概述
1.字典介绍
2.字典实现
3.字典API
字典介绍
Redis里面很多地方用到了字典,比如Redis数据库就是使用字典作为底层实现的,哈希键的底层实现也是使用的字典。Redis字典底层使用的哈希表来实现,每个哈希表节点就保存了一个键值对。hash表的原理可以参考java里面的hashmap介绍。
哈希表的数据结构:
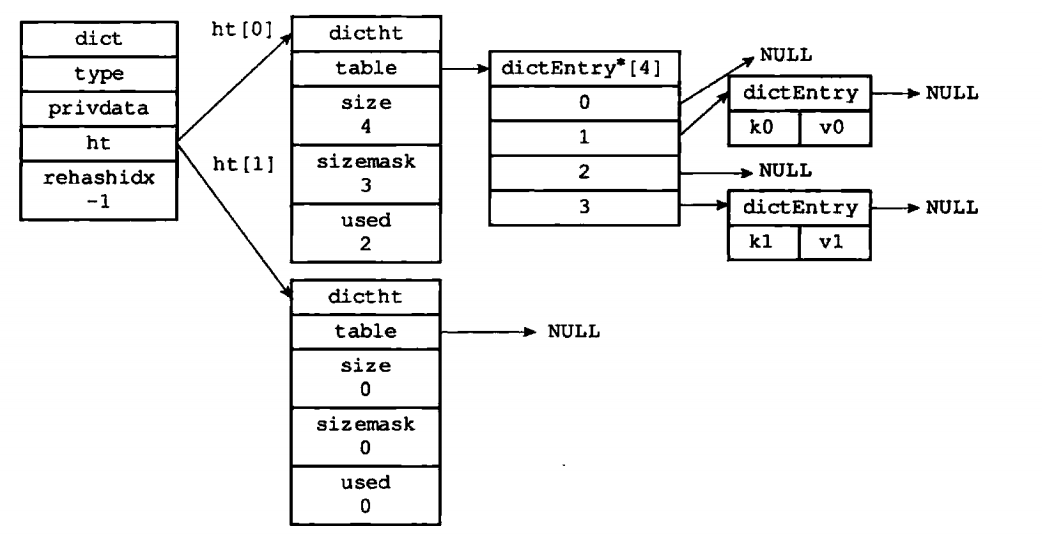
Hash表结构 typedef struct dictht { dictEntry **table; //哈希表数组 unsigned long size; //hash表大小 unsigned long sizemask; //hash表大小掩码,总是等于size-1,用于计算哈希索引 unsigned long used; //已使用大小 } dictht;
Hash表节点使用dictEntry表示:
typedef struct dictEntry { void *key; //键 union { //值 void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next; //指向下个哈希表节点,形成链表(在hash冲突时使用) } dictEntry;
字典的数据结构:
typedef struct dict { dictType *type; //类型特定函数 void *privdata; //私有数据 dictht ht[2]; //hash表 long rehashidx; /* rehashing not in progress if rehashidx == -1 */ int iterators; /* number of iterators currently running */ } dict;
字典的状态如下:
字典实现
前面讲到了字典涉及到的一些数据结构,但是字典具体是怎么实现呢? 比如我们在插入一条数据时,字典进行了什么操作?
比如现在要将k0,v0键值对插入到字典中,程序会先计算key的哈希值和索引值,再根据索引值将包括新键值对的哈希表节点放到哈希表数组对应的索引上。
Redis中计算方法如下:
哈希值:hash=dict->type->hashFunction(key)
索引值:使用hash值和hash表的sizemask,计算出索引值:index=hash & dict->ht[x].sizemask;
假设计算出k0对应的索引值为0,那k0,v0对应的哈希表节点应该放到哈希数组的索引0的位置上:
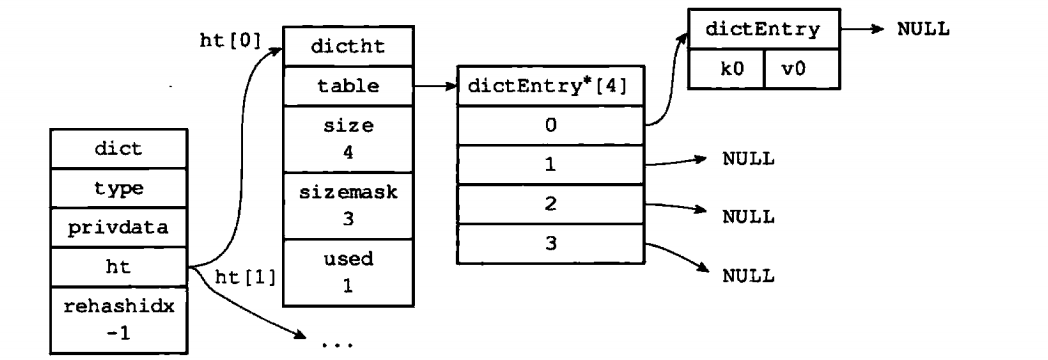
那如果计算索引的时候,出现冲突怎么办? 比如k0和k10计算出来的索引如果是一样的呢? 会不会k10把k0替换掉 ?
