一、概要描述
在上一篇博文中主要描述了JobTracker和其几个服务(或功能)模块的接收到提交的job后的一些处理。其中很重要的一部分就作业的初始化。因为代码片段图的表达问题,本应该在上篇描述的内容,分开在本篇描述。
二、 流程描述
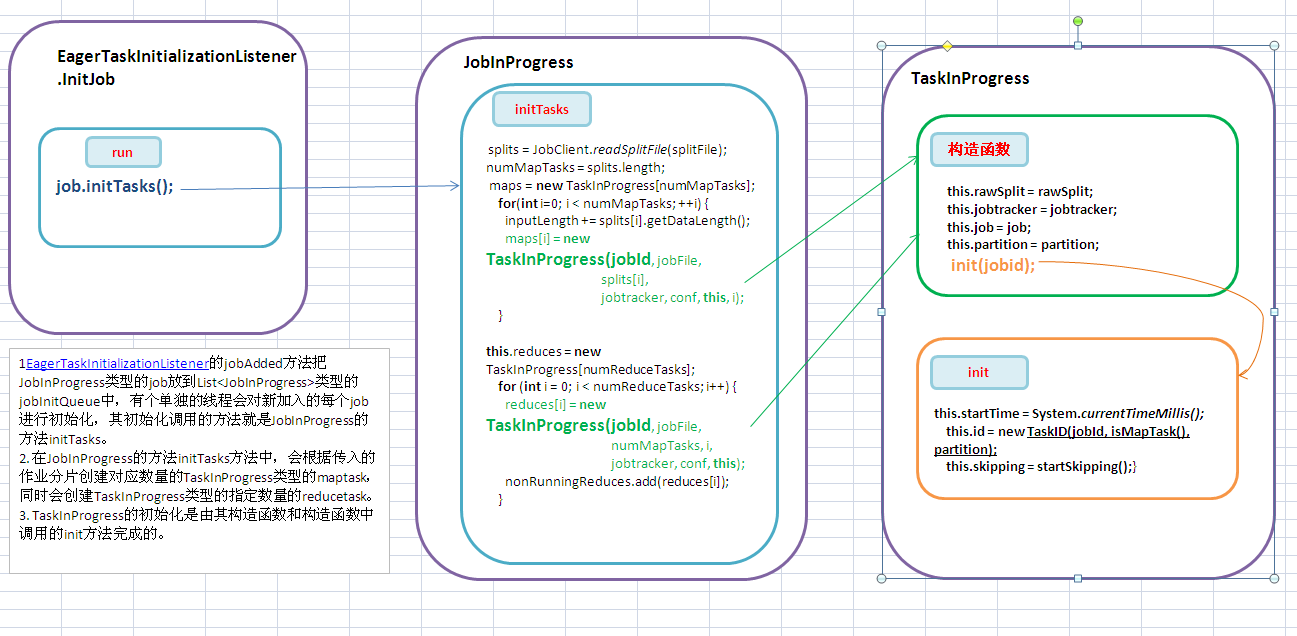
1. 代码也接上文的最后一个方法 EagerTaskInitializationListener的jobAdded方法把JobInProgress类型的job放到List<JobInProgress>类型的 jobInitQueue中,有个单独的线程会对新加入的每个job进行初始化,其初始化调用的方法就是JobInProgress的方法initTasks。
2. 在JobInProgress的方法initTasks方法中,会根据传入的作业分片创建对应数量的TaskInProgress类型的maptask,同时会创建TaskInProgress类型的指定数量的reducetask。
3. TaskInProgress的初始化是由其构造函数和构造函数中调用的init方法完成的。
三、代码详细
1. EagerTaskInitializationListener的内部InitJob线程的run方法。调用JobInProgress的初始化方法。
static class InitJob implements Runnable { private JobInProgress job; public InitJob(JobInProgress job) { this.job = job; } public void run() { job.initTasks(); } }
2. JobInProgress 类的initTasks方法。
主要流程:
1)根据读入的split确定map的数量,每个split一个map
2)如果Task数大于该jobTracker支持的最大task数,则抛出异常。
3)根据split的数量初始化maps
4)如果没有split,表示job已经成功结束。
5) 根据指定的reduce数量numReduceTasks创建reduce task
6)计算并且最少剩下多少map task ,才可以开始Reduce task。默认是总的map task的5%,即大部分Map task完成后,就可以开始reduce task了。
//1) 根据读入的split确定map的数量,每个split一个map String jobFile = profile.getJobFile(); Path sysDir = new Path(this.jobtracker.getSystemDir()); FileSystem fs = sysDir.getFileSystem(conf); DataInputStream splitFile = fs.open(new Path(conf.get("mapred.job.split.file"))); JobClient.RawSplit[] splits; splits = JobClient.readSplitFile(splitFile); numMapTasks = splits.length; //2)如果Task数大于该jobTracker支持的最大task数,则抛出异常。 int maxTasks = jobtracker.getMaxTasksPerJob(); if (maxTasks > 0 && numMapTasks + numReduceTasks > maxTasks) { throw new IOException( "The number of tasks for this job " + (numMapTasks + numReduceTasks) + " exceeds the configured limit " + maxTasks); } //3)根据split的数量初始化maps maps = new TaskInProgress[numMapTasks]; for(int i=0; i < numMapTasks; ++i) { inputLength += splits[i].getDataLength(); maps[i] = new TaskInProgress(jobId, jobFile, splits[i], jobtracker, conf, this, i); } LOG.info("Input size for job "+ jobId + " = " + inputLength); if (numMapTasks > 0) { LOG.info("Split info for job:" + jobId + " with " + splits.length + " splits:"); nonRunningMapCache = createCache(splits, maxLevel); } this.launchTime = System.currentTimeMillis(); //4)如果没有split,表示job已经成功结束。 