问题:
搭建伪Hadoop集群的时候,运行命令:
hdfs namenode -format
格式化或者说初始化namenode。
然后用命令:
start-dfs.sh
来启动hdfs时,jps发现datanode先是启动了一下,然后就挂掉了,在http://192.168.195.128:50070 (HDFS管理界面)也看不到datanode的信息。
然后去datanode的日志上面看,看到这样的报错:

出错原因:(来自博客https://blog.csdn.net/qq_30136589/article/details/51638069)
hadoop的升级功能需要data-node在它的版本文件里存储一个永久性的clusterID,当datanode启动时会检查并匹配namenode的版本文件里的clusterID,如果两者不匹配,就会出现"Incompatible clusterIDs"的异常。
每次格式化namenode都会生成一个新的clusterID, 如果只格式化了namenode,没有格式化此datanode, 就会出现”java.io.IOException: Incompatible namespaceIDs“异常。
参见官方CCR[HDFS-107]
这就解释了,为什么我第一次是成功的,后面一直都datanode挂掉的情况。
因为第一次成功后,每次再跑hdfs之前我都格式化或者说初始化了hdfs的配置。然后,namenode的clusterId就会清空,在你跑start-dfs.sh的时候,就会重新生成一个clusterId。但你datanode没有初始化噢,就是说datanode里面的那个clusterId还是之前那个,于是就出现了两者不匹配,报错了。
解决方法:
1.在namenode机器上: 找到${dfs.namenode.name.dir}/current/VERSION 里找到clusterID。这个dfs.namenode,name.dir在hdfs-site.xml可以找到你这个路径的真正路径。:

这里的话就是在/home/hadoop/data/name/current下找到VERSION文件,然后里面有个clusterId,找到它复制了:
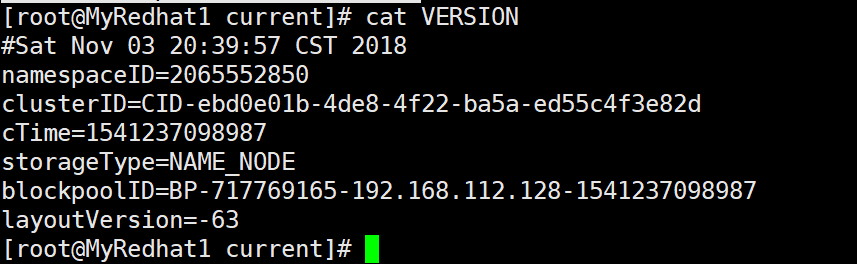
2.在出问题的datanode上: 找到$dfs.datanode.data.dir,这个也是在hdfs-site.xml配置文件可以找到这个路径具体的位置:

像我的机器,就是在/home/hadoop/data/data/current下找到VERSION文件,然后里面也有个clusterId:

然后你要做的就是把(1)中复制的namenode的clusterId覆盖了出问题的datanode的clusterId。
3.在问题节点重新重启你的datanode,也就是重新跑命令:
start-dfs.sh
然后datanode就重新跑起来了。在浏览器上访问那个管理界面也看到datanode了:
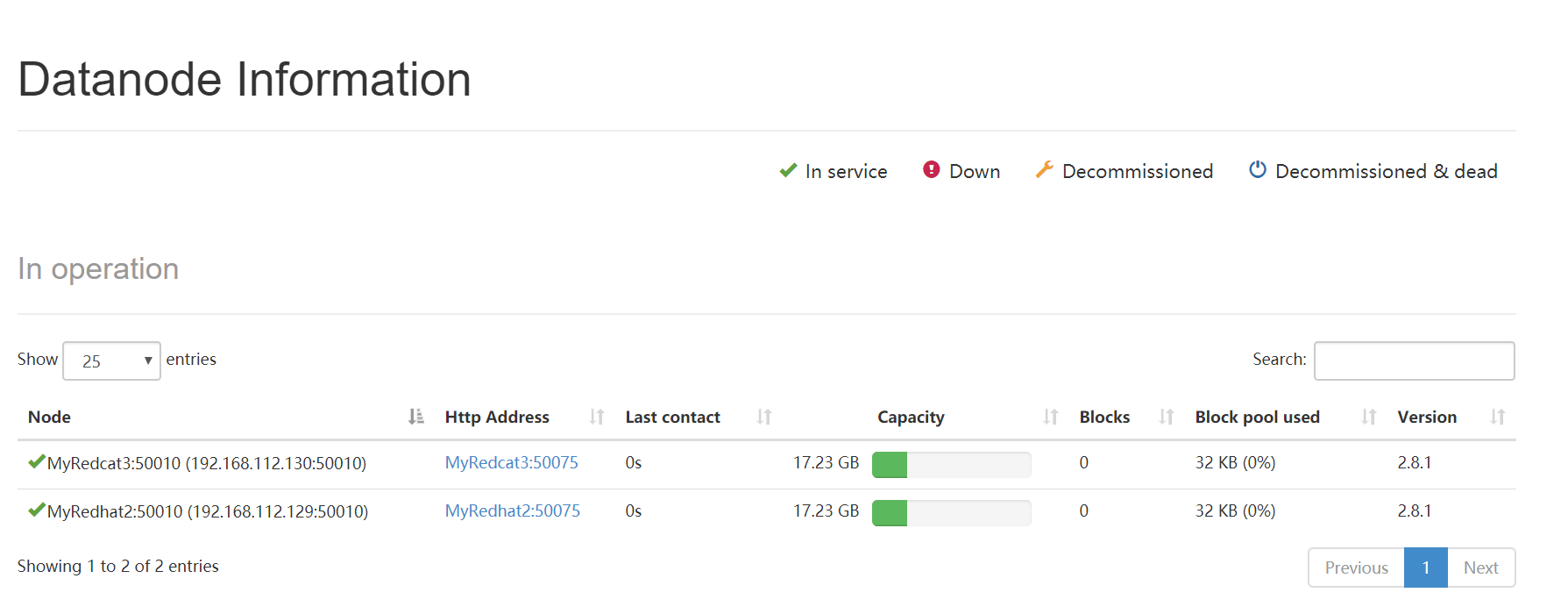
注意:
1.配置完clusterId后不要再hdfs namenode -format格式化或者说初始化namenode了。
2.记得把所有机器的防火墙给关了,不然可能通信上会有所拦截。(反正我一开始没关,然后配好了clusterId在浏览器的Hadoop管理界面上没能看到datanode,一关掉所有机器的防火墙就好了~)