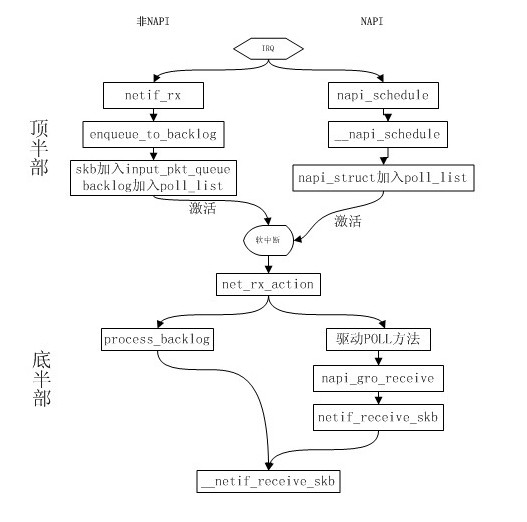
来看下NAPI和非NAPI的区别: (1) 支持NAPI的网卡驱动必须提供轮询方法poll()。 (2) 非NAPI的内核接口为netif_rx(),NAPI的内核接口为napi_schedule()。 (3) 非NAPI使用共享的CPU队列softnet_data->input_pkt_queue,NAPI使用设备内存(或者 设备驱动程序的接收环)。
(4)NAPI方式
数据包到来,第一个数据包产生硬件中断,中断处理程序将设备的napi_struct结构挂在当前cpu的待收包设备链表softnet_data->poll_list中,并触发软中断,软中断执行过程中,遍历softnet_data->poll_list中的所有设备,依次调用其收包函数napi_sturct->poll,处理收包过程;
(5)非NAPI方式
每个数据包到来,都会产生硬件中断,中断处理程序将收到的包放入当前cpu的收包队列softnet_data->input_pkt_queue中,并且将非napi设备对应的虚拟设备napi结构softnet->backlog结构挂在当前cpu的待收包设备链表softnet_data->poll_list中,并触发软中断,软中断处理过程中,会调用backlog的回调处理函数process_backlog,将收包队列input_pkt_queue合并到softdata->process_queue后面,并依次处理该队列中的数据包;
NAPI设备结构
NAPI方式收包流程
中断上半部
以e100为例:
e100_intr(中断处理程序)–>__napi_schedule–>____napi_schedule(将设备对应的napi结构加入到当前cpu的待收包处理队列softnet_data->poll_list中,并触发软中断)
数据包到来,第一包产生中断,中断处理程序得到执行,其中关键步骤为调用__napi_schedule(&nic->napi)将设备对应的napi加入到当前cpu的softnet_data->poll_list中;

1 static irqreturn_t e100_intr(int irq, void *dev_id)
2 {
3 struct net_device *netdev = dev_id;
4 struct nic *nic = netdev_priv(netdev);
5 u8 stat_ack = ioread8(&nic->csr->scb.stat_ack);
6
7 netif_printk(nic, intr, KERN_DEBUG, nic->netdev,
8 "stat_ack = 0x%02X
", stat_ack);
9
10 if (stat_ack == stat_ack_not_ours || /* Not our interrupt */
11 stat_ack == stat_ack_not_present) /* Hardware is ejected */
12 return IRQ_NONE;
13
14 /* Ack interrupt(s) */
15 iowrite8(stat_ack, &nic->csr->scb.stat_ack);
16
17 /* We hit Receive No Resource (RNR); restart RU after cleaning */
18 if (stat_ack & stat_ack_rnr)
19 nic->ru_running = RU_SUSPENDED;
20
21 if (likely(napi_schedule_prep(&nic->napi))) {
22 e100_disable_irq(nic);
23 //将该网络设备加入到sd的poll_list中
24 __napi_schedule(&nic->napi);
25 }
26
27 return IRQ_HANDLED;
28 }
将设备对应的napi结构加入到当前cpu的softnet_data->poll_list中,并触发收包软中断;
1 void __napi_schedule(struct napi_struct *n)
2 {
3 unsigned long flags;
4
5 local_irq_save(flags);
6 ____napi_schedule(this_cpu_ptr(&softnet_data), n);
7 local_irq_restore(flags);
8 }
9
10
11 //添加设备到poll_list,激活接收报文软中断
12 static inline void ____napi_schedule(struct softnet_data *sd,
13 struct napi_struct *napi)
14 {
15 list_add_tail(&napi->poll_list, &sd->poll_list);
16 __raise_softirq_irqoff(NET_RX_SOFTIRQ);
17 }
中断下半部
net_rx_action(软中断收包处理程序)–>napi_poll(执行设备包处理回调napi_struct->poll)
收包软中断处理程序,软中断触发,说明有设备的数据包到达,此时本处理程序遍历softnet_data->poll_list中的待收包设备,并执行napi中的poll调度,关键代码napi_poll(n, &repoll);
1 /* 收包软中断处理程序 */
2 static __latent_entropy void net_rx_action(struct softirq_action *h)
