浅谈原子操作、volatile、CPU执行顺序
在计算机发展的鸿蒙年代,程序都是顺序执行,编译器也只是简单地翻译指令,随着硬件和软件的飞速增长,原来的工具和硬件渐渐地力不从心,也逐渐涌现出各路大神在原来的基础上进行优化,有些优化是完全地升级,而有些优化则是建立在牺牲其他性能之上,当然这种优化在大多数情况下是正向的,只是在某些时候会体现出负面的效果,今天我们就来谈谈那些由于软硬件的优化产生的问题。
原子操作和锁机制
学过C语言的我们都知道一个概念:程序是顺序执行的。但是由于操作系统的存在,这个概念变成了局部适用,因为操作系统的工作就是让多任务并发运行(单CPU下,虽然底层仍然是顺序执行,至少从用户角度来说,任务是并发运行的)。
操作系统的发明简直就是一次革命,尤其是桌面操作系统的盛行,对人类设备的发展起到了非常大的作用。
对于单核CPU而言,操作系统实现多任务的方式就是通过中断将时间不断地分片,通过某种调度手法,让多个任务循环地占用CPU的执行时间,造成多任务在同时运行的假象,当然,前提是CPU的运行频率足够快,用户感觉不到任务之间的切换。
但是这就带来一个问题,如果某个任务需要做一个不能被打断的任务,反而没那么容易。
既然提出问题,当然就有解决方案,就是原子操作。
原子操作
我们在化学课上学到,在目前的知识体系下,原子是不可分割的,原子操作因此而得名。
它表明:操作要么不进行,要么就直到执行完,不会被其他线程打断。在linux下,定义了两种原子操作,分别是int型变量操作和位操作方式。
它的定义是这样的:
typedef struct {
int counter;
} atomic_t;
可以看到,atomic_t类型的原子操作就是针对int型变量进行操作。
原子操作的API:
atomic_read(atomic_t *v) //读原子变量
atomic_set(atomic_t *v,int i) //设置原子变量值
atomic_add(int i, atomic_t *v) //原子变量加i
atomic_sub(int i, atomic_t *v) //原子变量减i
.... //
看到这里有些朋友就有疑问了,int变量的操作难道不就是原子操作吗?就像:
int i = 0
i++
这应该是原子操作吧。
但是事实并非如此,int i = 0,这条赋值语句确实是赋值语句,但是i++并非是原子操作,它包含以下的操作:
1、从内存中取出i
2、i加1
3、将i写回内存
那么,为什么需要原子操作?我们可以参考上面的三个步骤,如果在执行完第一步时,另一个线程被调度执行,刚好也操作到i(i为全局变量),操作完之后再回到当前线程,此时i的值还是在原来的值上加1,这就违背了程序的意图:我们可以看下面的过程,设i为全局变量,初始值为5.
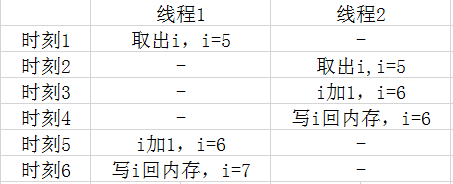
可以看到,如果不进行原子操作,i经历了两次++,值仅仅是增加了1,显然有问题,所以需要用到原子操作。
除了int型原子操作,linux下还支持设置位的原子操作,本文并不去细究原子操作细节,就不再赘述。
锁机制
上述原子操作的效果可以看成:要操作的数据在操作开始直到操作结束,不会被其他任务所影响,从数据的角度而不是操作的角度出发,还有一种机制可以实现防止数据被其它任务破坏,就是锁机制,一般是使用互斥锁。
但是需要注意的是,锁机制并不是保证原子操作,它只是防止其他任务操作不想被操作的数据,而且我们需要知道的是,计算机的运行就是对数据的处理,锁住的对象应该是数据而非指令,不同于原子操作的是,在操作加锁数据时,可能出现任务调度而执行其他程序,但是它可以保护数据不被其他程序操作,在执行效果上与原子操作其实是大同小异的,即一个任务要处理部分数据,从操作开始到操作完成,这部分数据都只会被当前任务所影响。
同时,原子操作目前在各大平台上一般都只支持int型和bit操作,对于复杂的,大块的数据,原子操作显然力不从心。
volatile
在数据操作的多线程同步上是不是使用了原子操作就万事大吉了呢?非也非也!!
