小米
乱谈Python并发
说实话,我一直觉得PHP真的是最好的语言,不仅养活了一大批PHP程序员,同时还为安全人员提供了大量的就业机会。然而,令人唏嘘的是,安全界很多人其实是吃着Python的饭,操着PHP的心。此外,大量的安全研究工具也都是使用Python开发,比如我始终不习惯的mitmproxy,又或者一个循环语句400行的sqlmap、一抓一大把的爬虫框架以及subprocess满天飞的命令行应用包装库。
干活要吃饭,吃饭要带碗。既然这样,要进入互联网安全领域,无论是小白还是高手,多少是要了解点Python的。虽然笔者只是个安全太白,连小白都够不上,但我Python比你专业啊。我看过一些安全人员写的代码,不可否认,功能是有的,代码是渣的,这我非常理解,毕竟术业有专攻,要我去挖洞我也麻瓜,挖个坑倒可以。
其实,Python可以谈的话题很多,比如Python2还是Python3,比如WSGI,比如编码,比如扩展,比如JIT,比如框架和常用库等等,而我们今天要说的则是异步/并发问题,代码运行快一点,就能有更多时间找女朋友了。
进程
众所周知,CPython存在GIL(全局解释锁)问题,用来保护全局的解释器和环境状态变量,社区有过几次去GIL的尝试,都以失败告终,因为发现即使去了GIL,性能好像提高也不是那么明显嘛,还搞那么复杂。注意,这里说的是CPython,Python语言本身是没说要必须有GIL的,例如基于JVM的Jython。而GIL的结果就是Python多线程无法利用多CPU,你128核又如何,我就逮着一只羊薅羊毛了。所以,如果功能是CPU密集型的,这时候Python的进程就派上用场了,除此之外,利用C扩展也是可以绕过GIL的,这是后话。
进程模型算是一种比较古老的并发模型。Python中的进程基本是对系统原生进程的包装,比如Linux上的fork。在Python标准库中,主要是multiprocessing包,多么直白的名字。其中常用的也就是pool,queue模块以及synchronize模块中的一些同步原语(Lock、Condition、Semaphore、Event等)。如果需要更高级的功能,可以考虑下managers模块,该模块用来管理同步进程,大致的实现原理是在内部起了一个server,进程都与这个server交互,进行变量共享...目瞪狗呆有没有,这个模块笔者也只用过两三次,如需对进程进行高级管理,请移步此处。
另外,multiprocessing中有个dummpy子模块,重新实现了一遍多进程模块中的API,然而,它是多线程的,就这么乱入,目的是方便你的代码在多线程和多进程之间无障碍切换,很贴心有没有,而且异常低调,低调到官方文档就一句话,17个单词。
如果你的代码需要大量的CPU运算,多进程是一个比较好的选择。对于安全领域的来说,这种场景貌似不是很多,什么?需要大量加密解密?都到自己要实现这么高深算法的程度了,别挣扎了,用C吧,写个扩展更好。
所以,如非必须,我是不太推荐用多进程的,容易出错,不好控制,而且,有更省心的选择,谁会和自己过不去呢。
线程
与进程一样,Python中的线程也是对系统原生线程的包装。其实现在的Linux上,线程和进程的差别不是很大,以此推知,Linux平台下,Python中的线程和进程开销差别也不会太大,但终归进程是要开销大点的,创建也会慢一点。相比于进程,我是更倾向使用线程的,尤其是IO密集型程序,能用线程解决的问题,尽量不用进程。
另外,如果要在进程之间共享数据,确实比较头疼一点,要用到Queue、Pipe、SyncManager或者类似redis这种外部依赖,而线程之间共享数据就方便很多,毕竟大家都是一个爹生的,家里东西一起用吧。有人可能会觉得,线程能共享数据,但是也会在修改数据时互相影响,导致各种难以排查的BUG,这个问题提的好,之所以有这种问题,还不是因为代码写的烂,多练练就好了。如果既想要方便的共享数据,还要能随意的隔离数据,threading.local()可以帮你,创建的变量属于线程隔离的,线程之间互不影响,上帝的归上帝,恺撒的归恺撒。说到ThreadLocal变,我们熟知的Flask中每个请求上下文都是ThreadLocal的,以便请求隔离,这个是题外话。
