从这一节我们开始学习Linux得日常运维命令。
一、W
w命令常用来查看系统负载,查看当前有哪些用户登录到系统中,以及他们在系统中的一些行为。
[root@ruanwenwu02 ~]# w 20:56:32 up 2 days, 13:12, 2 users, load average: 0.01, 0.02, 0.05 USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT root tty1 3110月17 12days 0.24s 0.24s -bash root pts/0 192.168.38.1 1811月17 0.00s 0.65s 0.00s w
第一行的20:56:32 up 2 days, 13:12,"表示当前时间20:56:32,系统开机到目前为止经过了2天,13小时,12分钟。“load average: 0.01, 0.02, 0.05”表示最近1分钟,5分钟,15分钟的负载。一般来说,这个数字越低,则说明系统的压力越小。下一小节我会单独来记录一下loadaverage这个东西。


备注:
1) 区别于who命令,w命令不仅可以看到登录服务器的用户信息,而且可以看到这些用户做了什么
2) who am i命令,显示出自己在系统中的用户名,登录终端,登录时间
3) whoami命令,显示自己在系统中的用户名
4) logname命令,可以显示自己初次登录到系统中的用户名,主要识别sudo前后情形
5) last命令,查看最近1个月用户登录服务器的情况
6) tty命令,来查看所连接的设备或终端
二、loadaverage
2.1. 什么是load average?
linux系统中的Load对当前CPU工作量的度量 (WikiPedia: the system load is a measure of the amount of work that a computer system is doing)。也有简单的说是进程队列的长度。
Load Average 就是一段时间 (1 分钟、5分钟、15分钟) 内平均 Load 。
我们可以通过系统命令"w"查看当前load average情况
20:01:55 up 76 days, 8:20, 6 users, load average: 1.30, 1.48, 1.69
上面内容显示系统负载为“1.30, 1.48, 1.69”,这3个值是什么意思呢?
- 第一位1.30:表示最近1分钟平均负载
- 第二位1.48:表示最近5分钟平均负载
- 第三位1.69:表示最近15分钟平均负载
PS. linux系统是5秒钟进行一次Load采样
2.2. load average值的含义
2.2.1 单核处理器
假设我们的系统是单CPU单内核的,把它比喻成是一条单向马路,把CPU任务比作汽车。当车不多的时候,load <1;当车占满整个马路的时候 load=1;当马路都站满了,而且马路外还堆满了汽车的时候,load>1
 Load < 1
Load < 1
 Load = 1
Load = 1 Load >1
Load >1
2.2.2 多核处理器
我们经常会发现服务器Load > 1但是运行仍然不错,那是因为服务器是多核处理器(Multi-core)。
假设我们服务器CPU是2核,那么将意味我们拥有2条马路,我们的Load = 2时,所有马路都跑满车辆。
 Load = 2时马路都跑满了
Load = 2时马路都跑满了
grep 'model name' /proc/cpuinfo | wc -l
2.3. 什么样的Load average值要提高警惕
- 0.7 < load < 1: 此时是不错的状态,如果进来更多的汽车,你的马路仍然可以应付。
- load = 1: 你的马路即将拥堵,而且没有更多的资源额外的任务,赶紧看看发生了什么吧。
- load > 5: 非常严重拥堵,我们的马路非常繁忙,每辆车都无法很快的运行
2.4. 三种Load值,应该看哪个?
