当我们在使用spark1.6的时候,当我们创建SQLContext读取一个文件之后,返回DataFrame类型的变量可以直接.map操作,不会报错。但是升级之后会包一个错误,如下:
报错:No implicits found for parameter evidence$6: Encoder[Unit]

主要的错误原因为:
******error: Unable to find encoder for type stored in a Dataset. Primitive types (Int, String, etc) and Product types (case classes) are supported by importing spark.implicits._ Support for serializing other types will be added in future releases. resDf_upd.map(row => {******
此时有三种解决方案:
第一种:

然后大家发现不会在报错误了。
第二种:

这样也可以
第三种:
这种是最麻烦的一种,可以参考官网

官网上给的是让自定义一个 Encoders,然后下面是我根据官网的例子,写的样例:
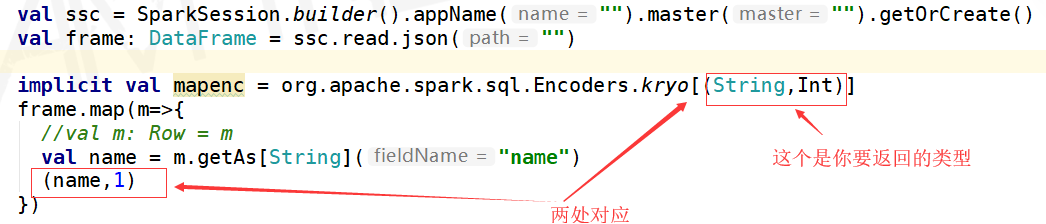
可以看到,也是可以用的,但是相比较上面两个是非常的麻烦的,所以推荐第一种和第二种,强推第二种,简单。
说明:
以上代码中我用的是SparkSession创建的,当然也可以用SQLContext来创建,但是SQLContext已经过时,不再推荐。
若是在用SQLContext时,遇到以上错误,同理解决。