之前看数据结构的时候,看到hash节点hashEntry有的next指针用来执行hash节点的下一个节点,所以hash冲突的时候,会使用next将相同索引的节点组成一个单向链表。由于dictEntry没有指向链表表尾的指针,所以Redis每次将新的节点放在链表的表头位置。
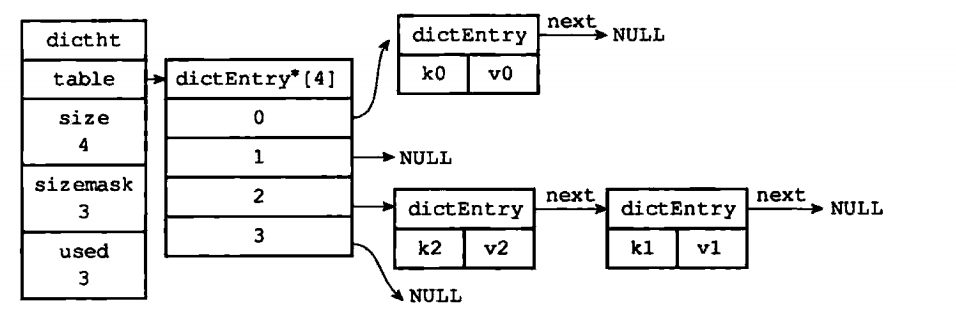
在看字典数据结构的时候,还有个rehashidx属性,这个是用来干嘛的? 当我们在操作时,哈希表保存的键值对会逐渐增多或减少,为了让hash表的负载因子保持在一个合理的范围内,程序会对hash表的大小进行相应的扩展或者收缩。
rehash策略:
再看字典数据结构,ht的大小为ht[2],即存在ht[0]和ht[1],一般情况下只会用到ht[0],ht[1]只会在rehash的时候使用。
可以想到,rehash的步骤大概为:
1.需要用到一个临时的ht[1],为ht[1]分配空间;
rehash的时候需要为ht[1]分配内存空间,分配多少? 这个由ht[0]中的used属性和要执行的操作决定。
a.如果要执行扩张操作,ht[1]空间大小为第一个大于等于ht[0].used*2的2n次幂; 比如ht[0]used为4, 那么扩张操作分配的内存大小要大于4*2, 而4*2=8 刚好是2的3次幂。 所以扩张的大小就为8;
b.如果要执行收缩操作,ht[1]空间大小为第一个大于等于ht[0].used的2n次幂; 比如ht[0]used为4,那么收缩的大小要大于等于4,而4刚好是2的2次幂,所以收缩大小为4;
2.将ht[0]中的元素重新hash(重新计算新的hash和索引值)到新的ht[1];
3.将ht[1]修改为ht[0],将原来的ht[0]释放掉,修改为ht[1],为下次rehash准备。
那什么时候会对hash表进行扩展或者收缩呢?
当以下任一条件满足时,程序会自动对哈希表进行扩展操作:
- 服务器没有执行BGSAVE或BGREWRITEAOF时,并且哈希表的负载因子大于等于1;负载因子=used/size;
- 服务器正在执行BGSAVE或BGREWRITEAOF时,并且哈希表的负载因子大于等于5;
当哈希表的负载因子小于0.1时,对hash表进行收缩操作。
为什么区分执行和未执行BGSAVE或BGREWRITEAOF呢?
因为执行BGSAVE或BGREWRITEAOF的时候,会fork出来一个子进程来执行,为优化子进程的效率,尽量避免在子进程中进行对哈希表的扩展操作,这样可以避免不必要的内存写入。
这时候可能问题又来了,如果h[0]里面的数据特别的多,每个节点都需要rehash到新的h[1]数组中,这样岂不会造成性能问题?
其实Redis是分多次,渐进式的将h[0]中的元素重新hash到新的h[1]中。又有几个问题:
1.渐进式的hash的怎么知道到哪个节点了?
2.渐进式的hash,那取数据是从ht[0]中取还是ht[1]中取? 有可能取的数据还是在ht[0]中,没有移到ht[1]中呢?
3.新添加的字典保存在哪里?
