最近在做一个分布式调用链跟踪系统,
在两个地方采用了flume (我使用的flume版本是1.5.0-cdh5.4.4),一个是宿主系统 ,用flume agent进行日志搜集。 一个是从kafka拉日志分析后写入hbase.
后面这个flume(从kafka拉日志分析后写入flume)用了3台 , 系统上线以后 ,线上抛了一个这样的异常:
Caused by: org.apache.flume.ChannelException: Put queue for MemoryTransaction of capacity 100 full, consider committing more frequently, increasing capacity or increasing thread count
at org.apache.flume.channel.MemoryChannel$MemoryTransaction.doPut(MemoryChannel.java:84)
at org.apache.flume.channel.BasicTransactionSemantics.put(BasicTransactionSemantics.java:93)
at org.apache.flume.channel.BasicChannelSemantics.put(BasicChannelSemantics.java:80)
at org.apache.flume.channel.ChannelProcessor.processEventBatch(ChannelProcessor.java:189)
从异常信息直观理解是MemoryChannel的事务的Put队列满了,为什么会这样呢?
我们先从Flume的体系结构说起,Flume是apache一个负责日志采集和传输的开源工具,它的特点是能够很灵活的通过配置实现不同数据存储系统之间的数据交换 。
它有三个最主要的组件:
Source : 负责从数据源获取数据,包含两种类型的Source . EventDrivenSource 和 PollableSource , 前者指的是事件驱动型数据源,故名思议,就是需要外部系统主动送数据 ,比如AvroSource ,ThriftSource ; 而PollableSource 指的是需要Source主动从数据源拉取数据 ,比如KafkaSource 。Source 获取到数据以后向Channel 写入Event 。
Sink : 负责从Channel拉取Event , 写入下游存储或者对接其他Agent.
Channel:用于实现Source和Sink之间的数据缓冲, 主要有文件通道和内存通道两类。
Flume的架构图如下:

而我的flume 配置如下:
a1.sources = kafkasource
a1.sinks = hdfssink hbasesink
a1.channels = hdfschannel hbasechannel
a1.sources.kafkasource.channels = hdfschannel hbasechannel
a1.sinks.hdfssink.channel = hdfschannel
a1.sinks.hbasesink.channel = hbasechannel
a1.sources.kafkasource.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.kafkasource.zookeeperConnect = zk1:2181,zk2:2181,zk3:2181
a1.sources.kafkasource.topic = nagual_topic
a1.sources.kafkasource.groupId = flume
a1.sources.kafkasource.kafka.consumer.timeout.ms = 500
a1.sinks.hdfssink.type = hdfs
