这里是在学习Intel x86_64体系架构时学习到的一些概念,记录下来以供日后参考。如果有错的地方,欢迎指正!
CPU上下文切换(context switch):
这个概念第一次听到对我来说是完全陌生的,但了解之后发现和老师讲的东西有很多联系。现在linux是大多基于抢占式,CPU给每个任务一定的服务时间,当时间片轮转的时候,需要把当前状态保存下来,同时加载下一个任务,这个过程叫做上下文切换。时间片轮转的方式,使得多个任务利用一个CPU执行成为可能,但是保存现场和加载现场,也带来了性能消耗。
缓存一致性协议:
在多核系统中,各个核的cache存储相同变量的副本,当一个处理器更新cache中该变量的副本时会造成各个核之间的缓存不一致,这就是缓存一致性问题。我们要保证在一个核的缓存更新时,其他处理器应该知道该变量已更新,即其他处理器中cache的副本也应该更新,需要使用缓存一致性协议。
CPU处理输入输出的简要过程:
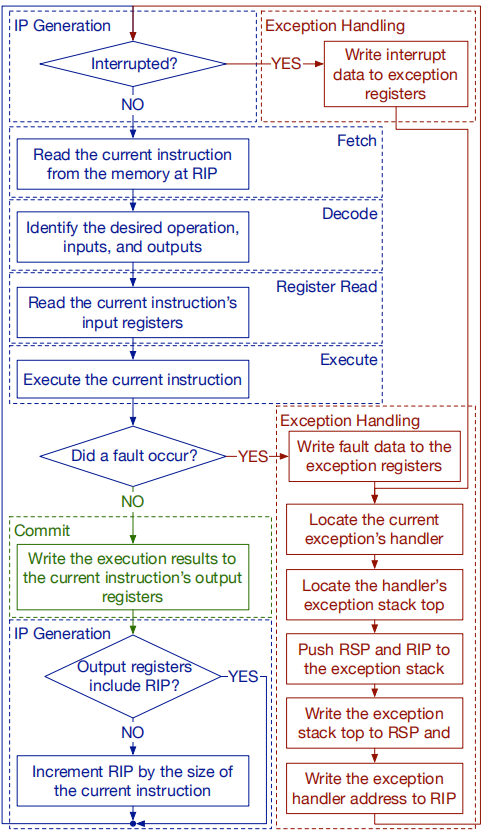
进程内存分配映射方式:
通过地址转换单元,让每个设备都像拥有了一块独立的DRAM。地址转换单元将虚拟地址转化为物理地址(页到页的模式)。
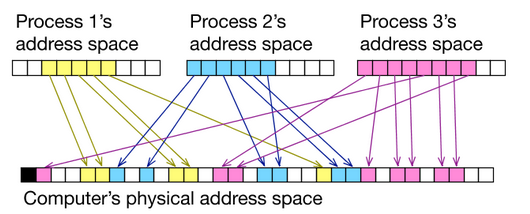
地址映射基本思想
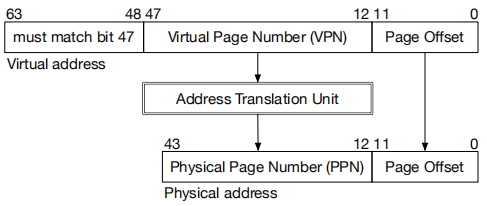
页到页的映射
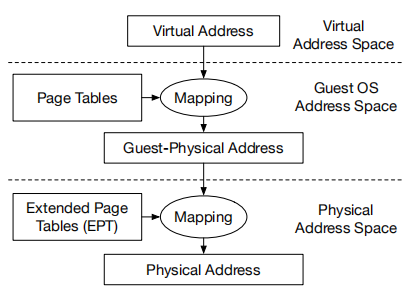
在多个操作系统同时工作下的地址映射
超线程技术:
尽管提高CPU的时钟频率和增加缓存容量后的确可以改善性能,但这样的CPU性能提高在技术上存在较大的难度。实际上在应用中基于很多原因,CPU的执行单元都没有被充分使用。如果CPU不能正常读取数据(总线/内存的瓶颈),其执行单元利用率会明显下降。另外就是大超线程芯片多数执行线程缺乏ILP(Instruction-Level Parallelism,指令级别并行)支持。这些都造成了CPU的性能没有得到全部的发挥。因此,Intel则采用另一个思路去提高CPU的性能,让CPU可以同时执行多重线程,就能够让CPU发挥更大效率,即所谓“超线程(Hyper-Threading,简称“HT”)”技术。超线程技术就是利用特殊的硬件指令,把一个物理内核模拟成两个逻辑内核,让单个处理器都能使用线程级并行计算,进而兼容多线程操作系统和软件,减少了CPU的闲置时间,提高了CPU的运行速度。
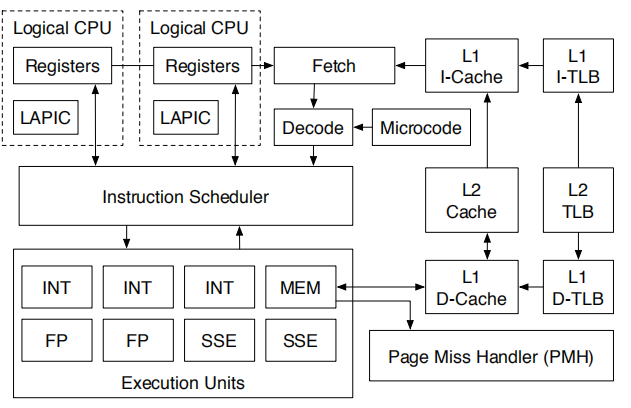
乱序执行(Out-of-Order and Speculative Execution):
处理器基本上会按照程序中书写的机器指令的顺序执行。按照书写顺序执行称为按序执行(In-Order )。按照书写顺序执行时,如果从内存读取数据的加载指令、除法运算指令等延迟(等待结果的时间)较长的指令后面紧跟着使用该指令结果的指令,就会陷入长时间的等待。尽管这种情况无可奈何,但有时,再下一条指令并不依赖于前面那条延迟较长的指令,只要有了操作数就能执行。
此时可以打乱机器指令的顺序,就算指令位于后边,只要可以执行,就先执行,这就是乱序执行(Out-of-Order)。乱序执行时,由于数据依赖性而无法立即执行的指令会被延后,因此可以减轻数据灾难的影响。