一、任务调度
多进程和多线程本质都是同时进行多个任务的操作,所以首先要理解任务调度这个概念,这些都是比较抽象的概念。
大部分操作系统(如Windows、Linux)的任务调度是采用时间片轮转的抢占式调度方式,也就是说一个任务执行一小段时间后强制暂停去执行下一个任务,每个任务轮流执行。任务执行的一小段时间叫做时间片,任务正在执行时的状态叫运行状态,任务执行一段时间后强制暂停去执行下一个任务,被暂停的任务就处于就绪状态等待下一个属于它的时间片的到来。这样每个任务都能得到执行,由于CPU的执行效率非常高,时间片非常短,在各个任务之间快速地切换,给人的感觉就是多个任务在“同时进行”,这也就是我们所说的并发(别觉得并发有多高深,它的实现很复杂,但它的概念很简单,就是一句话:多个任务同时执行)。多任务运行过程的示意图如下:

二、进程
首先,进程是一过程的描述。
我们都知道计算机的核心是CPU,它承担了所有的计算任务;而操作系统是计算机的管理者,它负责任务的调度、资源的分配和管理,统领整个计算机硬件;应用程序侧是具有某种功能的程序,程序是运行于操作系统之上的。
进程是一个具有一定独立功能的程序在一个数据集上的一次动态执行的过程,是操作系统进行资源分配和调度的一个独立单位,是应用程序运行的载体。进程是一种抽象的概念,从来没有统一的标准定义。进程一般由程序、数据集合和进程控制块三部分组成。程序用于描述进程要完成的功能,是控制进程执行的指令集;数据集合是程序在执行时所需要的数据和工作区;程序控制块(Program Control Block,简称PCB),包含进程的描述信息和控制信息,是进程存在的唯一标志。
进程具有的特征:
动态性:进程是程序的一次执行过程,是临时的,有生命期的,是动态产生,动态消亡的;
并发性:任何进程都可以同其他进程一起并发执行;
独立性:进程是系统进行资源分配和调度的一个独立单位;
结构性:进程由程序、数据和进程控制块三部分组成。
三、线程
在早期的操作系统中并没有线程的概念,进程是能拥有资源和独立运行的最小单位,也是程序执行的最小单位。任务调度采用的是时间片轮转的抢占式调度方式,而进程是任务调度的最小单位,每个进程有各自独立的一块内存,使得各个进程之间内存地址相互隔离。
后来,随着计算机的发展,对CPU的要求越来越高,进程之间的切换开销较大,已经无法满足越来越复杂的程序的要求了。于是就发明了线程,线程是程序执行中一个单一的顺序控制流程,是程序执行流的最小单元,是处理器调度和分派的基本单位。一个进程可以有一个或多个线程,各个线程之间共享程序的内存空间(也就是所在进程的内存空间)。一个标准的线程由线程ID、当前指令指针(PC)、寄存器和堆栈组成。而进程由内存空间(代码、数据、进程空间、打开的文件)和一个或多个线程组成。
三、进程和线程的区别
1.线程是程序执行的最小单位,而进程是操作系统分配资源的最小单位(在线程出现之前,进程确实是最小的执行单位);
2.一个进程由一个或多个线程组成,线程是一个进程中代码的不同执行路线;
3.进程之间相互独立,但同一进程下的各个线程之间共享程序的内存空间(包括代码段、数据集、堆等)及一些进程级的资源(如打开文件和信号),某进程内的线程在其它进程不可见;
4.调度和切换:线程上下文切换比进程上下文切换要快得多。
在早期的操作系统中并没有线程的概念,进程是能拥有资源和独立运行的最小单位,也是程序执行的最小单位。它相当于一个进程里只有一个线程,进程本身就是线程。所以线程有时被称为轻量级进程(Lightweight Process,LWP)。后来,随着计算机的发展,对多个任务之间上下文切换的效率要求越来越高,就抽象出一个更小的概念——线程,一般一个进程会有多个(也可是一个)线程。
四、多核心和多核
其实“同一时间点只有一个任务在执行”这句话是不准确的,至少它是不全面的。那多核处理器的情况下,线程是怎样执行呢?这就需要了解内核线程。
多核(心)处理器是指在一个处理器上集成多个运算核心从而提高计算能力,也就是有多个真正并行计算的处理核心,每一个处理核心对应一个内核线程。内核线程(Kernel Thread, KLT)就是直接由操作系统内核支持的线程,这种线程由内核来完成线程切换,内核通过操作调度器对线程进行调度,并负责将线程的任务映射到各个处理器上。一般一个处理核心对应一个内核线程,比如单核处理器对应一个内核线程,双核处理器对应两个内核线程,四核处理器对应四个内核线程。
现在的电脑一般是双核四线程、四核八线程,是采用超线程技术将一个物理处理核心模拟成两个逻辑处理核心,对应两个内核线程,所以在操作系统中看到的CPU数量是实际物理CPU数量的两倍,如你的电脑是双核四线程,打开“任务管理器性能”可以看到4个CPU的监视器,四核八线程可以看到8个CPU的监视器。