通常我们先看15分钟load,如果load很高,再看1分钟和5分钟负载,查看是否有下降趋势。
1分钟负载值 > 1,那么我们不用担心,但是如果15分钟负载都超过1,我们要赶紧看看发生了什么事情。所以我们要根据实际情况查看这三个值。
2.5. 通过Nagios配置Load监控告警
见文:http://heipark.iteye.com/blog/1340190
三、vmstat
vmstat命令是最常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。这个命令是我查看Linux/Unix最喜爱的命令,一个是Linux/Unix都支持,二是相比top,我可以看到整个机器的CPU,内存,IO的使用情况,而不是单单看到各个进程的CPU使用率和内存使用率(使用场景不一样)。
一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,如:
root@ubuntu:~# vmstat 2 1
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 0 3498472 315836 3819540 0 0 0 1 2 0 0 0 100 0
2表示每个两秒采集一次服务器状态,1表示只采集一次。
实际上,在应用过程中,我们会在一段时间内一直监控,不想监控直接结束vmstat就行了,例如:

root@ubuntu:~# vmstat 2
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 0 3499840 315836 3819660 0 0 0 1 2 0 0 0 100 0
0 0 0 3499584 315836 3819660 0 0 0 0 88 158 0 0 100 0
0 0 0 3499708 315836 3819660 0 0 0 2 86 162 0 0 100 0
0 0 0 3499708 315836 3819660 0 0 0 10 81 151 0 0 100 0
1 0 0 3499732 315836 3819660 0 0 0 2 83 154 0 0 100 0
这表示vmstat每2秒采集数据,一直采集,直到我结束程序,这里采集了5次数据我就结束了程序。
好了,命令介绍完毕,现在开始实战讲解每个参数的意思。
r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的。
swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
free 空闲的物理内存的大小,我的机器内存总共8G,剩余3415M。
buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用300多M
cache cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒
bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
in 每秒CPU的中断次数,包括时间中断
cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
id 空闲 CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
wt 等待IO CPU时间。
四、top命令
man的解释是:The top program provides a dynamic real-time view of a running system. It can display system summary infor-
mation as well as a list of tasks currently being managed by the Linux kernel.
翻译成中文是:top程序提供系统的实时状态视图。他除了能提供系统的大概信息,还能当前运行的程序所占用的cpu和内存的情况。
我们先看top执行的情况:
top - 18:19:46 up 16 days, 9:04, 23 users, load average: 1.27, 1.21, 1.19 Tasks: 568 total, 2 running, 563 sleeping, 1 stopped, 2 zombie Cpu(s): 16.7%us, 1.3%sy, 0.0%ni, 81.7%id, 0.2%wa, 0.0%hi, 0.1%si, 0.0%st Mem: 8060540k total, 7641428k used, 419112k free, 61780k buffers Swap: 16777196k total, 2025104k used, 14752092k free, 281040k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 22620 root 20 0 437m 53m 2712 R 99.6 0.7 16511:03 php 21762 ding.lin 20 0 562m 171m 10m S 10.3 2.2 1:56.81 php 21760 ding.lin 20 0 549m 159m 10m S 8.9 2.0 1:45.97 php 20944 ma.dong 20 0 99.8m 2656 1544 S 5.6 0.0 11:42.95 sshd 3521 yang.lei 20 0 7862m 5.3g 1272 S 4.6 69.1 24:47.76 python 20942 root 20 0 97.7m 3916 2960 S 1.7 0.0 3:24.42 sshd 2236 root 20 0 411m 25m 3436 S 1.0 0.3 8:10.85 php 21766 ding.lin 20 0 402m 24m 9320 S 1.0 0.3 0:10.26 php
这个信息会每3秒自动更新一次。如果不想要它更新,可以使用top -bn1命令:
[ruan.wenwu@kddi-zol-fss-web1 conf]$ top -bn1|head -n 20 top - 18:21:22 up 16 days, 9:05, 23 users, load average: 1.24, 1.22, 1.19 Tasks: 569 total, 3 running, 563 sleeping, 1 stopped, 2 zombie Cpu(s): 13.6%us, 0.8%sy, 0.0%ni, 85.5%id, 0.1%wa, 0.0%hi, 0.1%si, 0.0%st Mem: 8060540k total, 7678448k used, 382092k free, 67088k buffers Swap: 16777196k total, 2025032k used, 14752164k free, 284908k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 22620 root 20 0 437m 53m 2712 R 98.0 0.7 16512:22 php 21760 ding.lin 20 0 560m 169m 10m S 9.6 2.2 1:54.30 php 21762 ding.lin 20 0 574m 184m 10m S 9.6 2.3 2:06.40 php 20944 ma.dong 20 0 99.8m 2656 1544 S 5.8 0.0 11:48.62 sshd 1818 postfix 20 0 83764 2992 540 S 1.9 0.0 7:58.57 qmgr 2236 root 20 0 411m 25m 3436 S 1.9 0.3 8:11.95 php 20942 root 20 0 97.7m 3916 2960 S 1.9 0.0 3:26.06 sshd 21719 ding.lin 20 0 427m 39m 10m S 1.9 0.5 0:21.16 php 21729 ding.lin 20 0 398m 22m 10m S 1.9 0.3 0:11.33 php 31512 postfix 20 0 81124 3576 2652 S 1.9 0.0 0:00.04 cleanup 31530 ruan.wen 20 0 15292 1480 824 R 1.9 0.0 0:00.02 top 1 root 20 0 19352 540 312 S 0.0 0.0 0:59.90 init 2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
这个命令适合在写脚本的时候使用。

最后一个%st可能是系统被偷走的资源,比如你的系统安装了虚拟机,可能出现这样的情况。
[ruan.wenwu@kddi-zol-fss-web1 conf]$ top top - 18:23:46 up 16 days, 9:08, 23 users, load average: 1.15, 1.17, 1.17 Tasks: 582 total, 2 running, 577 sleeping, 1 stopped, 2 zombie Cpu0 : 11.9%us, 1.7%sy, 0.0%ni, 85.8%id, 0.3%wa, 0.0%hi, 0.3%si, 0.0%st Cpu1 : 7.0%us, 2.3%sy, 0.0%ni, 90.6%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu2 : 4.3%us, 1.0%sy, 0.0%ni, 94.6%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu3 : 3.3%us, 0.7%sy, 0.0%ni, 96.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu4 : 4.7%us, 1.0%sy, 0.0%ni, 94.4%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu5 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu6 : 10.6%us, 0.7%sy, 0.0%ni, 88.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu7 : 88.1%us, 0.7%sy, 0.0%ni, 10.9%id, 0.0%wa, 0.0%hi, 0.3%si, 0.0%st Mem: 8060540k total, 7743128k used, 317412k free, 81616k buffers Swap: 16777196k total, 2025028k used, 14752168k free, 299068k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 22620 root 20 0 437m 53m 2712 S 89.0 0.7 16514:20 php 21762 ding.lin 20 0 592m 202m 10m S 12.2 2.6 2:20.42 php 21760 ding.lin 20 0 577m 186m 10m S 10.3 2.4 2:07.51 php 21766 ding.lin 20 0 410m 32m 9320 S 7.9 0.4 0:12.77 php 20944 ma.dong 20 0 99.8m 2656 1544 S 6.3 0.0 11:57.39 sshd 3521 yang.lei 20 0 7862m 5.3g 1272 R 3.3 69.1 24:58.46 python 20942 root 20 0 97.7m 3916 2960 S 1.7 0.0 3:28.58 sshd
五、sar
sar命令被称为linux中的瑞士军刀,意思是它可以干很多事情,但是通常我们用它来查看系统的网卡流量:
sar -n DEV 1 10
这条命令的意思就是每秒显示一次,显示10次:
[ruan.wenwu@kddi-zol-fss-web1 conf]$ sar -n DEV 1 3 Linux 2.6.32-642.11.1.el6.x86_64 (kddi-zol-fss-web1.zoldc.com.cn) 12/20/2017 _x86_64_ (8 CPU) 06:27:16 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s 06:27:17 PM lo 88.00 88.00 36.67 36.67 0.00 0.00 0.00 06:27:17 PM eth0 157.00 161.00 117.72 40.31 0.00 0.00 1.00 06:27:17 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s 06:27:18 PM lo 300.00 300.00 69.97 69.97 0.00 0.00 0.00 06:27:18 PM eth0 1206.12 1130.61 1011.27 183.38 0.00 0.00 1.02 06:27:18 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s 06:27:19 PM lo 121.21 121.21 32.16 32.16 0.00 0.00 0.00 06:27:19 PM eth0 304.04 316.16 143.03 68.02 0.00 0.00 1.01 Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s Average: lo 169.02 169.02 46.16 46.16 0.00 0.00 0.00 Average: eth0 552.19 532.66 421.00 96.75 0.00 0.00 1.01
