何为异步
其实我们谈论的异步库都是基于计算机模型Event Loop
举例
我们知道,每一个程序运行都会开启一个进程,在tcpserver服务器历史上,主要有3种方式来处理客户端来的连接。
为了方便说明,我们把tcpserver想象成对银行办理业务的过程,你每次去银行办理业务的时候,其实真正办理业务的时间并不长,其中很多时候,银行的工作人员也在等待,比如她操作一笔业务,电脑还没有及时反应过来,她没事可做,只能等待;打印各种文件的时候,也在等待。这其实跟我们的tcpserver是一样的,很多应用,我们的tcpserver一直在等待。
第一,阻塞排队。银行只开通一个窗口,每个人过来,都要排队,每一个人都要等待,其中还有很多时候,银行的工作人员在等电脑、打印机的操作时间。这种方式效率最低下。
第二,子进程。每次来一个客户,银行都开启一个窗口,专门接待,但银行的窗口不是无限的,每开启一个窗口,都有代价。这种方式比上面好了一些,但效率还不是那么高。
第三,线程。银行看到每个业务员虽然一直在忙活,但中间等待时间过长,效率提高不上来。于是,领导规定,每个业务员同时处理10个客户(1个进程开始10个线程),在处理客户1的空余时间,再处理客户2,或者其他的。嗯,貌似效率提高了,但业务员同时接这么多客户,极其容易出错(线程模式,确实容易出错,而且还不好控制,通常线程都只是处理比较单一、简单的任务)。
好了,经过对历史问题的研究,银行终于想到了终极大法,异步。银行请了机器人做业务员,并且把所有的客户都围成一个圈(这个圈就是eventloop),机器人站在这个圈的中间,不停的旋转(无限循环)。机器人每次接到一个客户,都让客户加入到这个圈子里。然后就开始处理业务,处理业务,那旋转暂停,如果在处理这个业务的时候,遇到任何忙等待行为,比如操作打印机等待、操作电脑时等待,都会先把这个业务挂起来,保存好(保存上下文环境,其实可以想象成压栈),然后继续旋转,如果有其他业务过来,处理之,继续上述行为。这时候,有个业务等待完毕,发送信号给机器人,机器人把刚才挂起的这个业务环境(把保存好的上下文环境拉出来,想象成出栈),然后继续处理,一直到处理完为止。
整个过程就是无限循环,遇到事件就处理,如果这个事件需要等待,就挂起,继续循环,如果等待完毕,发送信号给循环,继续处理,完毕后,继续循环。这就是异步。
对比历史的3个过程,异步是不是效率明显要比之前的高很多?但是也有代价,尤其对程序员要求比较高,什么时候该保存上下文?什么时候出来?出错的时候,如何处理?等等,这个以后我们会逐渐介绍这其中的问题。

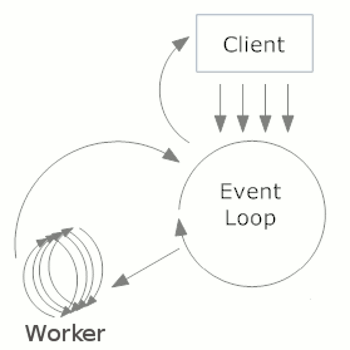
下面我们回到实际的twisted,这个图是官方引用图,我觉得非常好的诠释了twisted的运行过程。通过这个图,再结合我上面的例子,我想大家对twisted的运行过程有个基本了解了。
实际上,这个reactor loop就是整合twisted最核心的东西,所有的事件都在这个“圈”上,而在此基础上,再加上socket,就是接受网络客户端数据的过程。这个圈在没有socket的情况下,也可以工作。以后我们会遇到twisted结合rabbitmq的情况,rabbitmq的消费者也是一个"圈",其实就是把这个"圈"套在twisted的哪个"圈"上,只不过twisted的任何事件,都需要异步化。
上面说了这么多概念,我们就用代码试试twisted。我发现网上很多博客开始介绍twisted,往往一大堆代码,新手都不知道怎么入手,这对新手来说,是一个难题。我们今天就尝试解决这个难题。
from twisted.internet import reactor reactor.run()
代码如上,就1行代码,直接运行,这时候这个"圈"就运行起来了。没有socket,不能接受客户端写入数据。
在此基础上,加一点料。

import time
def hello():
print("Hello world!===>" + str(int(time.time())))
from twisted.internet import reactor
reactor.callWhenRunning(hello)
reactor.callLater(3, hello)
reactor.run()
看代码,我想,你就是不懂twisted,看字面意思,也知道这怎么回事了吧。callWhenRunning,就是reactor开始运行的时候,就触发hello函数;callLater就是3秒以后再触发一次。看一下结果
/usr/bin/python3.5 /home/yudahai/PycharmProjects/test0001/test001.py Hello world!===>1466129667 Hello world!===>1466129670
结果也这样,是不是很简单?对,单纯的reactor确实非常简单。我们多尝试复杂点的任务看看。
import time
def hello(name):
print("Hello world!===>" + name + '===>' + str(int(time.time())))
from twisted.internet import reactor, task
task1 = task.LoopingCall(hello, 'ding')
task1.start(10)
reactor.callWhenRunning(hello, 'yudahai')
reactor.callLater(3, hello, 'yuyue')
reactor.run()
这面在函数里面,多加了一个参数,又在其中,加了一个循环任务taks1,task1每10秒运行一次。task用twisted会经常用到,因为我们会轮询检测每个连接上来的客户端意外断线的情况,这时候就要用到task。好了,看看结果。