Python中的线程主要是在threading模块里,这个模块是对更底层的\_thread的封装,提供了更友好的接口。该模块中用到比较多的也是Queue、Pool、Lock、Event等,这些就不展开了,有机会再一一细说。Python 3.2后还引入了一个比较有意思的新类,叫Barrier,顾名思义,就是设置个障碍(设置数目n),等大家都到齐了(每个线程调用下wait,直到有n个线程调用),再一起出发。Python 3.3也在进程中引入了对应的此模块。此外,还有Timer可以用来处理各种超时情况,比如终结subprocess创建的进程。
创建多线程有两种方式:一种是继承threading.Thread类,然后实现run方法,在其中实现功能逻辑;另一种就是直接threading.Thread(target=xxx)的方式来实现,与进程模块大同小异。具体使用可以参考官方文档,这里就不赘述了。
协程
前面我们提到了,Python的线程(包括进程)其实都是对系统原生内核级线程的包装,切换时,需要在内核与用户态空间来来回回,开销明显会大很多,而且多个线程完全由系统来调度,什么时候执行哪个线程是无法预知的。相比而言,协程就轻量级很多,是对线程的一种模拟,原理与内核级线程类似,只不过切换时,上下文环境保存在用户态的堆栈里,协程“挂起”的时候入栈,“唤醒”的时候出栈,所以其调度是可以人为控制的,这也是“协程”名字的来由,大伙协作着来,别总抢来抢去的,伤感情。
实际上,协程本身并不是真正的并发,任何时候只有一个协程在执行,只是当需要耗时操作时,比如I/O,我们就让它挂起,执行别的协程,而不是一直干等着什么也做不了,I/O完毕了我们再切换来继续执行,这样可以大大提高效率,而且不用再费心费力去考虑同步问题,简单高效。与传统线程、进程模型相比,协程配上事件循环(告诉协程什么时候挂起,什么时候唤醒),简直完美。Python里的协程也是后来才逐渐加入的,基本分三个阶段,过程比较坎坷,与”携程“差不多,时不时被骂几句。
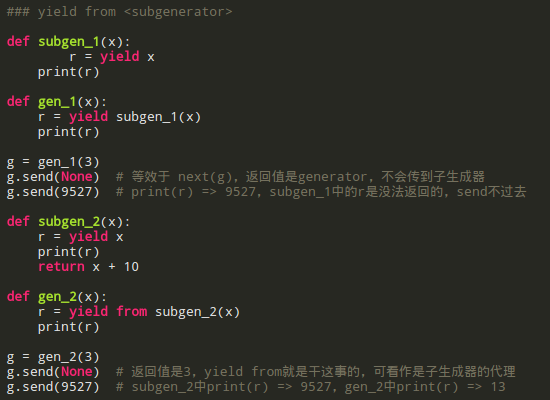
yield/send
这算是第一个阶段,其实yield主要是用来做生成器的,不要告我不知道什么叫生成器,这多尴尬。Python 2.5时,yield变成了表达式(之前只是个语句),这样就有了值,同时PEP 342引入了send,yield可以暂停函数执行,send通知函数继续往下执行,并提供给yield值。仔细一看,好巧啊,这么像协程,于是屁颠屁颠的把生成器用来实现协程,虽然是半吊子工程,不过还不错的样子,总比没有的好,自此我们也可以号称是一门有协程的现代高级编程语言了。
可以这么说,对于不考虑yield返回值情形,我们就把它当作普通的生成器,对于考虑yield返回值的,我们就可以把它看作是协程了。

但是,生成器干协程的活,总归不是那么专业。虽然生成器这货能模拟协程,但是模拟终归是模拟,不能return,不能跨堆栈,局限性很大。说到这里,连不起眼的Lua都不屑于和我们多说话,Go则在Goroutine(说白了还不是类协程)的道上一路狂奔,头都不回,而Erlang轻轻抚摸了下Python的头,说句:孙子诶。
既然Python 2.x中的yield不争气,索性我们来改造下咯,于是Python 3.3(别老抱着Python 2不放了)中生成器函数华丽丽的可以return了,顺带来了个yield from,解决了旧yield的短板。
asyncio/yield from
这算第二阶段,Python 3.3引入yield from(PEP 380),Python3.4引入asyncio。其实本质上来说,asyncio是一个事件循环,干的活和libev差不多,用来调度协程,同时使用@asyncio.coroutine来把函数打扮成协程,搭配上yield from实现基于协程的异步并发。