a1.sinks.hdfssink.hdfs.path = hdfs://namenode:8020/flume/kafka_events/%y-%m-%d/%H%M
a1.sinks.hdfssink.hdfs.filePrefix = events-prefix
a1.sinks.hdfssink.hdfs.round = true
a1.sinks.hdfssink.hdfs.roundValue = 10
a1.sinks.hdfssink.hdfs.roundUnit = minute
a1.sinks.hdfssink.hdfs.fileType = SequenceFile
a1.sinks.hdfssink.hdfs.writeFormat = Writable
a1.sinks.hdfssink.hdfs.rollInterval = 60
a1.sinks.hdfssink.hdfs.rollCount = -1
a1.sinks.hdfssink.hdfs.rollSize = -1
a1.sinks.hbasesink.type = hbase
a1.sinks.hbasesink.table = htable_nagual_tracelog
a1.sinks.hbasesink.index_table = htable_nagual_tracelog_index
a1.sinks.hbasesink.serializer =NagualTraceLogEventSerializer
a1.sinks.hbasesink.columnFamily = rpcid
a1.sinks.hbasesink.zookeeperQuorum = zk1:2181,zk2:2181,zk3:2181
a1.channels.hdfschannel.type = memory
a1.channels.hdfschannel.capacity= 10000
a1.channels.hdfschannel.byteCapacityBufferPercentage = 20
a1.channels.hdfschannel.byteCapacity = 536870912
我的flume agent从kafka拉取日志以后,转换成hbase 的row put操作,中间采用了memchannel ,为什么会出现之前提到的异常呢? 通过通读一遍源码, 基本找到了问题所在:
我们把源码拆解成以下几个主要步骤来分析:
1、flume 的启动:
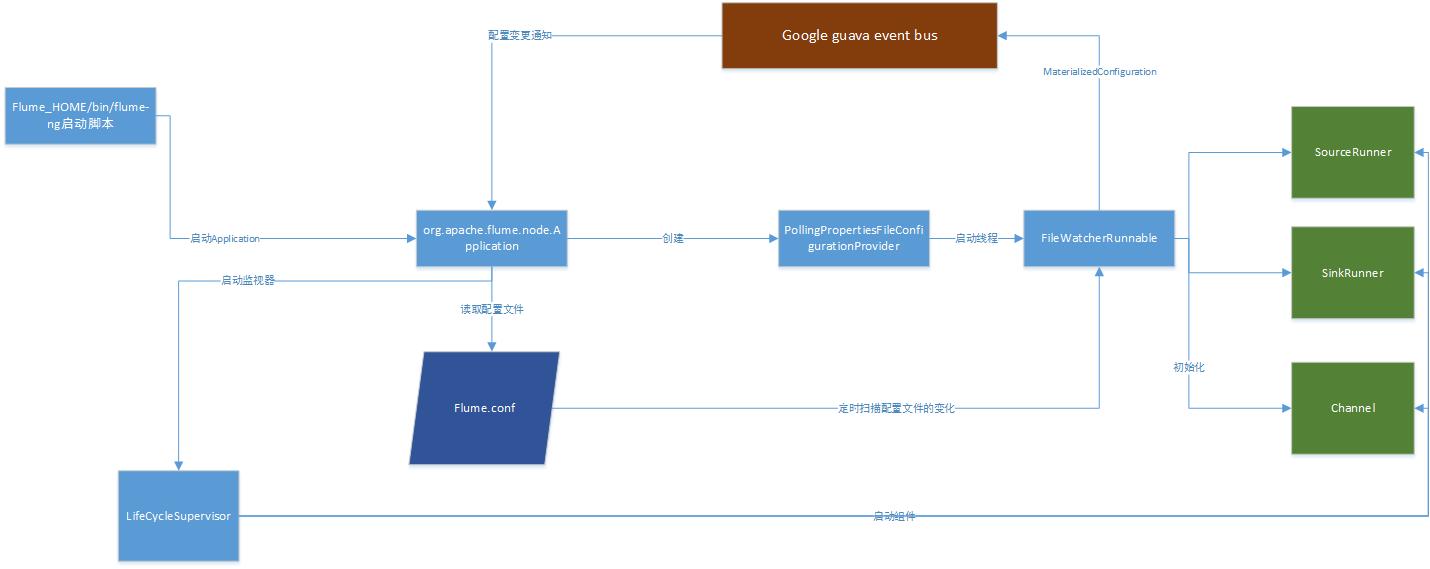
如上图所示, 整个flume 启动的主要流程是这样的:
FLUME_HOME/bin目录中的flume-ng启动脚本启动Application , Application创建一个PollingPropertiesFileConfigurationProvider, 这个Provider的作用是启动 一个配置文件的监控线程FileWatcherRunnable ,定时监控配置文件的变更,
一旦配置文件变更,则重新得到SinkRunner, SourceRunner以及channel的配置, 包装成MaterialedConfiguration,通过google guava的eventbus 推送配置变更给Application ,Application启动一个LifeCycleSupervisor,由它来负责监控
SourceRunner ,SinkRunner,Channel的运行情况 。 SourceRunner ,SinkRunner ,Channel都继承或实现了LifeCycleAware接口,LifeCycleSupervisor通过定时检查这些组件的期望状态是否和当前状态一致, 如果不一致则调用期望状态对应的方法,
(具体代码可以参考LifeCycleSupervisor的内部类MonitorRunnable) . 按照 Channel 、 SinkRunner 、 SourceRunner(可以理解为先接水管,再接水盆,再接水龙头)顺序进行启动,每个组件的启动都做什么呢?
