1.起源
- 计算机只能识别二进制,于是人类发明各种编码,能让计算机识别
- 英语国家使用ASCII,能够存放英文和拉丁字母
- 中国为了能存放汉字,创造了gb2312,随后又发展了gbk、gb18030
- 万国码unicode,是全球通用的编码,utf-8是遵守unicode编码字符集的一种编码方式
- 各国编码以及utf-8都只能和unicode进行编码解码
- 在做各种编码转换之前,都必须要先解码为unicode
2.编码
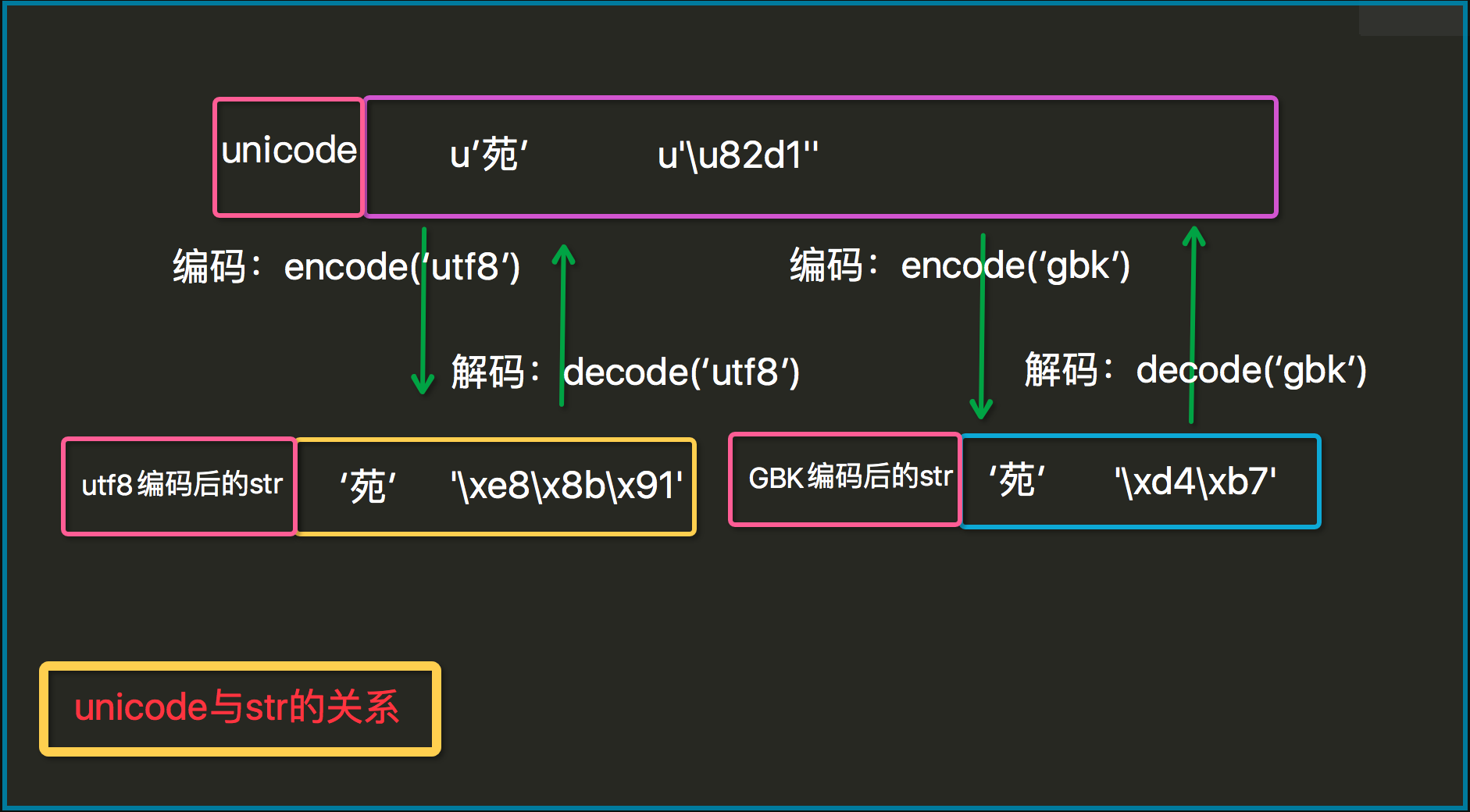
- 万国码转换为各国编码的过程,是编码,即encode
3.解码
- 各国编码转换为统一的万国码的过程,是解码,即decode
4.默认编码方式
- python2 默认采用ASCII,通过在文件头部添加 # -*- coding: utf-8 -*- 可以修改默认编码方式
- python3 默认采用unicode
5.python2举例:utf-8 转 gbk
- 正确
# -*- coding: utf-8 -*-
s = "我是中文字符"
s_to_unicode = s.decode("utf-8")
unicode_to_gbk = s_to_unicode.encode("gbk")
- 错误
utf_to_gbk = s.encode("gbk") #python2会默认先以ASCII解码,此时会报错
6.python2里字符只有两种类型
- str类型:以十六进制的bytes编码方式把字符存放在内存中
-
# -*- coding: utf-8 -*- s = "我是中文字符" print type(s) print repr(s) 输出: <type 'str'> 'xe6x88x91xe6x98xafxe4xb8xadxe6x96x87xe5xadx97xe7xacxa6'# -*- coding: utf-8 -*- s = b"我是中文字符" print type(s) print repr(s) 输出: <type 'str'> 'xe6x88x91xe6x98xafxe4xb8xadxe6x96x87xe5xadx97xe7xacxa6'
-
