1. 感知机
- 单层感知机:
import torch
from torch.nn import functional as F
x = torch.randn(1,10)
w = torch.randn(1,10,requires_grad=True)
o = torch.sigmoid(x@w.t())
print(o)
# tensor([[0.0056]], grad_fn=<SigmoidBackward>)
loss = F.mse_loss(o, torch.ones(1,1))
print(loss)
# tensor(0.9888, grad_fn=<MeanBackward0>)
loss.backward()
print(w.grad)
# tensor([[ 5.1490e-03, -1.3516e-02, -3.0863e-03, -1.0879e-02, 2.0131e-03,
# 1.8913e-02, -2.1375e-02, -1.7731e-05, -5.4163e-03, 1.9385e-02]])
- 多层感知机:
x = torch.randn(1,10)
w = torch.randn(2,10, requires_grad=True)
o = torch.sigmoid(x@w.t())
print(o)
# tensor([[0.0043, 0.1024]], grad_fn=<SigmoidBackward>)
loss = F.mse_loss(o, torch.ones(1,2))
print(loss)
# tensor(0.8986, grad_fn=<MeanBackward0>)
loss.backward()
print(w.grad)
# tensor([[ 3.2448e-03, -1.8384e-04, 2.6368e-05, -2.9615e-03, -1.7245e-03,
# -3.1285e-03, 1.2093e-03, 2.1269e-03, 1.7680e-03, 8.0052e-03],
# [ 6.2952e-02, -3.5667e-03, 5.1156e-04, -5.7457e-02, -3.3457e-02,
# -6.0696e-02, 2.3462e-02, 4.1264e-02, 3.4302e-02, 1.5531e-01]])
2. 链式法则求梯度
[y1 = w1 * x +b1 \
y2 = w2 * y1 +b2 \
frac{dy_{2}}{^{dw_{1}}}= frac{dy_{2}}{^{dy_{1}}}*frac{dy_{1}}{^{dw_{1}}}= w_{2}* x
]
x = torch.tensor(1.)
w1 = torch.tensor(2., requires_grad=True)
b1 = torch.tensor(1.)
w2 = torch.tensor(2., requires_grad=True)
b2 = torch.tensor(1.)
y1 = x*w1 + b1
y2 = y1*w2 + b2
dy2_dy1 = torch.autograd.grad(y2, [y1], retain_graph=True)[0]
dy1_dw1 = torch.autograd.grad(y1, [w1], retain_graph=True)[0]
dy2_dw1 = torch.autograd.grad(y2, [w1])[0]
print(dy2_dy1) # tensor(2.)
print(dy1_dw1) # tensor(1.)
print(dy2_dw1) # tensor(2.) dy2_dw1 == dy2_dy1 * dy1_dw1
3. 对Himmelblau函数的优化实例
- Himmelblau函数:
[f(x,y)=(x^{2}+y-11)^{2}+(x+y^{2}-7)^{2}
]
有四个全局最小解,且值都为0,常用来检验 优化算法的表现。
np.meshgrid(X, Y)函数
生成网格点坐标矩阵,比如:二维坐标系中,X轴可以取三个值1,2,3,Y轴可以取三个值7,8,共可以获得6个点的坐标:
(1,7)(2,7)(3,7)
(1,8)(2,8)(3,8)
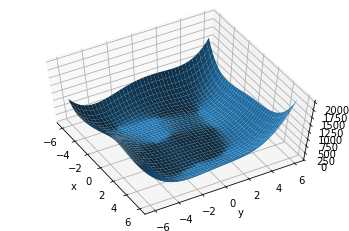
首先可视化函数图像:
import numpy as np
import torch
from matplotlib import pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
def himmelblau(x):
return (x[0] ** 2 + x[1] - 11) ** 2 + (x[0] + x[1] ** 2 - 7) ** 2
x = np.arange(-6, 6, 0.1) # x.shape=(120,)
y = np.arange(-6, 6, 0.1) # y.shape=(120,)
X, Y = np.meshgrid(x, y) # X.shape=(120, 120), Y.shape=(120,120)
Z = himmelblau([X, Y])
fig = plt.figure("himmeblau")
ax = fig.gca(projection='3d')
ax.plot_surface(X, Y, Z)
ax.view_init(60, -30)
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
-
使用 随机梯度下降(SGD) 进行优化
- 优化目标:找到使 himmelblau函数 最小的坐标 x[0],x[1]:
# 先对x[0],x[1]进行初始化,不同的初始值可能会得到不同的结果
x = torch.tensor([0., 0.], requires_grad=True)