以我的flume配置文件来说明:
(1) MemChannel
我们首先先介绍一下MemChannel的几个配置参数:
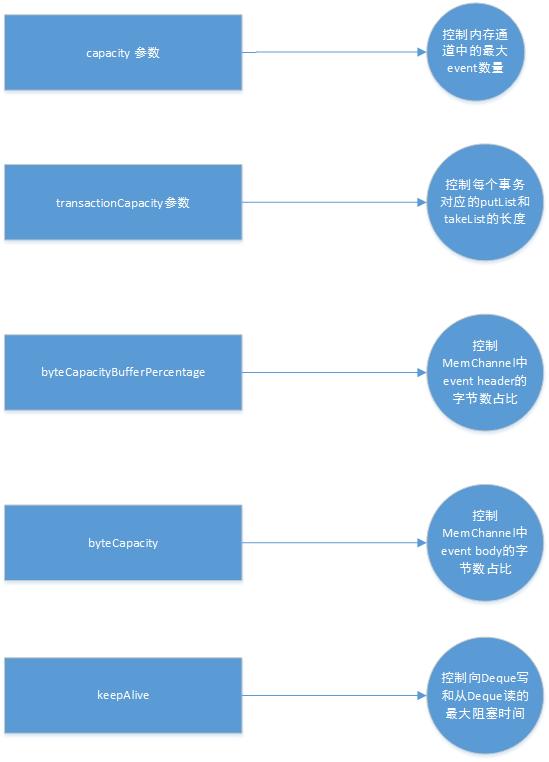
capacity :控制了MemChannel中一个LinkedBlockingDeque<Event> (我们后面简称为MemDeque)的最大event个数。
transactionCapacity: 控制了一个MemChannel的事务(MemoryTransaction)中putList 和takeList两个 LinkedBlockingDeque 的最大长度 。
byteCapacityBufferPercentage: 控制了MemDeque中event header 的占比, 默认是20%
byteCapacity:控制了MemDeque的最大字节数, 默认值是应用分配到的最大堆内存(Xmx参数指定)的 80% (我们称之为x ),这个值x乘以 1 - byteCapacityBufferPercentage * 0.01 就得到了MemDeque中event body的最大字节数。如何利用这个参数来进行流控, 我们后面还有详细说明。
keepalive : 控制了一个 MemChannel 事务从MemDeque中读写操作的最大阻塞时间 , 单位:秒。
启动以后, 建立了一个LinkedBlockingDeque ,这是一个双端队列,可以进行双向读写,并且用capacity 参数控制了它的最大长度, 另外还创建了几个信号量Semaphore ,
queueRemaining: 标识MemDeque的初始容量,
queueStored : 标识MemDeque写入的 event数量,也就是待处理的event 数量。
bytesRemaing:标识MemDeque 中还能写入多少字节的flume event body;
(2) SinkRunner:
它的机制是启动一个所谓的PollingRunner 线程 ,通过轮询操作,调用一个 SinkProcessor来进行实际的轮询处理, 而这个SinkProcessor则调用 Sink的process 方法进行event处理, 在轮询的处理上,有一个所谓的 补偿机制( backoff) ,就是当sink获取不到 event 的时候, PollingRunner 线程需要等待一段backoff时间,等channel中的数据得到了补偿再来进行pollling 操作。而hbasesink 在启动的时候,则把hbase 操作相关的配置:htable, columnfamily ,hbase zk集群的配置信息准备好了。也就是说SinkRunner采用的方式是Pull .
(3) SourceRunner:
SourceRunner包含两类, 一类是对应EventDrivenSource 的 EventDrivenSourceRunner , 一个是对应PollableSource的PollableSourceRunner , 简单的说,前者是push ,后者是pull 。
EventDrivenSource 有代表性的是thrift source , 在本地启动java nio server以后, 从外部接收event ,交给ThriftSource 内部的ThriftSourceHandler进行处理。
而后者PollableSourceRunner ,则通过启动一个PollingRunner线程 ,类似SinkRunner中的轮询处理策略 ,启动Source , 在Source内部, 使用ChannelProcessor处理events , ChannelProcessor内部会走一组过滤器构建的过滤器链 ,然后通过通道选择器ChannelSelector选择好通道以后 ,启动事务 ,把一批event 写入Channel .