- unicode类型:以unicode编码方式把字符存放在内存中
-
# -*- coding: utf-8 -*- s = u"我是中文字符" print type(s) print repr(s) 输出: <type 'unicode'> u'u6211u662fu4e2du6587u5b57u7b26'
-
- str和unicode的拼接
-
# -*- coding: utf-8 -*- s = u"i am word" + b"i am word" #这就是python2的特点,它自动的将bytes以ASCII编码集解码成了unicode print type(s) print repr(s) 输出: <type 'unicode'> u'i am wordi am word'
-
# -*- coding: utf-8 -*- s = u"我是中文字符" + b"我是中文字符" #这一次python2自动将bytes解码成unicode时,由于中文不在ASCII编码集中,所以解码报错 print type(s) print repr(s) 报错: UnicodeDecodeError: 'ascii' codec can't decode byte 0xe6 in position 0: ordinal not in range(128)
-
7.python2的编码、解码转换图
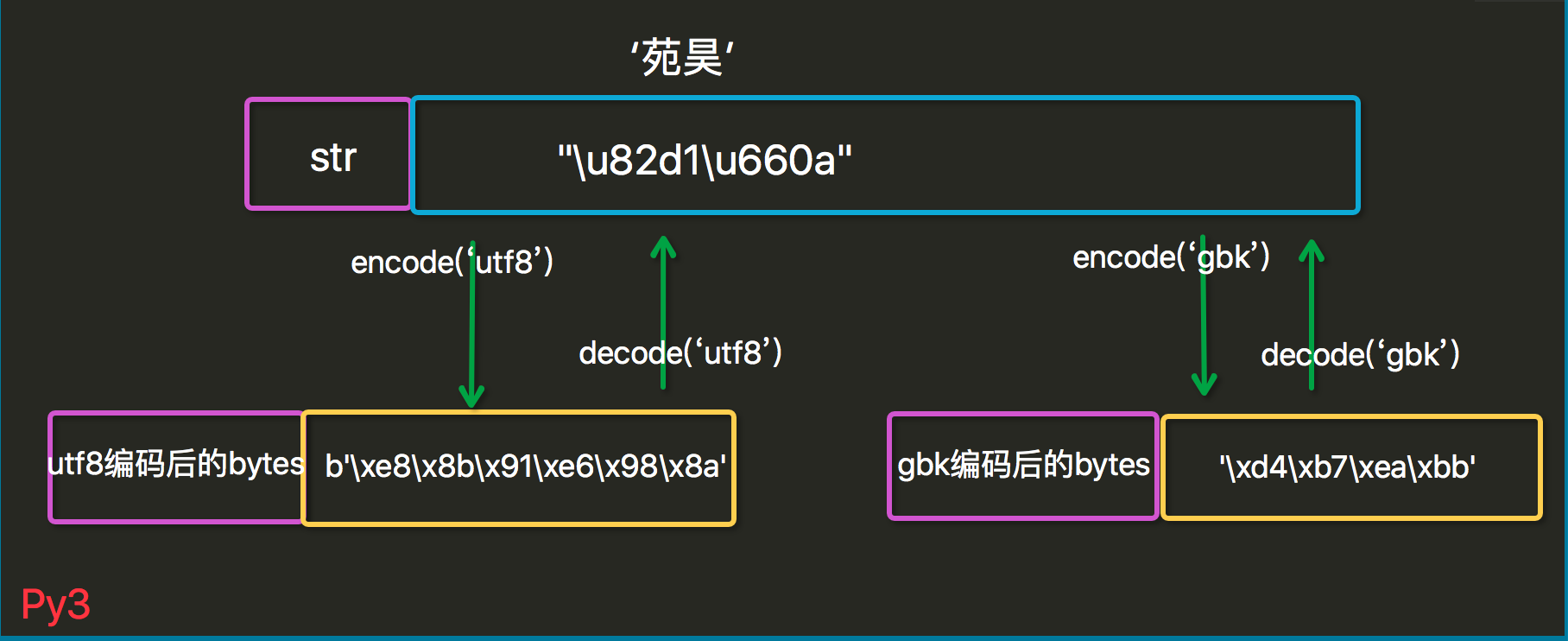
8.python3的编码、解码转换图
2和3的区别:
- python3里字符的两种类型是str和bytes
- str类型是以unicode编码方式把字符存放在内存中
- bytes类型是以bytes编码方式把字符存放在内存中
- str和bytes拼接时,python3不会自动解码
9.记住最重要的一点
- python2中的str对象是以bytes存放,python3中的str对象是以unicode存放