3 {
4 struct softnet_data *sd = this_cpu_ptr(&softnet_data);
5 unsigned long time_limit = jiffies +
6 usecs_to_jiffies(netdev_budget_usecs);
7 int budget = netdev_budget;
8 LIST_HEAD(list);
9 LIST_HEAD(repoll);
10
11 /*
12 将当前cpu的待收包设备列表poll_list合并到list,
13 并且重新初始化poll_list
14 */
15 local_irq_disable();
16 list_splice_init(&sd->poll_list, &list);
17 local_irq_enable();
18
19 /* 遍历列表 */
20 for (;;) {
21 struct napi_struct *n;
22
23 /* 列表为空,则跳出 */
24 if (list_empty(&list)) {
25 if (!sd_has_rps_ipi_waiting(sd) && list_empty(&repoll))
26 goto out;
27 break;
28 }
29
30 /* 取链表头napi节点 */
31 n = list_first_entry(&list, struct napi_struct, poll_list);
32
33 /*
34 调用该节点的poll函数收包 ,
35 若未处理完,则挂到repoll上
36 */
37 budget -= napi_poll(n, &repoll);
38
39 /* If softirq window is exhausted then punt.
40 * Allow this to run for 2 jiffies since which will allow
41 * an average latency of 1.5/HZ.
42 */
43 /* 总配额用尽,或者中断时间窗口用尽,跳出 */
44 if (unlikely(budget <= 0 ||
45 time_after_eq(jiffies, time_limit))) {
46 sd->time_squeeze++;
47 break;
48 }
49 }
50
51 /* 禁用中断 */
52 local_irq_disable();
53
54 /* 整合poll_list链表,包括新产成的,未完成的,未完成的在前 */
55 list_splice_tail_init(&sd->poll_list, &list);
56 list_splice_tail(&repoll, &list);
57 list_splice(&list, &sd->poll_list);
58
59 /* 如果poll_list不为空,则触发下一次收包中断 */
60 if (!list_empty(&sd->poll_list))
61 __raise_softirq_irqoff(NET_RX_SOFTIRQ);
62
63 /* 启用中断 */
64 net_rps_action_and_irq_enable(sd);
65 out:
66 __kfree_skb_flush();
67 }
68
69 struct netdev_adjacent {
70 struct net_device *dev;
71
72 /* upper master flag, there can only be one master device per list */
73 bool master;
74
75 /* counter for the number of times this device was added to us */
76 u16 ref_nr;
77
78 /* private field for the users */
79 void *private;
80
81 struct list_head list;
82 struct rcu_head rcu;
83 };
调用设备对应的napi_struct->poll回调接收数据包,接收数量要根据配额进行限制,关键代码为 work = n->poll(n, weight);
1 static int napi_poll(struct napi_struct *n, struct list_head *repoll)
2 {
3 void *have;
4 int work, weight;
5
6 /* 将napi从链表中拿掉 */
7 list_del_init(&n->poll_list);
8
9 have = netpoll_poll_lock(n);
10
11 /* 读取配额 */
12 weight = n->weight;
13
14 /* This NAPI_STATE_SCHED test is for avoiding a race
15 * with netpoll's poll_napi(). Only the entity which
16 * obtains the lock and sees NAPI_STATE_SCHED set will
17 * actually make the ->poll() call. Therefore we avoid
18 * accidentally calling ->poll() when NAPI is not scheduled.