/usr/bin/python3.5 /home/yudahai/PycharmProjects/test0001/test001.py Hello world!===>ding===>1466130033 Hello world!===>yudahai===>1466130033 Hello world!===>yuyue===>1466130036 Hello world!===>ding===>1466130043 Hello world!===>ding===>1466130053 Hello world!===>ding===>1466130063 Hello world!===>ding===>1466130073 Hello world!===>ding===>1466130083 Hello world!===>ding===>1466130093 Hello world!===>ding===>1466130103
看到结果,大家应该对日常twisted这个"圈"会基本使用了吧。
嗯,基本使用会了,但貌似这个很简单呀,没有网上所说的,twisted如何难呀?貌似也没看到中间有任何代价呀?为什么一定要异步呢?为什么中间不能阻塞呢?好吧,上面的例子确实看不出来,我们来看如下一段代码,看看阻塞的效果。大家都知道,我们这边是不能访问google网站的,我们在中间试试访问google网站,看看效果会咋样。
import time
import requests
def hello(name):
print("Hello world!===>" + name + '===>' + str(int(time.time())))
def request_google():
res = requests.get('http://www.google.com')
return res
from twisted.internet import reactor, task
reactor.callWhenRunning(hello, 'yudahai')
reactor.callLater(1, request_google)
reactor.callLater(3, hello, 'yuyue')
reactor.run()
我在开始的时候运行一个打印任务,非阻塞,然后1秒之后,发送一个指向google的请求,到第3秒的时候,再执行打印。看看结果
/usr/bin/python3.5 /home/yudahai/PycharmProjects/test0001/test001.py
Hello world!===>yudahai===>1466130855
Hello world!===>yuyue===>1466130984
Unhandled Error
Traceback (most recent call last):
File "/home/yudahai/PycharmProjects/test0001/test001.py", line 21, in <module>
reactor.run()
File "/usr/local/lib/python3.5/dist-packages/twisted/internet/base.py", line 1194, in run
self.mainLoop()
File "/usr/local/lib/python3.5/dist-packages/twisted/internet/base.py", line 1203, in mainLoop
self.runUntilCurrent()
--- <exception caught here> ---
File "/usr/local/lib/python3.5/dist-packages/twisted/internet/base.py", line 825, in runUntilCurrent
call.func(*call.args, **call.kw)
File "/home/yudahai/PycharmProjects/test0001/test001.py", line 10, in request_google
res = requests.get('http://www.google.com')
File "/usr/local/lib/python3.5/dist-packages/requests/api.py", line 67, in get
return request('get', url, params=params, **kwargs)
File "/usr/local/lib/python3.5/dist-packages/requests/api.py", line 53, in request
return session.request(method=method, url=url, **kwargs)
File "/usr/local/lib/python3.5/dist-packages/requests/sessions.py", line 468, in request
resp = self.send(prep, **send_kwargs)
File "/usr/local/lib/python3.5/dist-packages/requests/sessions.py", line 576, in send
r = adapter.send(request, **kwargs)
File "/usr/local/lib/python3.5/dist-packages/requests/adapters.py", line 437, in send
raise ConnectionError(e, request=request)
requests.exceptions.ConnectionError: HTTPConnectionPool(host='www.google.com', port=80): Max retries exceeded with url: / (Caused by NewConnectionError('<requests.packages.urllib3.connection.HTTPConnection object at 0x7fc189c69e48>: Failed to establish a new connection: [Errno 101] Network is unreachable',))