问题1:
字典的数据结构中有个rehashidx,这个用来保存rehash到哪个索引了,所以直接取数组索引中所有的哈希节点,rehash到新的ht[1],然后再将rehashidx+1,直接最后一个,rehashidx被设置为-1;
问题2:
在rehash期间,所有对数据的查询/修改/删除操作会先查找ht[0],如果找不到再找ht[1]
问题3:
新加入的字典会被保存在ht[1]中,这样保证ht[0]中的数量只减不增。
字典API源码
接下来看下源码实现
先看下添加元素
/* Add an element to the target hash table */ int dictAdd(dict *d, void *key, void *val) { dictEntry *entry = dictAddRaw(d,key); //添加一个哈希节点 if (!entry) return DICT_ERR; dictSetVal(d, entry, val); //设置value return DICT_OK; } /* Low level add. This function adds the entry but instead of setting * a value returns the dictEntry structure to the user, that will make * sure to fill the value field as he wishes. * * This function is also directly exposed to the user API to be called * mainly in order to store non-pointers inside the hash value, example: * * entry = dictAddRaw(dict,mykey); * if (entry != NULL) dictSetSignedIntegerVal(entry,1000); * * Return values: * * If key already exists NULL is returned. * If key was added, the hash entry is returned to be manipulated by the caller. */ dictEntry *dictAddRaw(dict *d, void *key) { int index; dictEntry *entry; dictht *ht; if (dictIsRehashing(d)) _dictRehashStep(d); //如果正则rehash,进行rehash操作 /* Get the index of the new element, or -1 if * the element already exists. */ if ((index = _dictKeyIndex(d, key)) == -1) //如果存在,则返回 return NULL; /* Allocate the memory and store the new entry */ ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0]; //正在rehash,取ht[1],ht为ht[0],也验证了上面问题3的答案。 entry = zmalloc(sizeof(*entry)); //分配内存空间 entry->next = ht->table[index]; //新元素加入头节点 ht->table[index] = entry; ht->used++; /* Set the hash entry fields. */ dictSetKey(d, entry, key); //设置key return entry; }
再来看下rehash的操作:
int dictRehash(dict *d, int n) { int empty_visits = n*10; /* Max number of empty buckets to visit. */ if (!dictIsRehashing(d)) return 0; while(n-- && d->ht[0].used != 0) { dictEntry *de, *nextde; /* Note that rehashidx can't overflow as we are sure there are more * elements because ht[0].used != 0 */ assert(d->ht[0].size > (unsigned long)d->rehashidx); while(d->ht[0].table[d->rehashidx] == NULL) { d->rehashidx++; if (--empty_visits == 0) return 1; } de = d->ht[0].table[d->rehashidx]; //正则rehash的哈希节点 /* Move all the keys in this bucket from the old to the new hash HT */ while(de) { unsigned int h; nextde = de->next; /* Get the index in the new hash table */ h = dictHashKey(d, de->key) & d->ht[1].sizemask; //新hash表中的索引值 de->next = d->ht[1].table[h]; //插入 d->ht[1].table[h] = de; d->ht[0].used--; d->ht[1].used++; de = nextde; } d->ht[0].table[d->rehashidx] = NULL; d->rehashidx++; } /* Check if we already rehashed the whole table... */ if (d->ht[0].used == 0) { //ht[0]中的used为0,说明rehash完成了 zfree(d->ht[0].table); //释放ht[0] d->ht[0] = d->ht[1]; //ht[1]变为ht[0] _dictReset(&d->ht[1]); //重置ht[1] d->rehashidx = -1; return 0; } /* More to rehash... */ return 1; }
再看下怎么为ht[1]进行内存分配的:
/* Expand or create the hash table */ int dictExpand(dict *d, unsigned long size) { dictht n; /* the new hash table */ unsigned long realsize = _dictNextPower(size); //为ht[1]计算分配的空间大小 /* the size is invalid if it is smaller than the number of * elements already inside the hash table */ if (dictIsRehashing(d) || d->ht[0].used > size) return DICT_ERR; /* Rehashing to the same table size is not useful. */ if (realsize == d->ht[0].size) return DICT_ERR; /* Allocate the new hash table and initialize all pointers to NULL */ n.size = realsize; //新的哈希表大小 n.sizemask = realsize-1; n.table = zcalloc(realsize*sizeof(dictEntry*)); n.used = 0; /* Is this the first initialization? If so it's not really a rehashing * we just set the first hash table so that it can accept keys. */ if (d->ht[0].table == NULL) { //第一次加入元素时,创建hash表 d->ht[0] = n; return DICT_OK; } /* Prepare a second hash table for incremental rehashing */ d->ht[1] = n; //rehash,将新的hash表赋值给ht[1] d->rehashidx = 0; return DICT_OK; }
/* Our hash table capability is a power of two */ static unsigned long _dictNextPower(unsigned long size) { unsigned long i = DICT_HT_INITIAL_SIZE; if (size >= LONG_MAX) return LONG_MAX; while(1) { if (i >= size) //size为第一个大于等于size的2的幂次方 return i; i *= 2; } }