我们用下面这张示意图来说明各组件启动以后的内部运作原理:
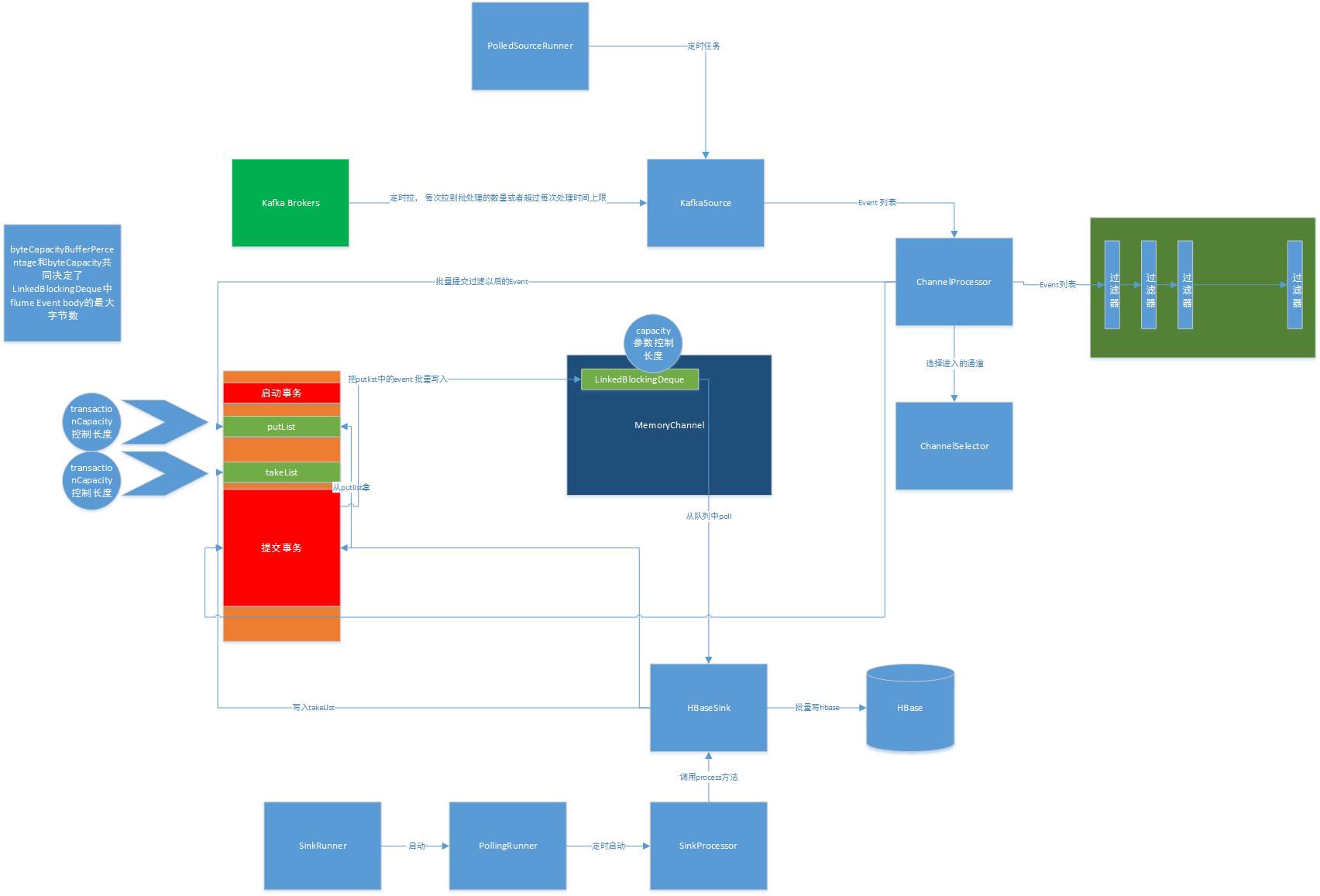
整个图有些复杂, 说明如下:
PollingSourceRunner通过线程启动定时任务 ,间隔一段时间调用kafkasource 从kafka broker 拉取日志,拉完以后,进入一个ChannelProcessor,这个通道处理器先通过一个过滤器链对event进行过滤 ,过滤以后,通过一个ChannelSelector通道选择器,选择evnet要投递的Channel , 然后启动Channel 下的一个事务 (注意,这个事务是用ThreadLocal维持的,也就是说一个线程对应了一个事务) , 事务启动以后,批量向事务MemoryTransaction的一个putList的尾部写入,putlist是一个LinkedBlockingDeque .
事务提交的时候, 把putlist中的event批量移除, 转移到MemoryChannel的一个LinkedBlockingDeque 里面来.