看看2个打印之间的间隔,大概相差了130秒,也就是说,中间的130秒,这个程序什么事都没有干,仅仅是等待。当然,我这个例子有点极端,但在实际过程中,访问数据库,访问网络,都有可能阻塞住。程序一旦阻塞,效率会极其底下。
那该如何解决呢?这边有2种方法,一个是用twisted自带的httpclient进行访问,twisted自带的httpclient由于是异步的,不会阻塞住整个reactor的运行;其次是用线程的方式运行,注意,这里的线程不是python普通线程,是twisted自带的线程,它访问完毕的时候,会发送一个信号给reactor。下面我们分别用2中方法试试吧。
# coding:utf-8
import time
from twisted.web.client import Agent
from twisted.web.http_headers import Headers
from twisted.internet import reactor, task, defer
def hello(name):
print("Hello world!===>" + name + '===>' + str(int(time.time())))
@defer.inlineCallbacks
def request_google():
agent = Agent(reactor)
try:
result = yield agent.request('GET', 'http://www.google.com', Headers({'User-Agent': ['Twisted Web Client Example']}), None)
except Exception as e:
print e
return
print(result)
reactor.callWhenRunning(hello, 'yudahai')
reactor.callLater(1, request_google)
reactor.callLater(3, hello, 'yuyue')
reactor.run()
这就是非阻塞版本的代码,其中,request返回的是一个延迟对象,所以不会阻塞住reactor,看看结果。
/usr/bin/python2.7 /home/yudahai/PycharmProjects/test0001/test001.py Hello world!===>yudahai===>1466386544 Hello world!===>yuyue===>1466386547 User timeout caused connection failure.
除了访问google的,其他的都按时回来,访问谷歌的并没有阻塞reactor。
上面用非阻塞的方式访问过了,其实在现实过程中,我们很多库没有非阻塞模式的api,要非阻塞模式,一定要返回twisted的defer对象,如果写一个库,还要针对twisted写一个异步版,这肯定强人所难。而且很多时候,哪怕自己的函数,如果不是特别复杂,都可以用线程模式,twisted本身访问数据库就是线程模式。我们来看看线程模式的代码。
# coding:utf-8
import time
import requests
from twisted.internet import reactor, task, defer
def hello(name):
print("Hello world!===>" + name + '===>' + str(int(time.time())))
def request_google():
try:
result = requests.get('http://www.google.com', timeout=10)
except Exception as e:
print e
return
print(result)
reactor.callWhenRunning(hello, 'yudahai')
reactor.callInThread(request_google)
reactor.callLater(3, hello, 'yuyue')
reactor.run()
代码很简单,就是把request_google换成线程模式。看看结果。
/usr/bin/python2.7 /home/yudahai/PycharmProjects/test0001/test001.py
Hello world!===>yudahai===>1466387418
Hello world!===>yuyue===>1466387421
HTTPConnectionPool(host='www.google.com', port=80): Max retries exceeded with url: / (Caused by NewConnectionError('<requests.packages.urllib3.connection.HTTPConnection object at 0x7fc9da0b1ad0>: Failed to establish a new connection: [Errno 101] Network is unreachable',))
是不是也同样达到目的了?嗯,这时候,大家可能会在想,既然线程也可以把阻塞代码线程化,为啥还直接写异步代码呢?异步代码那么难写、难看还容易出错。
这边其实有几个理由,在twisted中,不能大量使用线程。
1、效率问题,如果用线程,我们干嘛还用twisted呢?线程会频繁切换cpu调度,如果大量使用线程,会极大浪费cpu资源,效率会严重下降。
2、线程安全,如果第一个问题稍微还有点理由的话,那线程安全问题绝对不能忽视了。比如用twisted接受网络数据的时候,是非线程安全的,如果用线程模式接受数据,会引起程序崩溃。twisted只有极少数的api支持线程。其实用的最多的例子就是消息队列的接受系统,很多初级程序员会用线程模式来做消息队列的接受方式,一开始没问题,结果运行一段时间以后,就会发现程序不能正常接受数据了,而且还不报错。twisted官方也建议大家,只要有异步库,一定优先使用异步库,线程只是做非常简单而且不是频繁的操作。