if (numMapTasks == 0) { //设定作业的完成时间避免下次还会判断。 this.finishTime = this.launchTime; status.setSetupProgress(1.0f); status.setMapProgress(1.0f); status.setReduceProgress(1.0f); status.setCleanupProgress(1.0f); status.setRunState(JobStatus.SUCCEEDED); tasksInited.set(true); JobHistory.JobInfo.logInited(profile.getJobID(), this.launchTime, 0, 0); JobHistory.JobInfo.logFinished(profile.getJobID(), this.finishTime, 0, 0, 0, 0, getCounters()); return; } //5) 根据指定的reduce数量numReduceTasks创建reduce task this.reduces = new TaskInProgress[numReduceTasks]; for (int i = 0; i < numReduceTasks; i++) { reduces[i] = new TaskInProgress(jobId, jobFile, numMapTasks, i, jobtracker, conf, this); nonRunningReduces.add(reduces[i]); } // 6)计算最少剩下多少map task ,才可以开始Reduce task。默认是总的map task的5%,即大部分Map task完成后,就可以开始reduce task了。 completedMapsForReduceSlowstart = (int)Math.ceil( (conf.getFloat("mapred.reduce.slowstart.completed.maps", DEFAULT_COMPLETED_MAPS_PERCENT_FOR_REDUCE_SLOWSTART) * numMapTasks)); tasksInited.set(true); }
3. TaskInProgress的构造函数
有构造MapTask的构造函数和构造ReduceTask的构造函数。分别是如下。其主要区别在于构造mapTask是要传入输入分片信息的RawSplit,而Reduce Task则不需要。两个构造函数都要调用init方法,进行其他的初始化。
public TaskInProgress(JobID jobid, String jobFile, RawSplit rawSplit, JobTracker jobtracker, JobConf conf, JobInProgress job, int partition) { this.jobFile = jobFile; this.rawSplit = rawSplit; this.jobtracker = jobtracker; this.job = job; this.conf = conf; this.partition = partition; this.maxSkipRecords = SkipBadRecords.getMapperMaxSkipRecords(conf); setMaxTaskAttempts(); init(jobid); }
public TaskInProgress(JobID jobid, String jobFile, int numMaps, int partition, JobTracker jobtracker, JobConf conf, JobInProgress job) { this.jobFile = jobFile; this.numMaps = numMaps; this.partition = partition; this.jobtracker = jobtracker; this.job = job; this.conf = conf; this.maxSkipRecords = SkipBadRecords.getReducerMaxSkipGroups(conf); setMaxTaskAttempts(); init(jobid); }
4. TaskInProgress的init方法。初始化写map和reduce类型task都需要的初始化信息。
void init(JobID jobId) { this.startTime = System.currentTimeMillis(); this.id = new TaskID(jobId, isMapTask(), partition); this.skipping = startSkipping(); }
完。
为了转载内容的一致性、可追溯性和保证及时更新纠错,转载时请注明来自:http://www.cnblogs.com/douba/p/hadoop_mapreduce_job_init.html。谢谢!