而SinkRunner则启动PollingRunner , 也通过定时启动任务,调用SinkProcessor,最后调用HbaseSink的process方法,这个方法也负责启动一个事务 ,批量从MemoryChannel的LinkedBlockingDeque中拉取event , 写入takelist ,批量做完hbase 的put操作以后,做memoryTransaction的事务提交操作。事务提交的处理逻辑前面描述过。
而负责进行通道过载保护,正是在MemoryTransaction事务的提交时刻做的 ,这个过载保护的代码可以参考MemoryChannel的MemoryTransaction 内部 类的doCommit方法, 它的思路是这样的:
比较事务提交的时候,takelist和putlist的大小,如果takelist的长度比 putlist 长度要小, 则认为sink的消费能力(takelist长度标识)要比source的生产能力(putlist)要弱, 此时,需要通过一个bytesRemaining的 Semaphore来决定是否允许把putlist中的event转移到MemoryChannel的linkedBlockingDeque来, 如果允许 ,则操作 , 操作以后,putlist 和takelist 都被清理掉了。 bytesRemaining信号量(标示还有多少flume event body存储空间)和queueStored(标示有多少个event能被消费)信号量都被释放了 。
综上所述, Flume 的memorychannel采用了两个双端队列putlist和takelist ,分别表示source 的生产能力 和sink 的消费能力,source 和sink启动一个事务 ,source 写putlist ,提交事务以后 ,把putlist批量移动到另一个deque .
而sink 则负责从MemoryChannel的Deque 取event, 写入takelist(只做流控用) , 最后sink的事务提交以后,也把putlist 的event批量移动到deque 。 等于在一个事务里面用putlist 做了写入缓冲,用takelist做了流控, memorychannel中的 deque是多个事务共享的存储。
至此, 我们对memorychannel 的细节已经弄清楚了,回过头来看之前出现的那个异常 , 就能知道为什么了?
首先, 我们的transactionCapacity参数没有配置,那默认就是100 ,也就是putlist和takelist 的长度只有100 ,即写入缓冲容量只有100个event .而MemoryChannel的Deque我们配置了10000 ,允许 flume event body的最大字节数我们配置了
536870912 * (1 - 20 * 0.01) = 400M左右 , 问题并不是出在了memorychannel的双端队列容量不够用,而是下游的hbase sink因为有一个批量处理的默认值是100 ,而在这默认的100次处理中 ,每一次处理都涉及到了对象的avro反序列化 , 100次批量写
入hbase 以后才会清理MemoryTransaction的 putlist,而这个时候上游kafka source 再有数据写入putlist 就出现了前文描述的那个异常。
解决办法:从异常提示的几个思路,我们一一做个思考:
, consider committing more frequently, increasing capacity or increasing thread count
1)更频繁的提交事务: 如果采用这种思路的话,比如只降低hbase sink 的批处理数量,而上游的kafka source的生产能力保持不变,可以预见的是会造成MemoryChannel中Deque堆积的event数量会越来越多(因为更频繁的把event 从 putlist转移到了 Memory Deque) . 这种方法只是把问题从putlist 转移到了另一个Deque 。(要MemoryChannel的Deque更大了)。
2) 增加transactionCapacity: 即增加每一个事务的写缓冲能力(putlist长度增加) ,但是调节到多少呢?如果上游的压力陡增 ,还是会出现这个问题 。这种方法只能暂时缓解,不能彻底解决问题。
3) 增加线程数量: 这里我想flume作者的思路是把sink改为多线程增加消费能力来解决。 这个我认为才是解决问题的根本,增加下游的处理能力 。
那如何增加下游的处理能力呢,除了做flume本身的scaleout ,减少单台flume的压力外。 还有几种方法供我们思考:
A:把hbase sink扩展为多线程 , 每一个线程一个event队列。ChannelProcessor在投递的时候轮询投递到多个队列 。------考虑用Akka ?
B: 使用Disruptor , ChannelProcessor作为生产者,SinkProcessor作为消费者 。
C: 直接换成 storm ,利用storm集群的实时处理能力?
用了两天的时间,采用了storm ,的确极大提高了吞吐能力(20多万条消息大概在两分多钟处理完,QPS 达到了1600。 后面单独再写文章来说明storm目前在使用过程中踩到的坑 。