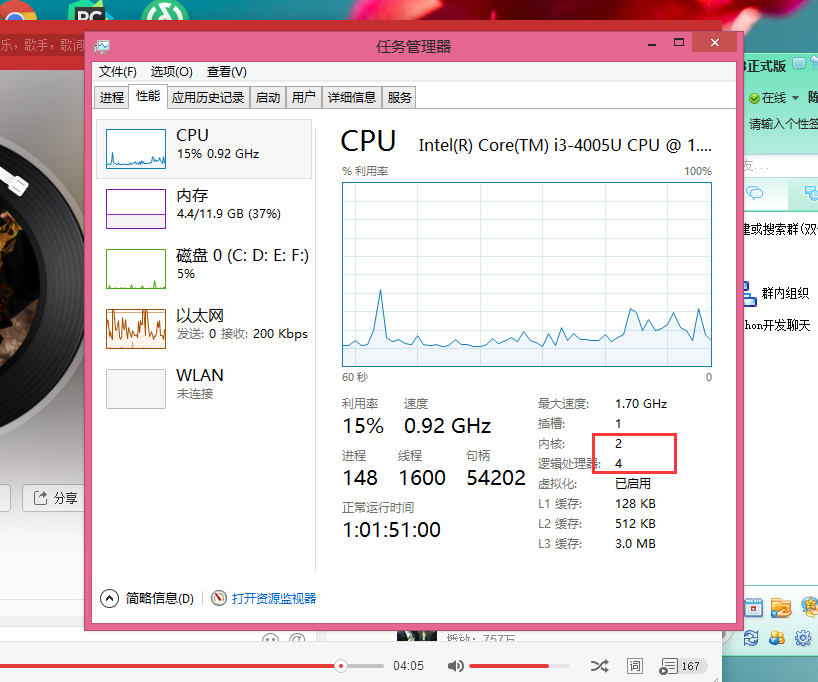
如图,这个就是双核四核心。
超线程技术就是利用特殊的硬件指令,把一个物理芯片模拟成两个逻辑处理核心,让单个处理器都能使用线程级并行计算,进而兼容多线程操作系统和软件,减少了CPU的闲置时间,提高的CPU的运行效率。这种超线程技术(如双核四线程)由处理器硬件的决定,同时也需要操作系统的支持才能在计算机中表现出来。
程序一般不会直接去使用内核线程,而是去使用内核线程的一种高级接口——轻量级进程(Light Weight Process,LWP),轻量级进程就是我们通常意义上所讲的线程(我们在这称它为用户线程),由于每个轻量级进程都由一个内核线程支持,因此只有先支持内核线程,才能有轻量级进程。用户线程与内核线程的对应关系有三种模型:一对一模型、多对一模型、多对多模型,在这以4个内核线程、3个用户线程为例对三种模型进行说明。
一对一模型:
对于一对一模型来说,一个用户线程就唯一地对应一个内核线程(反过来不一定成立,一个内核线程不一定有对应的用户线程)。这样,如果CPU没有采用超线程技术(如四核四线程的计算机),一个用户线程就唯一地映射到一个物理CPU的线程,线程之间的并发是真正的并发。一对一模型使用户线程具有与内核线程一样的优点,一个线程因某种原因阻塞时其他线程的执行不受影响;此处,一对一模型也可以让多线程程序在多处理器的系统上有更好的表现。
但一对一模型也有两个缺点:1.许多操作系统限制了内核线程的数量,因此一对一模型会使用户线程的数量受到限制;2.许多操作系统内核线程调度时,上下文切换的开销较大,导致用户线程的执行效率下降。
多对一模型:
多对一模型将多个用户线程映射到一个内核线程上,线程之间的切换由用户态的代码来进行,因此相对一对一模型,多对一模型的线程切换速度要快许多;此外,多对一模型对用户线程的数量几乎无限制。但多对一模型也有两个缺点:1.如果其中一个用户线程阻塞,那么其它所有线程都将无法执行,因为此时内核线程也随之阻塞了;2.在多处理器系统上,处理器数量的增加对多对一模型的线程性能不会有明显的增加,因为所有的用户线程都映射到一个处理器上了。
多对多模型:
多对多模型结合了一对一模型和多对一模型的优点,将多个用户线程映射到多个内核线程上。多对多模型的优点有:1.一个用户线程的阻塞不会导致所有线程的阻塞,因为此时还有别的内核线程被调度来执行;2.多对多模型对用户线程的数量没有限制;3.在多处理器的操作系统中,多对多模型的线程也能得到一定的性能提升,但提升的幅度不如一对一模型的高。
在现在流行的操作系统中,大都采用多对多的模型。
生命周期
线程的数量小于处理器的数量时,线程的并发是真正的并发,不同的线程运行在不同的处理器上。但当线程的数量大于处理器的数量时,线程的并发会受到一些阻碍,此时并不是真正的并发,因为此时至少有一个处理器会运行多个线程。
在单个处理器运行多个线程时,并发是一种模拟出来的状态。操作系统采用时间片轮转的方式轮流执行每一个线程。现在,几乎所有的现代操作系统采用的都是时间片轮转的抢占式调度方式,如我们熟悉的Unix、Linux、Windows及Mac OS X等流行的操作系统。
我们知道线程是程序执行的最小单位,也是任务执行的最小单位。在早期只有进程的操作系统中,进程有五种状态,创建、就绪、运行、阻塞(等待)、退出。早期的进程相当于现在的只有单个线程的进程,那么现在的多线程也有五种状态,现在的多线程的生命周期与早期进程的生命周期类似。
进程在运行过程有三种状态:就绪、运行、阻塞,创建和退出状态描述的是进程的创建过程和退出过程。
创建:进程正在创建,还不能运行。操作系统在创建进程时要进行的工作包括分配和建立进程控制块表项、建立资源表格并分配资源、加载程序并建立地址空间;
就绪:时间片已用完,此线程被强制暂停,等待下一个属于他的时间片到来;
运行:此线程正在执行,正在占用时间片;
阻塞:也叫等待状态,等待某一事件(如IO或另一个线程)执行完;
退出:进程已结束,所以也称结束状态,释放操作系统分配的资源。
线程的五种状态:
创建:一个新的线程被创建,等待该线程被调用执行;
就绪:时间片已用完,此线程被强制暂停,等待下一个属于他的时间片到来;
运行:此线程正在执行,正在占用时间片;
阻塞:也叫等待状态,等待某一事件(如IO或另一个线程)执行完;
退出:一个线程完成任务或者其他终止条件发生,该线程终止进入退出状态,退出状态释放该线程所分配的资源。
由此可以看出线程是比进程轻量级的。
五、同步和异步
