机器学习笔记(一)
一、什么是机器学习?
机器学习是从数据中自动分析获取规律(模型),并利用规律对未知数据进行预测。通常这些要处理的数据是保存在文件中而不是数据库中的。
二、数据的格式(dataframe)
一般数据的结构是 特征值+目标值 的形式,当然有时候也可以没有目标值。
数据中对于特征的处理通常用到两个根据 sklearn,pandas
三、数据的特征提取
特征提取是对文本等数据进行特征值化,让计算机更好的理解数据。
3.1字典特征提取
样例:
from sklearn.feature_extraction import DictVectorizer def dictVect(): ''' 字典数据抽取 ''' #实例化 dict=DictVectorizer(sparse=False) data=dict.fit_transform([{'city':'北京','temperature':100},{'city':'上海','temperature':80},{'city':'武汉','temperature':70}]) print(dict.feature_names_) print(data) # ndarray 二维数组 return None if __name__=='__main__': dictVect()
输出结果为一个 二维数组

3.2文本特征抽取及中文问题
英文文本特征抽取方法:
实例:


from sklearn.feature_extraction.text import CountVectorizer def countVect(): """ 对文本进行特征值化 :return: """ cv=CountVectorizer() data=cv.fit_transform(['life is is short , I use python','it is perfect','like it']) print(cv.get_feature_names()) # 不统计单个英文字母 统计单词出现的次数 print(data.toarray()) # sparse矩阵转换为数组 return None if __name__=='__main__': #countVect()
中文文本特征抽取方法一:
(1)准备句子,利用jieba.cut()进行分词
(2)实例化CountVectorizer
(3)将分词结果变成字符串作为fit_transform()的输入值
实例如下:
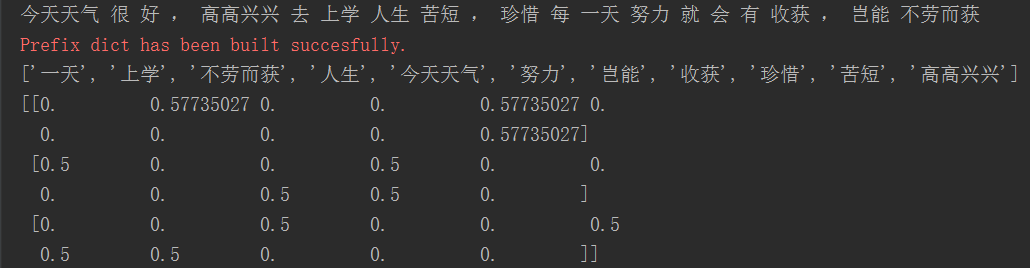
from sklearn.feature_extraction.text import CountVectorizer import jieba def cutWord(): con1=jieba.cut("今天天气很好,高高兴兴去上学") # 对汉语句子进行分词 返回的是一个生成器,不是列表 con2=jieba.cut("人生苦短,珍惜每一天") con3=jieba.cut("努力就会有收获,岂能不劳而获") # 转换成列表 content1=list(con1); content2 = list(con2); content3 = list(con3); # 把列表转换为字符串,以空格分隔原来列表中的元素 c1=' '.join(content1) c2=' '.join(content2) c3=' '.join(content3) return c1,c2,c3 def hanziVector(): """ 中文特征值化 :return: """ c1,c2,c3=cutWord() print(c1,c2,c3) cv = CountVectorizer() data = cv.fit_transform([c1,c2,c3]) print(cv.get_feature_names()) # 不统计单个英文字母 统计单词出现的次数 print(data.toarray()) # sparse矩阵转换为数组 return None if __name__=='__main__': hanziVector()
运行结果:
方法二:使用tf*idf来表示某个词在某篇文章中的重要性
tf (term frequency) 词的频率
idf(inverse document frequency)逆文档频率 log(总文档数量/该词出现的文档数量)
如果某个词或者短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语有很好的类别区分度,适合用来分类。
实例:
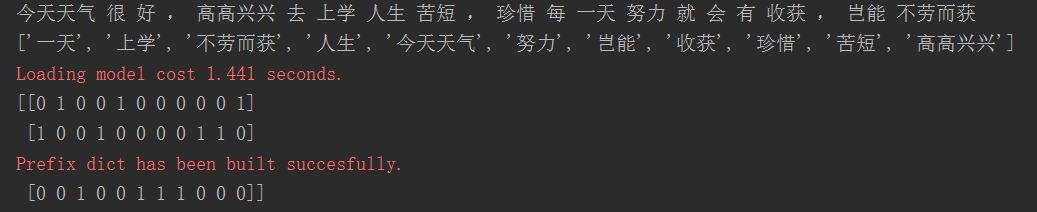
from sklearn.feature_extraction.text import TfidfVectorizer def cutWord(): con1=jieba.cut("今天天气很好,高高兴兴去上学") # 对汉语句子进行分词 返回的是一个生成器,不是列表 con2=jieba.cut("人生苦短,珍惜每一天") con3=jieba.cut("努力就会有收获,岂能不劳而获") # 转换成列表 content1=list(con1); content2 = list(con2); content3 = list(con3); # 把列表转换为字符串,以空格分隔原来列表中的元素 c1=' '.join(content1) c2=' '.join(content2) c3=' '.join(content3) return c1,c2,c3 def tfIdfVector(): """ 中文特征值化 :return: """ c1,c2,c3=cutWord() print(c1,c2,c3) tf=TfidfVectorizer() # tf*idf 代表的是词的重要性程度 data = tf.fit_transform([c1,c2,c3]) print(tf.get_feature_names()) # 不统计单个英文字母 统计单词出现的次数 print(data.toarray()) # sparse矩阵转换为数组 return None if __name__=='__main__': tfIdfVector()
运行结果: