的美女街拍为例,对象为今日头条。
chrome打开今日头条 ->搜索
https://www.toutiao.com/search/?keyword=街拍
开发者工具->network选项卡
图2-1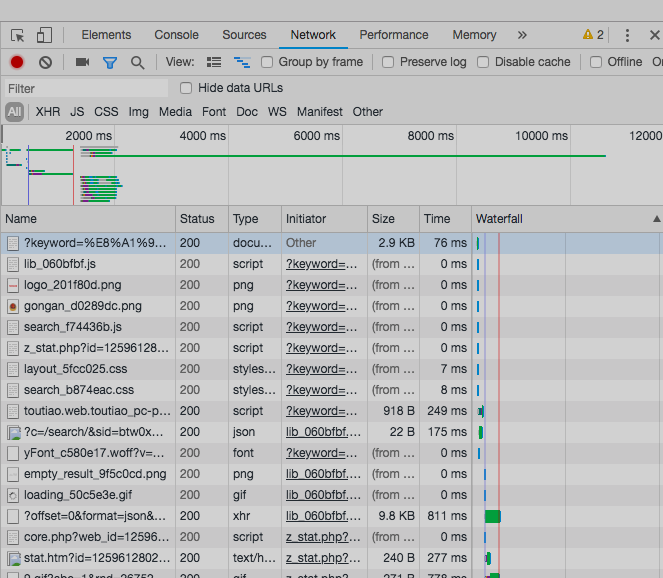
很多条目,各种请求,但Ajax其实有其特殊的请求类型,它叫作xhr。在图6-3中,我们可以发现一个名称以getIndex开头的请求,其Type为xhr,这就是一个Ajax请求。用鼠标点击这个请求,可以查看这个请求的详细信息。
图2-2
选中这个xhr请求后,我们可以看到Request Headers中X-Requested-With:XMLHttpRequest,这就标记了此请求是Ajax请求。
点击一下Preview,即可看到响应的内容,它是JSON格式的。这里Chrome为我们自动做了解析,点击箭头即可展开和收起相应内容,初步分析这里返回的是页面上显示出来的前二十条信息。
图2-3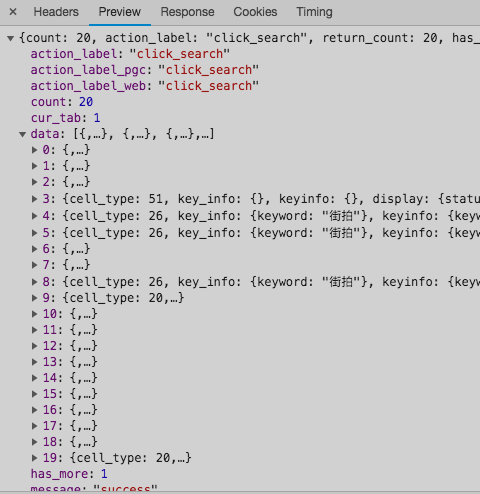
切换回第一个请求,我们发现Response中的信息是这样的
图2-4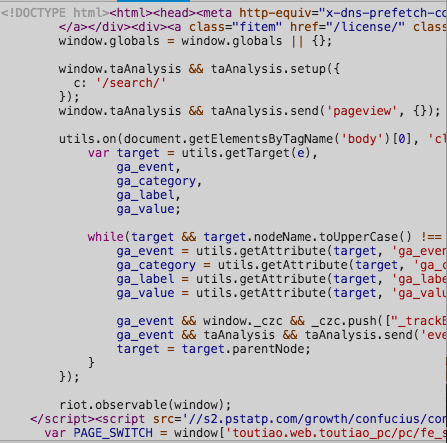
这就是原始链接 https://www.toutiao.com/search/?keyword=街拍 所返回的内容,只有六十多行代码,执行了一些JavaScript,所以我们最终看到的页面不是由初始页面返回的,而是后来执行的JavaScript向服务器发送了Ajax请求,收到返回的真实数据后才显示出来的。这就是动态页面渲染的流程。
明白了整个流程后,我们要做的最重要的事就是分析返回数据的内容,用python模拟Ajax请求,拿到我们所希望抓取的数据。
get_page'offset',
'format''json''keyword''街拍''autoload''true''count''20''cur_tab''1''from''search_tab'}
'https://www.toutiao.com/search_content/?'
try, =params)
if 200return except return None
下滑几次后,发现只有offset参数变化,所以,构造url,requests获得数据
这里拿到的数据是json格式的
download_imageif 'data'for in 'data'if and in title 'title''article_url'
if '''
取出数据中的data段,发现只有前四张图片的地址可以取到,剩下的图片必须进入文章页才能获得,我们取出文章页的url,requests获得文章页数据
get_real_image_path'user-agent''Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36', =headers)
, )
'title'0'gallery: JSON.parse("(.*?)"),'re.S)
,
if 1''''
if and in 'sub_images''url'for in for in
return 'title',
'url' ,
'image_urls'
这里需要加入UA头,否则返回不了数据,拿到数据后,发现图片地址位于
图2-5
这里用正则表达式
匹配符合条件的,gallery: JSON.parse("")中的数据()这里在正则中表达的是转义字符,有兴趣的可以学习一下正则表达式,这里就不赘述了
我们从sub_images中拿到了所有图片地址,下载过程就很简单了
requests图片地址,获得的response中的content就是图片的数据
download_real_imageprint'downloading---'url)
tryif 200return None
RequestException:
print'request image fail---'url)
return None
save_image'{0}/{1}', )
if not
'{0}/{1}.{2}', , )
if not with (file_path'wb'as
我们还可以把图片的标题和地址写入数据库
save_to_mongoif print'save success'result)
return True
完整代码:
jrtt.py
import requests import re import json from hashlib import md5 import os from bs4 import BeautifulSoup import pymongo from config import * import time client = pymongo.MongoClient(MONGO_URL, connect=False) db = client[MONGO_DB] def get_page(offset): params = { 'offset': offset, 'format': 'json', 'keyword': '街拍', 'autoload': 'true', 'count': '20', 'cur_tab': '1', 'from': 'search_tab', } url = 'https://www.toutiao.com/search_content/?' try: response = requests.get(url, params=params) if response.status_code == 200: return response.json() except requests.ConnectionError: return None def save_to_mongo(result): if db[MONGO_TABLE].insert(result): print('save success', result) return True return False def download_real_image(url): print('downloading---', url) try: response = requests.get(url) if response.status_code == 200: save_image(response.content) return None except RequestException: print('request image fail---', url) return None def save_image(content): files_path = '{0}/{1}'.format(os.getcwd(), 'tupian') if not os.path.exists(files_path): os.mkdir(files_path) file_path = '{0}/{1}.{2}'.format(files_path, md5(content).hexdigest(), 'jpg') if not os.path.exists(file_path): with open(file_path, 'wb') as f: f.write(content) def get_real_image_path(article_url): headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'} response = requests.get(article_url, headers=headers) soup = BeautifulSoup(response.text, "lxml") title = soup.select('title')[0].get_text() image_pattern = re.compile('gallery: JSON.parse("(.*?)"),', re.S) result = re.search(image_pattern, response.text) if result: result = result.group(1).replace('\', '') data = json.loads(result) if data and 'sub_images' in data.keys(): sub_images = data.get('sub_images') images_urls = [item.get('url') for item in sub_images] for image_url in images_urls: download_real_image(image_url) return { 'title': title, 'url' : article_url, 'image_urls': images_urls } def download_image(jsonData): if jsonData.get('data'): for item in jsonData.get('data'): if item and 'article_url' in item.keys(): title = item.get('title') article_url = item.get('article_url') result = get_real_image_path(article_url) if result: save_to_mongo(result) ''' 另外一种数据格式cell,cell type太多,主要分析上面一种 else: #original_page_url data = item.get('display') #print(display) #data = json.loads(display) #print(data) if data and 'results' in data.keys(): results = data.get('results') original_page_urls = [item.get('original_page_url') for item in results] # .get('results').get('original_page_url') #title = item.get('display').get('title') #print(title) #print(original_page_urls)''' def main(): STARTPAGE = 1 ENDPAGE = 2 for i in range(STARTPAGE, ENDPAGE): time.sleep(1) offset = i * 20 jsonData = get_page(offset) download_image(jsonData) if __name__ == "__main__": main()
config.py
MONGO_URL = 'localhost' MONGO_DB = 'jiepai' MONGO_TABLE = 'jiepai' GROUP_START = 0 GROUP_END = 20 KEYWORD = '街拍'