# 定义Adam优化器,指明优化目标是x,学习率是1e-3
optimizer=torch.optim.Adam([x], lr=1e-3)
for step in range(20000):
pred = himmelblau(x)
optimizer.zero_grad() # 将梯度设置为0
pred.backward() # 生成当前所在点函数值相关的梯度信息,这里即优化目标的梯度信息
optimizer.step() # 使用梯度信息更新优化目标的值,即更新x[0]和x[1]
if step % 2000 == 0:
print("step={},x={},f(x)={}".format(step, x.tolist(), pred.item()))
view result
step=0,x=[0.0009999999310821295, 0.0009999999310821295],f(x)=170.0
step=2000,x=[2.3331806659698486, 1.9540694952011108],f(x)=13.730916023254395
step=4000,x=[2.9820079803466797, 2.0270984172821045],f(x)=0.014858869835734367
step=6000,x=[2.999983549118042, 2.0000221729278564],f(x)=1.1074007488787174e-08
step=8000,x=[2.9999938011169434, 2.0000083446502686],f(x)=1.5572823031106964e-09
step=10000,x=[2.999997854232788, 2.000002861022949],f(x)=1.8189894035458565e-10
step=12000,x=[2.9999992847442627, 2.0000009536743164],f(x)=1.6370904631912708e-11
step=14000,x=[2.999999761581421, 2.000000238418579],f(x)=1.8189894035458565e-12
step=16000,x=[3.0, 2.0],f(x)=0.0
step=18000,x=[3.0, 2.0],f(x)=0.0
- 如果第二行初始化改为如下,会得到另一个优化结果:
# 修改这里
x = torch.tensor([4., 0.], requires_grad=True)
# 定义Adam优化器,指明优化目标是x,学习率是1e-3
optimizer=torch.optim.Adam([x], lr=1e-3)
for step in range(20000):
pred = himmelblau(x)
optimizer.zero_grad() # 将梯度设置为0
pred.backward() # 生成当前所在点函数值相关的梯度信息,这里即优化目标的梯度信息
optimizer.step() # 使用梯度信息更新优化目标的值,即更新x[0]和x[1]
if step % 2000 == 0:
print("step={},x={},f(x)={}".format(step, x.tolist(), pred.item()))
view result
step=0,x=[3.999000072479248, -0.0009999999310821295],f(x)=34.0
step=2000,x=[3.5741987228393555, -1.764183521270752],f(x)=0.09904692322015762
step=4000,x=[3.5844225883483887, -1.8481197357177734],f(x)=2.1100277081131935e-09
step=6000,x=[3.5844264030456543, -1.8481241464614868],f(x)=2.41016095969826e-10
step=8000,x=[3.58442759513855, -1.848125696182251],f(x)=2.9103830456733704e-11
step=10000,x=[3.584428310394287, -1.8481262922286987],f(x)=9.094947017729282e-13
step=12000,x=[3.584428310394287, -1.8481265306472778],f(x)=0.0
step=14000,x=[3.584428310394287, -1.8481265306472778],f(x)=0.0
step=16000,x=[3.584428310394287, -1.8481265306472778],f(x)=0.0
step=18000,x=[3.584428310394287, -1.8481265306472778],f(x)=0.0
Tip:
- 使用 optimizer的流程就是三行代码:
optimizer.zero_grad()
loss.backward()
optimizer.step()
-
首先,循环里每个变量都拥有一个优化器
- 需要在循环里逐个
zero_grad(),清理掉上一步的残余值。
- 需要在循环里逐个
-
之后,对loss调用
backward()的时候- 它们的梯度信息会被保存在自身的两个属性(grad 和 requires_grad)当中。
-
最后,调用
optimizer.step(),就是一个apply gradients的过程- 将更新值 重新赋给parameters。
[x[0]=x[0]-lr*alpha x[0] \
x[1]=x[1]-lr*alpha x[1]
]