19 */
20 work = 0;
21
22 /* napi在调度状态 */
23 if (test_bit(NAPI_STATE_SCHED, &n->state)) {
24 /* 执行设备napi的poll回调进行收包 */
25 work = n->poll(n, weight);
26 trace_napi_poll(n, work, weight);
27 }
28
29 WARN_ON_ONCE(work > weight);
30
31 /* 收包数量小于配额,全部读完 */
32 if (likely(work < weight))
33 goto out_unlock;
34
35 /* 以下未读完 */
36
37 /* Drivers must not modify the NAPI state if they
38 * consume the entire weight. In such cases this code
39 * still "owns" the NAPI instance and therefore can
40 * move the instance around on the list at-will.
41 */
42 /* napi在禁用状态 */
43 if (unlikely(napi_disable_pending(n))) {
44 /* 执行完成项 */
45 napi_complete(n);
46 goto out_unlock;
47 }
48
49 if (n->gro_list) {
50 /* flush too old packets
51 * If HZ < 1000, flush all packets.
52 */
53 napi_gro_flush(n, HZ >= 1000);
54 }
55
56 /* Some drivers may have called napi_schedule
57 * prior to exhausting their budget.
58 */
59 if (unlikely(!list_empty(&n->poll_list))) {
60 pr_warn_once("%s: Budget exhausted after napi rescheduled
",
61 n->dev ? n->dev->name : "backlog");
62 goto out_unlock;
63 }
64
65 /* 将为处理完的挂到repoll上 */
66 list_add_tail(&n->poll_list, repoll);
67
68 out_unlock:
69 netpoll_poll_unlock(have);
70
71 return work;
72 }
非NAPI方式收包流程
中断上半部
netif_rx(中断处理程序最终会调用次函数处理收到的包)->netif_rx_internal->enqueue_to_backlog(将收到的包加入到当前cpu的softnet->input_pkt_queue中,并将默认设备backlog加入到softnet_data结构的poll_list链表)
中断处理程序会调用netif_rx来将数据包加入到收包队列中,关键代码:enqueue_to_backlog(skb, get_cpu(), &qtail); 注意数每包都会中断;
1 int netif_rx(struct sk_buff *skb)
2 {
3 trace_netif_rx_entry(skb);
4
5 return netif_rx_internal(skb);
6 }
1 static int netif_rx_internal(struct sk_buff *skb)
2 {
3 int ret;
4
5 net_timestamp_check(netdev_tstamp_prequeue, skb);
6
7 trace_netif_rx(skb);
8
9 #ifdef CONFIG_RPS
10 if (static_key_false(&rps_needed)) {
11 struct rps_dev_flow voidflow, *rflow = &voidflow;
12 int cpu;
13
14 preempt_disable();
15 rcu_read_lock();
16
17 cpu = get_rps_cpu(skb->dev, skb, &rflow);
18 if (cpu < 0)
19 cpu = smp_processor_id();
20
21 ret = enqueue_to_backlog(skb, cpu, &rflow->last_qtail);
22
23 rcu_read_unlock();
24 preempt_enable();
25 } else
26 #endif
27 {
28 unsigned int qtail;
29
30 ret = enqueue_to_backlog(skb, get_cpu(), &qtail);
31 put_cpu();
32 }
33 return ret;
34 }
enqueue_to_backlog将skb加入到当前cpu的softnet_data->input_pkt_queue中,并将softnet_data->backlog结构加入到softnet_data->poll_list链表中,并触发收包软中断;
1 static int enqueue_to_backlog(struct sk_buff *skb, int cpu,
2 unsigned int *qtail)
3 {
4 struct softnet_data *sd;
5 unsigned long flags;
6 unsigned int qlen;
7
8 sd = &per_cpu(softnet_data, cpu);
9