与yield相比,yield from进化程度明显高了很多,不仅可以用于重构简化生成器,进而把生成器分割成子生成器,还可以像一个双向管道一样,将send的信息传递给内层协程,获取内层协程yield的值,并且处理好了各种异常情况,`return (yield from xxx)`也是溜溜的。
接下来看一个yield from Future的例子,其实就是asyncio.sleep(1):

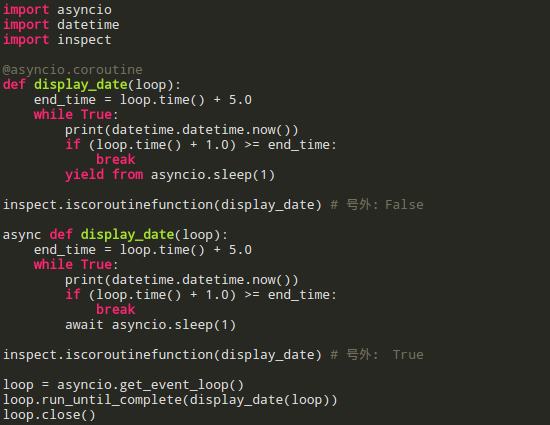
async/await
这是第三个阶段。Python 3.5引入了async/await,没错,我们就是抄C#的,而且还抄出了具有Python特色的`async with`和`async for`。某种程度上看,async/await是asyncio/yield from的升级版,这下好了,从语言层面得到了的支持,我们是名正言顺的协程了,再也不用寄人篱下,委身于生成器了(提裤子不认人啊,其实还不是asyncio帮衬着)。也是从这一版本开始,生成器与协程的界限要逐渐开始划清。
对比下async/await和asyncio/yield from,如此相似,不过还是有一些区别的,比如await和yield from接受的类型,又比如函数所属类型等,所以二者是不能混用的:
不过话说回来,最近几个版本的Python引入的东西真不少,概念一个一个的,感觉已经不是原来那个单纯的Python了。悲剧的是用的人却不多,周边生态一片贫瘠,社区那帮人都是老司机,您车开这么快,我等赶不上啊,连Python界的大神爱民(Armin Ronacher,我是这么叫的,听着接地气)都一脸蒙逼,狂吐槽( http://lucumr.pocoo.org/2016/10/30/i-dont-understand-asyncio ),眼看着就要跑去搞rust了。不过,吐槽归吐槽,这个毕竟是趋势,总归是要了解的,技多不压身,乱世出英雄,祝你好运。
题外话,搞安全么,难免写个爬虫、发个http请求什么的,还在用requests吗,去试试aiohttp,谁用谁知道。
greenlet/gevent与tornado
除了官方的协程实现外,还有一些基于协程的框架或网络库,其中比较有名的有gevent和tornado,我个人强烈建议好好学学这两个库。
gevent是一个基于协程的异步网络库,基于libev与greenlet。鉴于Python 2中的协程比较残疾,greenlet基本可以看作是Python 2事实上的协程实现了。与官方的各种实现不同,greenlet底层是C实现的,尽管stackless python基本上算失败了,但是副产品greenlet却发扬光大,配合libev也算活的有声有色,API也与标准库中的线程很类似,分分钟上手。同时猴子补丁也能很大程度上解决大部分Python库不支持异步的问题,这时候nodejs的同学一定在偷笑了:Python这个渣渣。
tornado则是一个比较有名的基于协程的网络框架,主要包含两部分:异步网络库以及web框架。东西是好东西,相比twisted也挺轻量级,但是配套不完善啊,到现在我都没找到一个好用的MySQL驱动,之前用的Redis驱动还坑的我不要不要的。我觉得用作异步网络库还是相当不错的,但是作为web框架吧...就得看人了,我见过很多人直接用普通的MySQLdb,还告我说tornado性能高,你在逗我吗,用普通的MySQL驱动配合异步框架,这尼玛当单线程在用啊,稍有差错IOLoop Block到死,我要是tornado我都火大。随着Python的发展,tornado现在也已经支持asyncio以及async/await,不过我很久没用了,具体如何请参考文档。