说明:
IFACE:有lo和eth0两张网卡
rxpck/s:每秒收到的包
txpck/s:每秒发出去的包
rxkb/s:每秒收到的数据量
txkb/s:每秒发出去的数据量。比如你买的带宽是1M,那么就是看这个数据有没有跑满。
其他的几行不用看。
sar命令需要安装后才能使用:
yum -y install sysstat
sar会记录每天的信息放在/var/log/sa目录下:
[root@iZ25lzba47vZ ~]# cd /var/log/sa/ [root@iZ25lzba47vZ sa]# ls sa01 sa05 sa09 sa13 sa17 sa21 sa25 sa29 sar03 sar07 sar11 sar15 sar19 sar23 sar27 sa02 sa06 sa10 sa14 sa18 sa22 sa26 sa30 sar04 sar08 sar12 sar16 sar20 sar24 sar28 sa03 sa07 sa11 sa15 sa19 sa23 sa27 sar01 sar05 sar09 sar13 sar17 sar21 sar25 sar29 sa04 sa08 sa12 sa16 sa20 sa24 sa28 sar02 sar06 sar10 sar14 sar18 sar22 sar26 sar30 [root@iZ25lzba47vZ sa]#
如果想要查看某一天的流量:
[root@iZ25lzba47vZ sa]# sar -n DEV -f /var/log/sa/sa17 Linux 3.10.0-123.9.3.el7.x86_64 (iZ25lzba47vZ) 12/17/2017 _x86_64_ (1 CPU) 12:00:01 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s 12:10:01 AM eth0 0.03 0.04 0.00 0.00 0.00 0.00 0.00 12:10:01 AM eth1 2.66 3.11 0.25 4.97 0.00 0.00 0.00 12:10:01 AM lo 3.02 3.02 0.55 0.55 0.00 0.00 0.00 12:20:01 AM eth0 0.03 0.05 0.00 0.00 0.00 0.00 0.00 12:20:01 AM eth1 0.22 0.20 0.01 0.04 0.00 0.00 0.00
查看磁盘读写:
[root@iZ25lzba47vZ sa]# sar -b Linux 3.10.0-123.9.3.el7.x86_64 (iZ25lzba47vZ) 12/20/2017 _x86_64_ (1 CPU) 12:00:01 AM tps rtps wtps bread/s bwrtn/s 12:10:01 AM 0.69 0.04 0.65 0.56 28.49 12:20:01 AM 0.02 0.00 0.02 0.00 0.25 12:30:01 AM 1.53 1.08 0.45 24.52 13.40
sa17是二进制文件不能直接cat,需要用sar命令查看;sar17是文本,可以直接查看。
六、nload
nload也是用来查看网卡流量的方法。比起sar -n DEV获取网卡流量的方式,nload看起来更加直观。我们先看一下nload的效果:
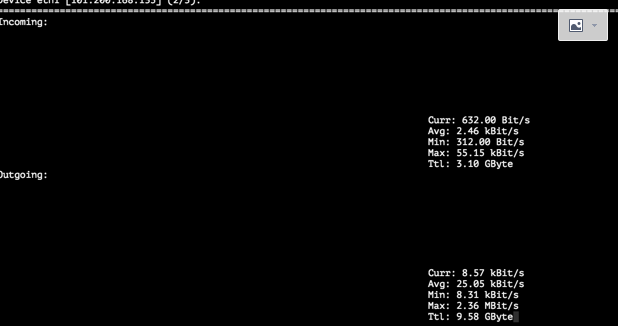
直接nload就行了,不用加任何参数。方向键可以在多张网卡之间切换。
noload的安装需要先安装:
yum -y install epel-release
然后才是安装nload:
yum -y install nload
七、iostat
[root@iZ25lzba47vZ sa]# iostat -x Linux 3.10.0-123.9.3.el7.x86_64 (iZ25lzba47vZ) 12/20/2017 _x86_64_ (1 CPU) avg-cpu: %user %nice %system %iowait %steal %idle 0.21 0.00 0.18 0.10 0.10 99.41 Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util xvda 0.00 0.45 0.09 0.49 1.37 5.25 22.64 0.00 8.52 12.13 7.82 2.16 0.13 xvdb 0.00 0.00 0.00 0.00 0.00 0.00 8.00 0.00 0.75 0.75 0.00 0.75 0.00
最常用的是-x参数,如果%util接近100%,说明产生的I/O请求太多,I/O系统已经满负载,该磁盘可能存在瓶颈。
在安装sar命令的sysstat时,iostat也默认安装上了。
此外我们还可以使用iotop来查看是那些进程占用了多少io:
avg-cpu: %user %nice %system %iowait %steal %idle 0.21 0.00 0.18 0.10 0.10 99.41 Total DISK READ : 0.00 B/s | Total DISK WRITE : 0.00 B/s Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND 1 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % systemd --switched-root --system --deserialize 22 2 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kthreadd] 3 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [ksoftirqd/0] 5 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kworker/0:0H]
iotop命令的安装:
yum -y install iotop