在计算机领域,同步就是指一个进程在执行某个请求的时候,若该请求需要一段时间才能返回信息,那么这个进程将会一直等待下去,直到收到返回信息才继续执行下去;异步是指进程不需要一直等下去,而是继续执行下面的操作,不管其他进程的状态。当有消息返回时系统会通知进程进行处理,这样可以提高执行的效率。举个例子,打电话时就是同步通信,发短息时就是异步通信。
很明显,为了提高效率,使用同步是不可能的,所以必须使用异步通信是进程不被阻塞。
六、thread模块
import threading import time def countNum(n): # 定义某个线程要运行的函数 print("running on number:%s" %n) time.sleep(3) if __name__ == '__main__': t1 = threading.Thread(target=countNum,args=(23,)) #生成一个线程实例 t2 = threading.Thread(target=countNum,args=(34,)) t1.start() #启动线程 t2.start() print("ending!")
#继承Thread式创建 import threading import time class MyThread(threading.Thread): def __init__(self,num): threading.Thread.__init__(self) self.num=num def run(self): print("running on number:%s" %self.num) time.sleep(3) t1=MyThread(56) t2=MyThread(78) t1.start() t2.start() print("ending")
join()和setDaemon()


# join():在子线程完成运行之前,这个子线程的父线程将一直被阻塞。 # setDaemon(True): ''' 将线程声明为守护线程,必须在start() 方法调用之前设置,如果不设置为守护线程程序会被无限挂起。 当我们在程序运行中,执行一个主线程,如果主线程又创建一个子线程,主线程和子线程 就分兵两路,分别运行,那么当主线程完成 想退出时,会检验子线程是否完成。如果子线程未完成,则主线程会等待子线程完成后再退出。但是有时候我们需要的是只要主线程 完成了,不管子线程是否完成,都要和主线程一起退出,这时就可以 用setDaemon方法啦''' import threading from time import ctime,sleep import time def Music(name): print ("Begin listening to {name}. {time}".format(name=name,time=ctime())) sleep(3) print("end listening {time}".format(time=ctime())) def Blog(title): print ("Begin recording the {title}. {time}".format(title=title,time=ctime())) sleep(5) print('end recording {time}'.format(time=ctime())) threads = [] t1 = threading.Thread(target=Music,args=('FILL ME',)) t2 = threading.Thread(target=Blog,args=('',)) threads.append(t1) threads.append(t2) if __name__ == '__main__': #t2.setDaemon(True) for t in threads: #t.setDaemon(True) #注意:一定在start之前设置 t.start() #t.join() #t1.join() #t2.join() # 考虑这三种join位置下的结果? print ("all over %s" %ctime())
Thread实例对象的方法 # isAlive(): 返回线程是否活动的。 # getName(): 返回线程名。 # setName(): 设置线程名。 threading模块提供的一些方法: # threading.currentThread(): 返回当前的线程变量。 # threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。 # threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。