对比gevent与tornado,本质上是相同的,只是二者走了不同的道路,gevent通过给标准库的socket、thread、ssl、os等打patch,采用隐式的方式,无缝的把现有的各种库转换为支持异步,避免了为支持异步而重写,解决了库的问题,性能也是嗖嗖的,随随随便跑万儿八千个patch后的线程玩一样,然而,我对这种隐藏细节、不可掌控的黑魔法总是有一丝顾虑;另一方的tornado则采用显示的方式,把调度交给用户来完成,清晰明了,结果就是自成一套体系,没法很好的利用现有的很多库,还得显示的调用IOLoop,单独使用异常别扭,你可以试试nsq的官方Python库,都是泪。
本文只是对Python中并发编程的一个全局性的介绍,帮助不了解这方面的同学有一个概念,方便去针对学习,若要展开细节,恐怕三天三夜也讲不完,而我的碗还没洗,所以这次就到此为止。其实,作为一门通用胶水语言,我觉得,无论工作是哪个方向,好好学习一下Python是有必要的。知道requests那哥们吗,写完requests后就从路人大胖子变成了文艺摄影小帅哥,而且还抱得美人归,你还等什么。退一步讲,万一安全搞不好,还可以考虑进军目前火热的机器学习领域。
所以,人生苦短,我用Python。
360
我们目前有Python代码约6万行,程序运行在Linux下。
这6万行Python代码被被分成80余个项目进行组织。每个项目提供一个或一组完整的功能集合,每个项目都有自己的 setup.py 文件用来将项目代码打包成 Python 发布包(Distribution),部分项目还有自动文档生成,我们使用的是 Sphinx 和 reST格式的文本。打包好的Python包被发布到我们自己搭建的内网的与 pypi.python.org 兼容的私有 pypi 服务器上,而文档保存在内网的类似于 readthedocs 的服务器上。
后台团队的代码主要运行我们自己的Linux服务器集群上,开发和部署的成本比较低,因此我们使用比较敏捷的开发流程。流程大体上可以分为下面几个步骤:
- 开发:顾名思义,这个步骤当中,开发人员在开发机上面写代码实现功能,不同的开发人员的开发环境使用 扩展过的 virtualenv 脚本进行隔离;
- 单元测试:开发人员负责对代码当中的关键部分进行单元测试,通常使用 unittest,我们使用 nose 将测试用例聚合和进行回归测试,不定期使用 coverage 确定代码测试覆盖率(集成在nose当中)。这一步还会使用 PyLint 对代码进行扫描;
- 构建:使用 python distribute 将 Python代码构建成包,同时将这个包发布到测试版 pypi 服务器(pypi-testing),测试版pypi服务器是我们搭建的若干个私有pypi其中之一,发布工作使用的是我们扩展的 distribute 命令;
- 测试:在测试机器或测试流程当中,从测试版pypi当中获取最新的库并测试,这个部署过程我们使用 distribute 提供的 easy_install 工具进行;
- 发布:将经过测试的包从测试版pypi服务器移到发布版pypi服务器,这个同样通过扩展的 distribute 命令;
- 部署:运维人员从发布版pypi服务器上获取最新的库,并更新到真实的服务器上,并应用新的变更。这个过程当中任何一台单机部署使用的都是 easy_install,在分布式环境下,我们使用 Fabric进行多机部署;
- 监控:新版本上线之后,会持续通过日志和报警系统进行系统监控。我们专门扩展了 logging 模块以便适应我们的监控需求。
熟悉Python的朋友们可能看到这些名词和包都很熟悉,因为我们所使用的都是业界广泛使用的开发、测试和运维的工具。但这些工具很多都适合于开源软件(Open Source Software)而非私有软件(Proprietary Software),例如 distribute 与 pypi.python.org 的结合是天衣无缝的,Sphinx 和 readthedocs 也是很容易结合,但是作为一个私有软件,我们无法将代码和文档放到 pypi 或 readthedocs 上面。为此我们几乎复制了整套的基础架构,包括 pypi 服务,readthedocs 服务等,后续我会介绍我们如何做到这点的。希望这个系列对于其他正在使用Python开发私有软件的同仁能有些帮助。