gcc编译器为了提高执行效率,和硬件相配合做了一件事,就是采用缓存机制,缓存数据的好处就是提高效率,具体的操作就是对代码进行优化。
当程序在运行时,如果每次读写数据都直接从内存读写,效率很快就达到瓶颈,编译器在这里做的优化就是如果一个数据会被频繁使用,就会被缓存在寄存器或者高速缓存中,下一次再使用的时候就不需要重新从内存中读取,直接从寄存器或者高速缓冲中读取即可,这样就大幅减少了数据访问时间,达到提高程序运行效率的效果。
但是,在多线程和中断程序的的环境下,这种编译器执行的优化将会带来同步问题。
要理解这种同步问题,首先我们需要建立一个概念:多线程共享数据空间,但是拥有各自的栈数据和寄存器数据备份,当轮到本线程运行时,系统将上一线程的寄存器数据,堆栈数据保存起来,然后将当前线程的运行数据恢复到寄存器中,设置PC指针跳转执行当前线程。
我们看下面的例子:
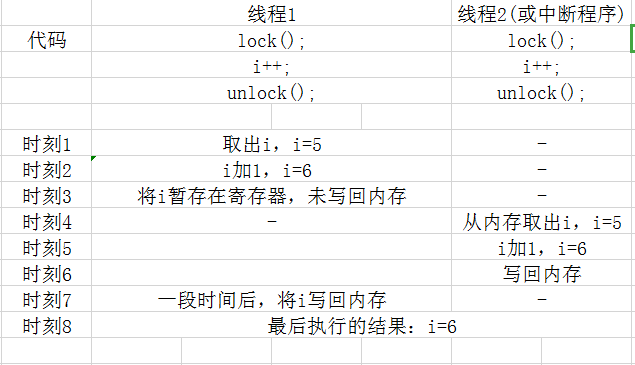
从上面的例子可以看到,尽管线程中使用锁机制来保障数据在操作时不被其他任务所干扰,但是由于数据被缓存而导致线程之间的数据出现同步问题。
话说回来,编译器也不至于那么蠢,对于任何指令都无脑进行缓存的优化,它会在缓存数据的同时会分析数据之间的依赖关系,但是,在多线程或者中断程序中,由于程序的执行是一种非预定义行为,编译器的优化可能并不能考虑到这一点,所以,在编写多线程程序时,对于跨线程的全局变量,或者在中断中的全局变量,一定要用volatile进行修饰,不然将发生非常难以调试的bug。
至此,编译器开发人员渐渐意识到这种优化带来的问题,便增加了一个关键字:volatile,volatile关键字声明的数据,即告诉编译器,所有由volatile修饰的数据都不要进行优化,每次的读写都老老实实地从内存中读出然后写回。
至于使用方法,和static const一样:
volatile int x;
volatile修饰和原子操作
咋一看,这两个东西好像是一样的,但是仔细一瞧,我们还是可以看出他们之间的区别:
-
原子操作和锁强调的是数据在任务执行过程中不会被其他任务操作到而产生冲突。
-
volatile关键词的修饰则强调数据在存取时直接操作内存,而不要缓存机制对其进行缓存。
一个解决的是同时操作带来的问题,一个解决的是操作完之后是否缓存(编译器优化)带来的问题。
CPU的乱序执行
在计算机工程领域,乱序执行(错序执行,英语:out-of-order execution,简称OoOE或OOE)是一种应用在高性能微处理器中来利用指令周期以避免特定类型的延迟消耗的范式。
在这种范式中,处理器在一个由输入数据可用性所决定的顺序中执行指令,而不是由程序的原始数据所决定。在这种方式下,可以避免因为获取下一条程序指令所引起的处理器等待,取而代之的处理下一条可以立即执行的指令。 --维基百科
通俗地说,CPU内有多个计算单元,乱序执行的目的就是尽可能多的地同时调动CPU内运算单元来提高运算效率(基于某种成熟算法),但是,编译器编译出来的代码并非能达到这个效果,所以就需要CPU自己来调整代码执行顺序,举个例子,如果我们要打开笔记本开始工作,流程大概是这样的:
拿出笔记本并按下开机键 -> 等待开机完成 -> 插上鼠标键盘 -> 打开软件开始修改bug
但是,如果遵照这个流程,在等待开机完成那段时间就是明显的浪费,所以,聪明的程序员一般会这样:
拿出笔记本并按下开机键 -> 等待开机完成
插上鼠标键盘
回想昨天的bug,理清思路 -> 打开软件开始修改bug
这样,就明显节省了整个流程的时间。
CPU也可以是这样,尽管你的指令告诉它应该一步一步来,但是它觉得有更高效的做法,而且还不用考虑人(机)道主义,如果能榨干它的最后一点价值,请尽管去做。
到这里我们大概已经理解了CPU乱序执行的原因,但是遗憾的是,对于CPU的乱序执行优化并非有一个统一标准,因为更多地涉及到硬件,所以往往各厂商之间都有不同的优化策略,优化效果也是不尽相同。
我们看下面的例子:
a = 1
b = 1
上面简单的两条语句,在这样一种情况下会导致第二条比一条先执行:
操作a的时间需要等待的时间较长,而b不需要。比较通常的情况就是a在内存中,而b被缓存在寄存器或者高速缓存中且可用,对a发出读写指令后,需要等待。
CPU检测这两条语句之间并没有依赖性,可以调整执行顺序。
先执行b = 1,再执行a = 1,以提高效率。
在单核的情况下这是没有问题的,主要是因为CPU能判断两条语句之间是否存在依赖关系,但是如果放在多核系统上就会出现麻烦,我们来看看下面的例子:

在上述提到的情况中,CPU0乱序执行,先执行了b = 1,此时a还不等于1,所以在CPU1在检测到b!=1时,立马执行assert(a == 1),导致assert报错。
内存屏障
为了解决CPU乱序执行而带来的问题,内存屏障应运而生,许多CPU都提供内存屏障指令,内存屏障指令也是平台各异的,经典的X86下有ifence、mfence、sfence指令。
在Visual C++2005标准中,保证volatile提供一种内存屏障,组织编译器和CPU重新安排读入和写出。
PowerPC上则是lwsync。我们把内存屏障指令插入不想被优化的指令之后即可达到相应的目的。
小结
在多线程中,为了解决多个线程同时操作同一份数据而带来同步问题,产生了原子操作,锁机制。
在缓存机制中,为了解决程序对数据的缓存而导致数据同步问题,增加了volatile关键词修饰。
在多核系统中,由于CPU乱序执行可能带来的问题,产生了内存屏障机制,以防止内存优化带来的问题。
参考:http://www.voidcn.com/article/p-fiewgxpd-bbh.html
《程序员的自我修养--链接、装载与库》
好了,关于原子操作、volatile、CPU执行顺序的讨论就到此为止啦,如果朋友们对于这个有什么疑问或者发现有文章中有什么错误,欢迎留言
原创博客,转载请注明出处!
祝各位早日实现项目丛中过,bug不沾身.