10 local_irq_save(flags);
11
12 rps_lock(sd);
13
14 //检查设备状态
15 if (!netif_running(skb->dev))
16 goto drop;
17
18 //获取队列长度
19 qlen = skb_queue_len(&sd->input_pkt_queue);
20
21 //如果队列未满&& 未达到skb流限制
22 if (qlen <= netdev_max_backlog && !skb_flow_limit(skb, qlen)) {
23
24 //长度不为空,设备已经得到了调度
25 if (qlen) {
26 enqueue:
27 //skb入队
28 __skb_queue_tail(&sd->input_pkt_queue, skb);
29 input_queue_tail_incr_save(sd, qtail);
30 rps_unlock(sd);
31 local_irq_restore(flags);
32 return NET_RX_SUCCESS;
33 }
34
35 /* Schedule NAPI for backlog device
36 * We can use non atomic operation since we own the queue lock
37 */
38 //为空,则设置napi调度
39 if (!__test_and_set_bit(NAPI_STATE_SCHED, &sd->backlog.state)) {
40
41 //alextodo
42 if (!rps_ipi_queued(sd))
43 ____napi_schedule(sd, &sd->backlog);
44 }
45
46 //设置调度之后,入队
47 goto enqueue;
48 }
49
50 //丢包
51 drop:
52 sd->dropped++;
53 rps_unlock(sd);
54
55 local_irq_restore(flags);
56
57 atomic_long_inc(&skb->dev->rx_dropped);
58 kfree_skb(skb);
59 return NET_RX_DROP;
60 }
中断下半部
net_rx_action(软中断收包处理程序)–>napi_poll(执行非napi回调函数process_backlog)
net_rx_action与napi方式相同,这里略过,主要看下其poll回调函数,其将数据包从队列中移出,调用__netif_receive_skb传递到上层,后续介绍传递流程,此处略过:
1 static int process_backlog(struct napi_struct *napi, int quota)
2 {
3 struct softnet_data *sd = container_of(napi, struct softnet_data, backlog);
4 bool again = true;
5 int work = 0;
6
7 /* Check if we have pending ipi, its better to send them now,
8 * not waiting net_rx_action() end.
9 */
10 if (sd_has_rps_ipi_waiting(sd)) {
11 local_irq_disable();
12 net_rps_action_and_irq_enable(sd);
13 }
14
15 //设置设备接收配额
16 napi->weight = dev_rx_weight;
17 while (again) {
18 struct sk_buff *skb;
19
20 //从队列中取skb向上层输入
21 while ((skb = __skb_dequeue(&sd->process_queue))) {
22 rcu_read_lock();
23 __netif_receive_skb(skb);
24 rcu_read_unlock();
25 input_queue_head_incr(sd);
26
27 //如果达到配额,则完成
28 if (++work >= quota)
29 return work;
30
31 }
32
33 local_irq_disable();
34 rps_lock(sd);
35
36 //如果输入队列为空,没有需要处理
37 if (skb_queue_empty(&sd->input_pkt_queue)) {
38 /*
39 * Inline a custom version of __napi_complete().
40 * only current cpu owns and manipulates this napi,
41 * and NAPI_STATE_SCHED is the only possible flag set
42 * on backlog.
43 * We can use a plain write instead of clear_bit(),
44 * and we dont need an smp_mb() memory barrier.
45 */
46
47 //重置状态,处理完毕
48 napi->state = 0;
49 again = false;
50 } else {
51 //合并输入队列到处理队列,继续走循环处理
52 skb_queue_splice_tail_init(&sd->input_pkt_queue,
53 &sd->process_queue);
54 }
55 rps_unlock(sd);
56 local_irq_enable();
57 }
58
59 //返回实际处理的包数
60 return work;
61 }